






 本文介绍了三个非事实性问题解答数据集:WikiHow、其改进版WikiHowQA,以及PubMedQA,聚焦于医学领域的非文本摘要任务。挑战在于这些数据集的抽象性和与传统新闻数据集的区别。
本文介绍了三个非事实性问题解答数据集:WikiHow、其改进版WikiHowQA,以及PubMedQA,聚焦于医学领域的非文本摘要任务。挑战在于这些数据集的抽象性和与传统新闻数据集的区别。
Question Answering Text Summarization Datasets
目前对于自动文本摘要这一块,研究多数采用的是news articles的数据:DUC, Gigaword, New York Times, CNN/Daily Mail等。有兴趣的同学可以去搜索一下。本文主要介绍一些关于Non-factoid QA或更加抽象的数据集。
WikiHow:
| dataset statistics | Value |
|---|---|
| Dataset Size | 230,843 |
| Average Article Length | 579.8 |
| Average Summary Length | 62.1 |
| Vocabulary Size | 556,461 |
- 示例:

- 适用的任务:
non-factoid question answering 中的text summarization; - 挑战:
相比CNN/Daily等数据集,WikiHow数据集更加抽象。新闻类的数据集一般核心内容集中在前三句,因此用lead-3就可以取得相当不错的效果。但却不适用于WikiHow数据集,因此目前还算是比较具有挑战性的数据集;
WikiHowQA:
| dataset statistics | train/dev/test |
|---|---|
| #Questions | 76,687 / 8,000 / 22,354 |
| #QA Pairs | 904,460 / 72,474 / 211,255 |
| #Summaries | 142,063 / 18,909 / 42,624 |
| Avg QLen | 7.20 / 6.84 / 6.69 |
| Avg ALen | 520.87 / 548.26 / 554.66 |
| Avg SLen | 67.38 / 61.84 / 74.42 |
| Avg #CandA | 11.79 / 9.06 / 9.45 |
- 适用任务:
non-factoid question answering 中的answer selection;
non-factoid question answering 中的text summarization; - 挑战:
该数据集的数量还是可以满足深度学习的train要求。具有一定的挑战;
PubMedQA:
- 介绍:
2019年由Jin等人提出来的一个在PubMed网站抓取的数据汇总而来的数据集。详细介绍请参照原始论文; 数据的github. 每条数据由一个问题,一个上下文用于回答问题的,一个对上下问的总结,一个yes/no/maybe,用于评判能否回答相对应的问题。 - 数据结构如下表:
| dataset statistics | PQA-L | PQA-A |
|---|---|---|
| Number of QA pairs | 1.0K | 211.3K |
| yes/no/maybe(%) | 55.2 / 33.8 / 11.0 | 92.8 / 7.2 / 0.0 |
| Avg QLen/ ALen/SLen | 14.4 / 238.9 / 43.2 | 16.3 / 238.0 / 41.0 |
- 示例:

- 适用任务:
non-factoid question answering 中的text summarization;
non-factoid question answering 中的answer selection(三分类yes/no/maybe)
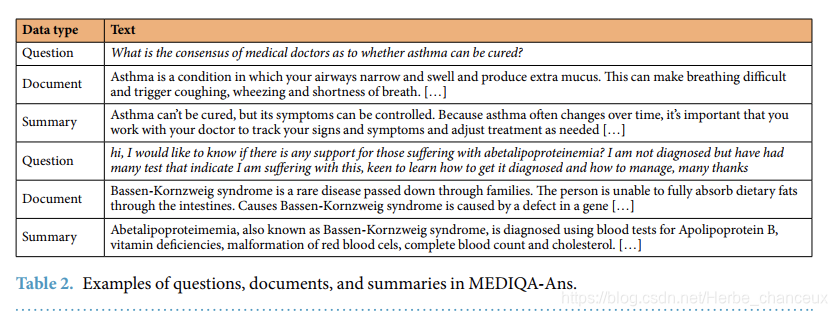
MEDIQA-AnS:

















 1668
1668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









