







Evaluating Coherence in Dialogue Systems using Entailment
coherence 英文中意味着连贯性、条理性。
这篇文章是面向对话应用的,更加关注于对话中上下位的连贯性。
1. 直接转换为 NLI问题,premise-hypothesis问题。——
2. 数据集是自己构造的。——数据集的质量保证上,好像是引入了5个人工检验。
3. 连贯性是通过分级评价得到的,三个级别.,矛盾、中性、一致的。这种分类体系下真的能够较好的发现人类和机器之间的correlation吗?
抓住评测矩阵中的某一项指标做评估,比如一致性、完整性或者其他的性质。
这篇文章评估的是对话系统中的连贯性。
摘要部分
摘要部分,写的ok .
背景:Evaluating open-domain dialogue systems is difficult to the diversity of possible correct answers.
前人的研究:Automatic metrics such as BLEU correlately weak with human annotations,resulting in a significant bias in different models and datasets.
我们的研究:In this paper ,we present interpertable metrics for evaluating topic cohence by making use of distributed sentence representations.
结果:Results show that our metrics can be used as a surrogate for human judgement.
美 /ˈsʌrəɡət/,英 /'sʌrəɡət/
v. 代理, 【法】代替
n. 代理人, 代替, 〈英〉(宗教法庭上)主教代表, 【心】代用人物
adj. 替代的, 代用的
introduction部分
引入部分:
对话系统是什么?对话系统最关键的困难是什么?连贯性是评估对话系统最关键的指标
A challenging task of building dialogue systems lies in evaluating their systems.
什么情况下是好的dialogue? 能够sustain coherence的dialogue是好的对话。
最后1-2段介绍自己的工作:transform the consistency of dialogue system as the NLI question.
NLI 是natural language inference problem
NLI:premise 和hypothesis
NLI的重点是认识到一个假设是否是从一个前提中推断出来的
说明了为神魔要选择NLI? The intuition 这种选择背后的直觉是,人类对话中的话语往往遵循一个一致的、连贯的流程,每个话语都可以从之前的互动中推断出来。
模型部分
核心思路:Given a conversation history H and a generated response r, the goal is to understand the premise-hypothesis pair((H, r)) is entailing.
在表征模型预测结果时,建模的问题类型是分类。
Learn a function to predict one of the three catagorys (含义一致/矛盾/中性) given premise-hypothsis pairs.
定义何为不连贯?何为连贯?
如果一个机器的回答与它以前的话语直接矛盾,或者在整个对话过程中遵循不合逻辑的推理,就可以认为是不连贯的。
数据部分
数据部分采用人工合成的方法。
premise-hypothesis pairs, namely InferConvAI.
模型部分
use the entailment model to predict a score for the generated utterances.
diagonal history is premise and generated response r as hypothesis.
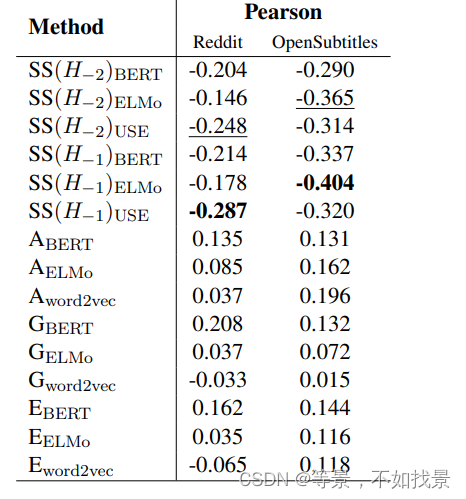
These models were trained on the InferConvAI dataset. During evaluation, we use our test dialogue corpus from Reddit and OpenSubtitles, in which the majority vote of the 4-scale human rating constitutes the labels
评价指标效果
(1)三个baseline
在评价指标效果时,三个baseline,three
textual similarity metrics (Liu et al., 2016) based
on word embeddings: Average (A), Greedy (G),
and Extrema (E)
是将sentence视为Word的集合,忽视了句子词序
(2)semantic similarity,它衡量生成的反应和对话历史中的语料之间的距离。
Universal Sentence Encoder (USE) (Cer et al., 2018)
带下标数字的表示:第几轮对话
Abert表示使用bert得到sentence的embedding,然后取平均作为最终的embedding。
SS应该是在整个句子的前提计算NLI的分值。
A/G/E是在单个Word的基础上,计算NLI的分值。
















 1748
1748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











