






基于卷积神经网络(CNN)的手写数字识别
matlab代码,要求2018版本及以上






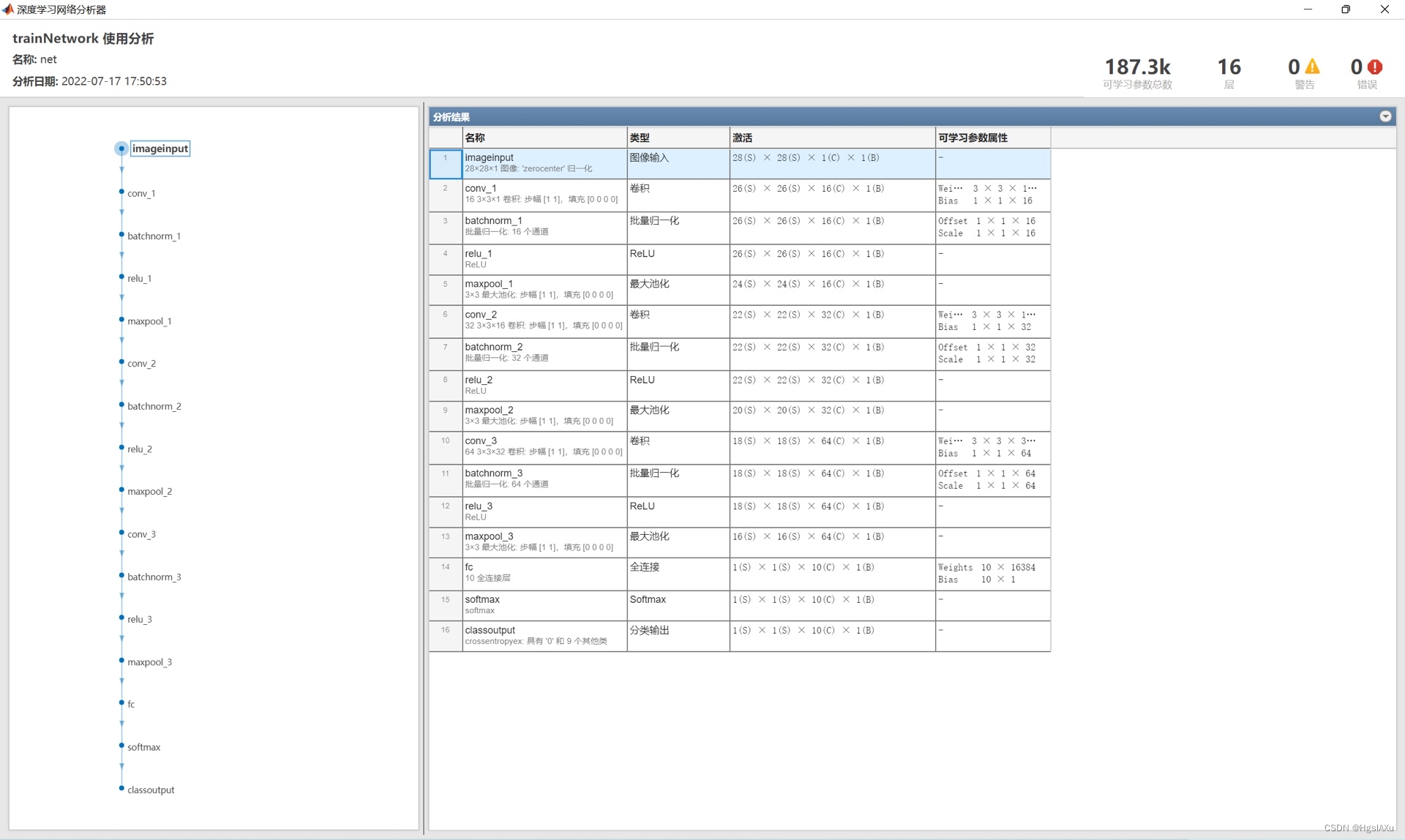
基于卷积神经网络(CNN)的手写数字识别一直是深度学习领域的经典应用之一。近年来,在深度学习算法不断发展的趋势下,手写数字识别的准确度得到了巨大的提高。而本文将要讨论的是关于基于卷积神经网络的手写数字识别的matlab实现,要求2018版本及以上。
首先,我们需要了解卷积神经网络在图像识别中的作用。卷积神经网络通常由输入层、卷积层、池化层、全连接层和输出层组成。其中,输入层接收到原始图像数据,卷积层使用一系列滤波器进行特征提取,池化层则将提取出的特征进行采样,最后通过全连接层将特征进行分类并输出结果。通过卷积神经网络可以将输入的手写数字图像经过一系列的处理后,输出对应的数字结果。
在matlab中实现基于卷积神经网络的手写数字识别,我们首先需要准备好用于训练和测试的手写数字图像数据集。在这里,我们可以使用MNIST数据集,它包含了60000张训练图片和10000张测试图片,每张图片的大小为28x28像素。可以通过matlab实现数据集导入和预处理,并将其转换为适合神经网络训练的形式。
接着,我们需要定义好卷积神经网络的结构。在matlab中,使用了深度学习工具箱,可以轻松地创建我们所需的卷积神经网络结构。针对手写数字识别,我们可以采用经典的LeNet-5结构,该结构包含2个卷积层、2个池化层和3个全连接层,是一个相对简单的结构。在实践过程中,我们可以根据实际需求来进行结构设计和调整,以达到更好的效果。
在网络结构定义完成后,我们需要进行模型训练。在matlab中,可以使用trainNetwork函数来进行网络的训练。在训练过程中,我们需要注意参数的选择和调整,如学习率、批次大小等。同时,需要关注到过拟合的问题,并采取相应的措施,如加入正则化项等。
最后,我们需要进行测试并评估模型的准确度。在matlab中,使用classify函数可以对输入的手写数字图像进行分类,并输出对应的数字结果。在测试过程中,可以利用准确率等指标来评估模型的性能,并通过可视化的方式展示结果。
综上所述,基于卷积神经网络的手写数字识别在matlab中的实现,需要注意到数据集的处理、网络结构的定义、模型训练的调整和参数选择,以及模型的评估和可视化展示。只有在这些方面综合考虑和实践,才能获得精确度和泛化性能都比较好的手写数字识别模型,从而为相关应用提供更好的支持和服务。
相关代码,程序地址:http://lanzouw.top/643978611112.html















 2545
2545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









