







conda的打包环境,自己压缩解压就好了
压缩 tar -zcvf renwolesshel.tar.gz /renwolesshel
好,那怎么安装呢?解压缩
mkdir ~/.conda/envs/fastspeech2
tar -zxvf fastspeech2.tar.gz -C ~/.conda/envs/fastspeech2
那么我弄得docker_export就是,2个G的docker image,还行吧。

果然很危险啊。。。11TB,还剩下1TB,到底怎么可能呢卧槽。
看看我占用了多少吧。。。进入我的文件夹
du -ah --max-depth=1
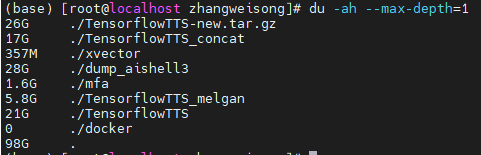
100G了啊。。现在53G了,看学姐的:
![]()
这算磁盘还是内存的?
wow学姐这个文件夹搞得,深切怀疑她搞到好几个TB了。

整个达到了1.8T,最大的文件1.1T,差不多吧。
生成一个容器 sudo docker run -it --name test2 -p 8848:8848 ubuntu /bin/bash
一般来说数据库容器不需要建立目录映射
sudo docker run -p 8847:3306 --name fs2_mysql -e MYSQL_ROOT_PASSWORD=0320 -d mysql:5.7
- –name:容器名,此处命名为
mysql - -e:配置信息,此处配置mysql的root用户的登陆密码
- -p:端口映射,此处映射 主机3306端口 到 容器的3306端口
- -d:后台运行容器,保证在退出终端后容器继续运行
详细mysql在使用Docker搭建MySQL服务 - sablier - 博客园
多规划你就需要端口管理。。使用dockerfile,规划文件等。
这个中断问题如何解决呢?
必然要用-it参数,这样它就不像普通程序一样,运行完就终止了。
- -i: 交互式操作。
- -t: 终端。
要退出终端,直接输入 exit,从start关闭会直接关闭容器,但是exec后就不会了,主要run时要有-it
查看所有的容器命令如下:
sudo docker ps -a使用 docker start 启动一个已停止的容器:
sudo docker start b750bbbcfd88 但是如果没有正在运行的程序的话也会立即关闭,就相当于执行了一个程序而已进入容器
下面演示了使用 docker exec 命令。
sudo docker exec -it 08 /bin/bash 但是必须是正在运行的容器安装conda,安装fs
sudo docker cp ~/TTS_docker/Miniconda3-latest-Linux-x86_64.sh f:Miniconda3-latest-Linux-x86_64.sh
sudo docker exec -it f /bin/bash
chmod 777 Miniconda3-latest-Linux-x86_64.sh
./Miniconda3-latest-Linux-x86_64.sh
把环境装进去,直接硬装,东西都装在root里面了
sudo docker cp ~/TTS_docker/fastspeech2.tar.gz f:/fastspeech2.tar.gz
tar -zxvf fastspeech2.tar.gz
导出容器用export就行,打包成镜像最好
sudo docker export f > ~/TTS_docker/fastspeech2_docker_export.tardocker build与docker run的区别是什么?docker build只是,构建这个镜像,并放到镜像仓库中,run是构建容器,并运行
Docker Compose 通过一个声明式的配置文件描述整个应用,从而使用一条命令完成部署。Docker Compose 会使用目录名(counter-app)作为项目名称,Docker Compose 会将所有的资源名称中加上前缀 counter-app_。
Docker Compose 会将项目名称(counter-app)和 Compose 文件中定义的资源名称(web-fe)连起来,作为新构建的镜像的名称。Docker Compose 部署的所有资源的名称都会遵循这一规范。
如下命令列出了两个容器。每个容器的名称都以项目名称(所在目录名称)为前缀。此外,它们还都以一个数字为后缀用于标识容器实例序号,因为 Docker Compose 允许扩缩容。
为什么找不到这个文件?而且还需要很长的时间。。。好慢啊。。。其实也不是很有必要啦。
命名规则原来如此啊。。。container_name可以指定名称,
- 一个service可以拥有一个或多个container。
- container是docker的概念,因此我们在docker域里面,处理的是container。
- service是docker-compose概念, 因此我们在docker-compose域里面,才处理的是service。(当然docker-compose也能处理container)。
docker-compose start/stop处理的service name,而不是container name。
用docker就无法在后台运行。。。天哪。。。
按理说我这个需求是不符合常理的,容器就是运行一个程序,运行结束后关闭,就是如此,我现在却要求它,emmm,不能关闭。想想办法吧。
docker容器运行必须有一个前台进程, 如果没有前台进程执行,容器认为空闲,就会自行退出,这个是 docker 的机制问题。
网上有很多介绍,就是起一个死循环进程,让他不停的循环下去,前台永远有进程执行,那么容器就不会退出了,但是你进入,还是一个新shell。
添加-it 参数交互运行
添加-d 参数后台运行,但这是run的里面,我现在是docker-compose,emmmm,添加循环貌似是一个好的选择。
一旦构建成功就会进入运行,这时候ctrl+c退出就可以了。
看来不行,得加上-u,可以,太棒了
不行啊,github还是慢啊。。。实在是太可怜了,买个。
NetworkManager和/etc/init.d/networking
在ubuntu系统中,我们分为ubuntu Server版本和ubuntu Desktop版本,在 Ubuntu Server中,默认使用interfaces管理网络,而在ubuntu Desktop中,系统默认安装NetworkManager,从而使用NetworkManager管理网络服务。
啊,我明白了,ping不动的。。。是上层的东西。没用。。。啊啊啊
sudo /etc/init.d/nscd restart只对 github.com
git config --global http.https://github.com.proxy socks5://127.0.0.1:1090
取消代理
git config --global --unset http.https://github.com.proxy
