






目录
然后接下来,开始在pycharm(对python很好的IDE)里面进行pytorch的学习。
安装python的pytorch
1、首先是配置环境anconda选择2.3.1的版本(真心称赞这个andonda的好用)
为了避免和其他配置环境发生冲突,另外配置了一个python3.8的环境用来安装pytorch。
输入(在使用anconda命令之前,可以先anconda activate base激活环境)
conda --version
conda create -n pytorch python=3.8
conda info --envs输入conda info --envs,即可查看环境设置

然后输入conda activate pytorch进入刚创建好的环境。(注意前面的()是否发生了改变)

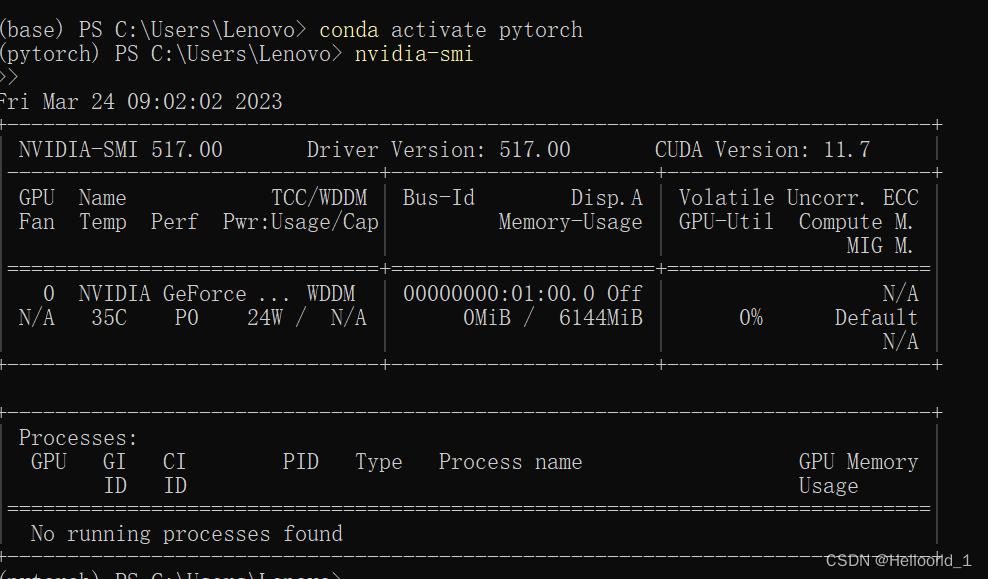
输入nvidia-smi,即可查看可使用的CUDA版本(我的是CUDA Version: 11.7),CUDA是为了使用GPU而安装的,而GPU可以加速运算,节约时间。
PyTorch--安装地址,进去后会看到

选择下面的Previous versions以前的版本,主要是最新版本不一定好
最后我选择了这个进行下载。
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch完成后,显示如下:
使用
conda list
去查询安装包

发现安装成功了!也可以利用
import torch
torch.cuda.is_available()
如果返回True,则说明配置完成了。

记得先python,进入环境,不然会报红色的错误。
另外,如果安装pytorch速度慢可以走镜像,或者挂梯子。
参考镜像如下:
清华:https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/win-64/
更改一哈代码,即可
conda install pytorch torchvision torchaudio –c 镜像地址
Conda install cudatoolkit=版本 –c 镜像地址以上内容,为参考博主的文章链接:
2023最新pytorch安装教程,简单易懂,面向初学者(Anaconda+GPU)_pytorch安装、_时宇羽然的博客-CSDN博客
然后接下来,开始在pycharm(对python很好的IDE)里面进行pytorch的学习。
首先安装了pycharm,具体安装方式,本文不在阐述,很久以前安装的,我也忘了。

