







文章目录
Abstract
自然语言中的自动文本摘要属于计算机科学中被广泛研究的应用。主要应用到一些需要理解大量信息的背景中。而在医学领域,自动文本摘要可以帮助一些没有医学背景知识的人更好的获得健康的医疗知识。通常情况下呢,为了评价一个摘要算法所生成摘要的质量下,就需要人工的参与,即人工生成的摘要作为一个参考标准。但研究者发现,目前没有能够用来评估健康知识医疗方面的数据。因此,该论文应运而生喽。提出了一个MEDIQA-AnS的数据集,以问题驱动和消费者为中心的一个数据集。
一、Background &Summary
摘要,说白了就是从复杂的信息来源中获取能包含核心信息的简单描述。通常被用来快速理解单一或多种来源内容的一种有力工具。而在医学领域,当人们想要找寻健康的医疗知识时,首先想到的就是互联网。但是互联网大家都了解,需要用户输入关键词或问题,返回一组网页。当用户没有太多的医疗背景知识时,就很难从众多的信息中判断内容的正确性和相关性。说白了,有点类似于**“简单的咳嗽,百度之后,以为自己得了癌症”的感觉~~”**。甚至一些医学专家也很难找到相关的生物医学材料。当然,也有一些可靠、易于理解的医学摘要是存在的。但不同的用于查询输入不同。因此,就需要针对用户查询来构建自动生成的摘要。
为了能开发出能够足够可靠的总结医学知识的摘要算法,研究者就需要对机器生成的摘要进行评价。即需要一种能够以问题为导向,以消费者为中心的数据集。即人工生成的,能够帮助消费者回答其健康问题相关信息的摘要。此时就需要一种数据集能够满足以下三个条件:问题是由没有医学背景知识的人提出来的;包含问题的答案文件;根据消费者提出的健康问题提供易于理解的摘要。为了能满足以上条件,本文提出了一种新的数据集,MEDIQA-AnS,里面包含156个问题,以及这些问题所对应的答案,还有专家所创建的这些答案对应的摘要。
二、Methods
1.Data creation
对于数据的创建,主要用到了MEDIQA
MEDIQA-AnS数据集主要包括:问题,来自网页的全文,从全文中提取的段落,手动创建的摘要。
首先用CHiQA进行网页检索和网页中的信息检索。具体的数据抽取创建,有兴趣的可以去看下这一章节。其实就是利用各种技术将所需的段落从网页中抽取出来。
答案的摘要是由两个主题专家生成的。创建了两种摘要用于后续的任务:extractive summarization,就是从答案中选择文本块作为摘要的;abstractive summarization, 就是有专家根据问题和答案,自己重新构建的摘要。
给大家贴个论文里面的例子。。。

2.Evaluation metrics
ROUGE、BLUEU
3. Data Records
首先论文里面统计了单词和句子的平均数量和标准差(虽然这里我没看懂为啥要统计标准差~~)

table 4 我理解的是,找了两个注释者,然后分别让他们对答案进行extractive摘要和abstractive摘要,然后来计算摘要的ROUGE和BLEU。其实就是为了说明,extractive的摘要主要是从原文中抽取出来的,所以n-grams的重复率高,而abstractive的摘要是由每个注释者根据自己的理解对答案进行了重新组织得到了的,相应的n-grams的重复率就低,这也解释了为什么table4中的abstractive的rouge-pointe相比extractive较低的原因。
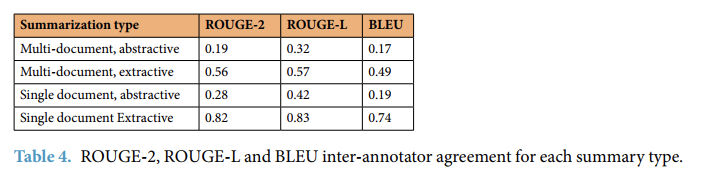
然后又对单一文本和多文本中的abstractive的摘要和extractive的摘要进行了rouge的计算。

4. Experimental benchmarking
作者主要用了6种方法进行了baseline的比较,三种抽取式的,三种深度学习的方法
lead-3: 将一篇文章的前三句话抽取出来作为摘要;
k-random sentences: 从文章中随机抽取出k句话作为摘要;
k-best ROUGE: 拿着每个句子去和question计算rouge,选取得分最高的k句作为摘要;
BiLSTM:利用Bi-LSTM的方法寻找出文章中最相关的句子作为摘要;
PGN:就是一个混合的seq2seq的注意力模型,能够从源文档中复制文本来创建摘要,同时也能生成新的文本;
BART: 基于transformer的编码-解码模型。结合了一个类似于BERT的双向编码器和一个类似于GPT的自回归解码器。在这里,作者首先对模型进行了训练,提高模型理解文本内容的一般能力。然后再在该数据上进行微调。(也就是先让BART获取医学数据集的一般表示,相当于一个二次训练的过程)。
在该论文中,所有的深度学习的模型都是先在BioASQ数据上进行训练,验证集用的是MedInfo23。
下面的table6和table7就是分别将用baseline产生的摘要(生成摘要)和extractive 摘要(参考摘要)、abstractive 摘要(参考摘要)进行rouge计算的结果。


其实可以观察到,与近年的模型相比,rouge-1和bleu在abstractive摘要上是呈现增长趋势的,而rouge-2和rouge-l在extractive摘要上是呈现增长趋势的。主要原因是在于,abstractive摘要的参考摘要本来就短,分母小,导致结果大;rouge-2的增长主要原因就是extractive的摘要本来就是从原始句子中抽取出来的。其实这个分析仔细想一下就能想明白…
最后的table9就是为了证明该数据集对于问题驱动的有效性。因此作者又利用BART,分别将问题加入到输入的前面,做了对比实验。

该数据规模是很小的,所以如果要用,只能依靠同类型的数据集先对其进行训练,然后在测试集上去用该数据集。
有什么不对的地方,欢迎批评指正















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