git clone https://github.com.cnpmjs.org/kaldi-asr/kaldi.git kaldi --origin upstream完全没问题了。好活开整!也不赖,我只要改改就行了!
EXPOSE 指令是声明运行时容器提供服务端口,这只是一个声明,在运行时并不会因为这个声明应用就会开启这个端口的服务。在 Dockerfile 中写入这样的声明有两个好处,一个是帮助镜像使用者理解这个镜像服务的守护端口,以方便配置映射;另一个用处则是在运行时使用随机端口映射时,也就是 docker run -P时,会自动随机映射 EXPOSE 的端口。
要将 EXPOSE 和在运行时使用 -p <宿主端口>:<容器端口> 区分开来。-p,是映射宿主端口和容器端口,换句话说,就是将容器的对应端口服务公开给外界访问,而 EXPOSE 仅仅是声明容器打算使用什么端口而已,并不会自动在宿主进行端口映射。
docker里又不行了,映射了也没用。。。
Error starting userland proxy: listen tcp4 0.0.0.0:1090: bind: address already in use
根本就不能用,但是走代理应该没问题。
没法用啊。。。只能把vpn放到容器里面了。。。
成功了。
在/opt/kaldi
你必须在根目录解压fastspeech2
pip3 --no-cache-dir install torch -i https://pypi.tuna.tsinghua.edu.cn/simple/
cd /opt/kaldi/egs/xmuspeech/sre/subtools
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
容器打包成镜像,在脚本里。
bash subtools/makeFeatures.sh enroll fbank conf/fbank_41_16k.conf/opt/kaldi/egs/xmuspeech/sre/wave
为啥二者不匹配呢?
subtools/computeVad.sh enroll conf/vad-5.0.conf我吐了。。。好好琢磨一下这个subtools的性状
找到她那原语句了,跑跑她的语音
/work/kaldi/egs/xmuspeech/aishell3_test/
反正结果就是出现一个exp/features/fbank/这么一个目录。
VoxCeleb是一个视听数据集,由从上传到YouTube的采访视频中提取的人类语音短片组成。
VoxCeleb1包含超过100,000个针对1,251个名人的话语,这些话语是从上传到YouTube的视频中提取的。
肝不动了肝不动了。。。只能缓缓,做前后端吧。这里留出来一个接口就足够了。
from pydub import AudioSegment
def mp3_to_wav(mp3_path, wav_path):
song = AudioSegment.from_mp3(mp3_path)
song.export(wav_path, format="wav")
if __name__ == '__main__':
mp3_to_wav('audio.mp3',"audio.wav")
pip install pydub -i Simple Index
可算TMD成功了。。。
接下来,哼哼。就比较硬核了,现在先告一段落,我要重新研究了。
这个文件夹怎么准备啊。。。emmm,放在哪里比较好?难道都放到static里面吗?算了新开一个文件夹,叫mid_res,存放中间结果。
哇那真的太简单了,比我预料的还要简单。
使用system执行多条命令
- 为了保证system执行多条命令可以成功,多条命令需要在同一个子进程中运行;
import os
os.system('cd /usr/local && mkdir aaa.txt')
# 或者
os.system('cd /usr/local ; mkdir aaa.txt')bash subtools/makeFeatures.sh --nj 1 /work/kaldi/egs/xmuspeech/aishell3_test/cyxData/CYX210311prep/ fbank conf/fbank_41_16k.conf
bash subtools/computeVad.sh --nj 1 /work/kaldi/egs/xmuspeech/aishell3_test/cyxData/CYX210311prep/ conf/vad-5.0.conf
VAD,也就是语音端点检测技术,是Voice Activity Detection的缩写。这个技术的主要任务是从带有噪声的语音中准确的定位出语音的开始和结束点,因为语音中含有很长的静音,也就是把静音和实际语音分离开来,因为是语音数据的原始处理,所以VAD是语音信号处理过程的关键技术之一。
好吧又出现错误了,好事多磨啊。。。老子不干了。
说实话这个第一个脚本产出的路径是不变的。。
cd /work/kaldi/egs/xmuspeech/sre_zws/
conda activate subtools1
模型的初始化就放到最开始就好了。
这个docker卡住好像是系统性的问题啊。。。
那么现在的话,重新载入到django里面试一试。
现在的话,要明白那个脚本
1. 这个点就好像,emmm,明白了,就是bash。
2. 这个path.sh实际上就是设定路径的。
3. 在 shell 中执行程序时,shell 会提供一组环境变量。export 可新增,修改或删除环境变量,供后续执行的程序使用。export 的效力仅限于该次登陆操作。就是设定了几个全局变量而已。
4.
我们知道,Bash 执行脚本的时候,会创建一个新的 Shell。
$ bash script.sh
上面代码中,script.sh是在一个新的 Shell 里面执行。这个 Shell 就是脚本的执行环境,Bash 默认给定了这个环境的各种参数。set命令用来修改 Shell 环境的运行参数,也就是可以定制环境。执行脚本的时候,如果遇到不存在的变量,Bash 默认忽略它。输出了一个空行。set -u就用来改变这种行为。脚本在头部加上它,遇到不存在的变量就会报错,并停止执行。set一般用于脚本安全。
set命令的上面这四个参数,一般都放在一起使用。
# 写法一 set -euxo pipefail # 写法二 set -eux set -o pipefail
这两种写法建议放在所有 Bash 脚本的头部。
set -e从根本上解决了这个问题,它使得脚本只要发生错误,就终止执行。
我感觉这个脚本有大问题啊。。。这问题超大。。。
aug为频谱augmentation
我听过的最好的声音就在/data/OB/TensorFlowTTS-master-new/TensorflowTTS-work-modify/predictions/wavs/pb_model/这里了。
好TM奇怪啊。。。就好像用的不是指定的模型一样。。。
感觉像是环境的问题,毕竟所有的都不能用了。
sh环境能用,但python环境貌似不能用了。