设置好环境


查看编译器,说明还没有将之前的pytorch的环境导入进来,那在这里设置一哈
先点击show all进去
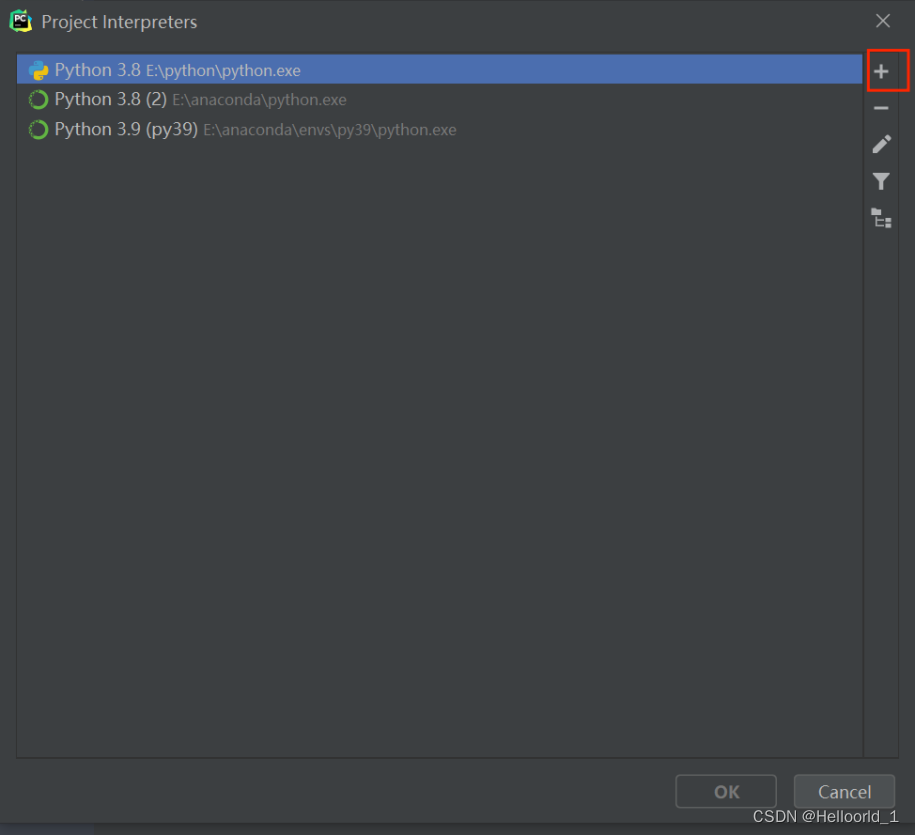
发现并没有我们之前创建的python环境,点击旁边的+号

现在可以看到,pytorch的环境配置进来了

然后再在外面选择好这个编译器,即可使用它的环境。
所有的环境和配置都搭建好了,正式开始学习pytorch
对于pytorch。我是需要用它进行深度学习,来训练模型,然后将模型放入移动端c++中。
大体的流程是训练得到的模型文件(类似pt)转出为onnx文件,然后在C++中导入,并解析onnx文件,进行再推理,然后移植到QT中,打包成exe文件发布。
因此,首先来了解pytorch的常用工具包:
torch :类似 NumPy 的张量库,支持GPU;
torch.autograd :基于 type 的自动区别库,支持 torch 之中的所有可区分张量运行;
torch.nn :为最大化灵活性而设计,与 autograd 深度整合的神经网络库;
torch.optim:与 torch.nn 一起使用的优化包,包含 SGD、RMSProp、LBFGS、Adam 等标准优化方式;
torch.multiprocessing: python 多进程并发,进程之间 torch Tensors 的内存共享;
torch.utils:数据载入器,具有训练器和其他便利功能;
torch.legacy(.nn/.optim) :出于向后兼容性考虑,从 Torch 移植来的 legacy 代码;
写pytorch代码的方法和步骤:
1、编写自己的深度学习网络架构
2、编写要训练的数据的便签和文件路径索引
3、将数据放入搭建好的网络模型中
首先是张量tensor的学习
| 方法名 | 说明 |
| tensor() | 直接构造张量,支持list和numpy数组的索引方式 |
| eye(row,column) | 创建指定行数row&列数column的单位tensor(生成的是单位阵) |
| linspace(start,end,count) | 在[start,end]上创建count个元素的一维tensor |
| logspace(start,end,count) | 在[10s,10e]上创建c个元素的一维tensor |
| ones(size) | 返回指定shape的tensor,元素初始值为1 |
| zeros(size) | 返回指定shape的tensor,元素初始值为0 |
| ones_like(t) | 返回一个tensor,shape与t相同,且元素初始值为1 |
| zeros_like(t) | 返回一个tensor,shape与t相同,且元素初始值为1 |
| arange(s,e,sep) | 在区间[s,e)上以间隔sep生成一个序列张量 |