无论如何,这个东西怎么来的?为什么我就添加不成功?
我TM把函数直接删掉了,它还能跑。。。说明确实引用的不是我的模型。。。但怎么可能呢?它怎么调用的呢?
哦因为还有当前的这个目录。
那我得看看训练的有没有正确训练!我丢你大爷的,train也不是这个模型,应该是环境改了。。。那么这到底是怎么回事呢?环境变量就那么几个,它是怎么实现连接到别处呢?
不仅说引用了她的,而且我的还被顶替了。。。这个问题简直了。。。
不行,跟那个没关系卧槽。都TM好像被重定向了。。。这可是真的神奇。。。现在的症状就好像是,sys.path的/data/zhangweisong/TensorflowTTS_concat_big512/被换成别的
Python搜索模块的路径:
1)、程序的主目录
2)、PTYHONPATH目录(如果已经进行了设置)
3)、标准连接库目录(一般在/usr/local/lib/python2.X/)
4)、任何的.pth文件的内容(如果存在的话).新功能,允许用户把有效果的目录添加到模块搜索路径中去
.pth后缀的文本文件中一行一行的地列出目录。
这四个组建组合起来就变成了sys.path了,
>>> import sys
>>> sys.path
导入时,Python会自动由左到右搜索这个列表中每个目录。放到开头,那成功了呀。成功了呀。
接着做做加到encode之前吧。。。
不见得删除哈。它encoder和decoder部分都有speaker id加入的。。。
在encoder之前,而不是encoder之中。从另外一个方面来说,input_id就是文本信息吗?应该是的。
这个embedings还蛮重要,就是这里了!或者在这下面也说不定。它继承自TFFastSpeechEmbeddings,这只是一个layer。它的功能一是加上position embedded,二是加上speaker id。
在这里面加不是好选择,在后面加上吧。我只需要关心一下config就好了。encoder的输入要改一下。
这是挨个涨的,就好像,这个embeds找不到长度,而且encoder也不知道输入长度,难道是等长的?
wtf?成功了?哦明白了,八成用的是同一个参数。
果然呐,操。我觉得应该没问题了。
我发现,对于inference,有时候是一个一个的,有时候是一batch一batch的。。。
说实话这感觉很微妙。。。
接着搞,如果要好好搞的话,只需要
一个模型,两个fs.py,一个config,修改一下py文件,ok
啊哈,不行了,因为xvector不行了。明天再说吧。。。
没问题了,现在是好的melgan
一个模型,一个config,没了。。。
/sre_zws/data/myData/tone.wav
改成one_dragon.sh,一条龙。。。
post_process.py,提取,转移xvector
sre_zws/exp/ftdnn_xv_train_4kh_aug_warmR_fbank_41_16k_pytorch/far_epoch_18/mydata/
far_epoch_18/mydata/xvector.1.ark:5
看来上传的文件不行啊。。。
加油,快赢了。
我需要:模型,config,两个文件,注意改一下
上传,他妈的卡住了。。。不行,遭不住。。。
基本做完了,完成度比较高,真是有点爱不释手啊。。。

















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