首先创建一个python文件输入以上代码,产生了如下错误:

发现是自己没有安装numpy,于是去安装了,这里采用的清华镜像去安装。
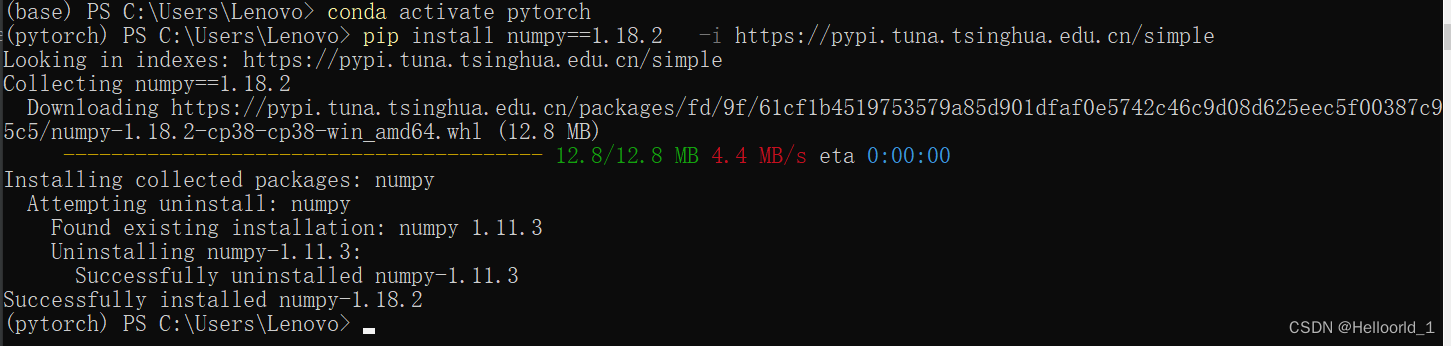
再次运行程序,发现红色部分就消失了。
预备的数学知识
首先是贝叶斯公式:
最大似然估计:
激活函数sigmoid与relu
训练yolov8与yolov5的心得:
设置batch_size有助于加快训练收敛,但是会增大显存的使用,默认batch=-1,那么会在训练过程中自动调整batch_size的大小,如果人为设置的话一定要是2的倍数。
在训练过程里面出现的几个参数:
在训练 YOLOv8 模型时,打印的这些参数提供了关于训练过程的详细信息。以下是每个参数的含义:
- Epoch:指当前训练的轮数(epoch),一轮训练是指整个数据集的一次完整遍历。通常,模型需要在整个数据集上多次遍历(即多个epochs)以进行充分的训练。通常100个回合作起步-如果数据量大的话
- GPU_mem:显示当前GPU内存的使用情况。这对于监控模型训练过程中GPU内存的占用情况非常有用,以确保硬件资源足够且没有达到内存限制。
- box_loss:表示目标框(box)的损失。它用于优化模型预测的目标框位置和大小。较低的值通常意味着模型在预测目标框方面表现较好。值在1-10之间
- cls_loss:表示类别损失。它用于优化模型预测的目标类别。较低的值通常意味着模型能够正确预测目标的类别。在0.1-1之间
- dfl_loss:表示密集采样框(dense sampling)的损失。这可能与目标检测中的某些策略有关,例如密集采样目标框或是在目标框上应用密集的滤波器。
- Instances:表示当前批次中检测到的实例数量。这可以帮助了解模型在单个批次中的性能,并观察随着训练的进行实例数量是否有所增加。看数字会不会不断增长。

















 370
370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











