






三天疯狂的用心整理(两天晚饭没吃o(╥﹏╥)o),请大数据将我推向更多需要的朋友们吧!!!!!
我在下面这段代码种实现了一个手写数字识别的深度学习模型。首先,通过加载MNIST数据集,获取了手写数字的训练集和测试集。接着,对数据集进行了可视化展示,包括显示训练集中的前9个样本和绘制训练集中手写数字类别的分布直方图。随后,对训练集和测试集的图像数据进行了形状调整,以适应卷积神经网络的输入格式。建立了一个包括卷积层、池化层、全连接层等的卷积神经网络模型,并进行了训练。在训练过程中,使用了数据增强技术和模型检查点,最终评估了模型在测试集上的性能。最后,通过可视化展示了模型在测试集上正确分类和错误分类的一些样本,以便直观了解模型的性能。整体而言,这段代码实现了一个完整的手写数字识别任务,并提供了训练、评估和可视化的步骤。
!!!最后的最后!!!求关注,不迷路
在计算机视觉领域,手写数字识别是一个经典而重要的问题,深度学习在解决这类问题上取得了显著的成就。今天我将会带大家来实现一个简单的手写数字识别,在其中我会使用Keras深度学习库,并以MNIST数据集为基础。让我们来逐步解释并深入了解其中的关键概念。
目录
三天疯狂的用心整理(两天晚饭没吃o(╥﹏╥)o),请大数据将我推向更多需要的朋友们吧!!!!!
第三部分:调整训练集和测试集的图像数据形状,将其转换为适用于卷积神经网络的格式
第十部分:通过图像可视化展示模型在测试集上错误分类的一些样本
第一部分:准备手写数字识别任务的数据集
首先,我在代码导入了必要的库和模块,包括NumPy、Seaborn、Matplotlib以及Keras。这些库用于数据处理、可视化和深度学习模型的构建。Keras是一个高级神经网络API,它能够简化深度学习模型的搭建过程。
接下来,代码设置了图形的参数,主要是Matplotlib的图形大小。这有助于在可视化过程中控制图像的呈现尺寸。
在定义了训练参数后,代码通过mnist.load_data()加载了MNIST数据集。这个数据集包含了以28x28像素为大小的手写数字图像,以及对应的标签。训练集和测试集分别由(X_train, y_train)和(X_test, y_test)表示。
通过打印X_train和X_test的形状,我们可以了解数据集中图像的数量和尺寸。这是深度学习模型构建的关键步骤,因为模型的输入形状必须与数据集的形状相匹配。
接下来我向大家展示一下第一部分的代码,这段代码的目的是为了确保数据加载正确,并为接下来的步骤做好准备。在实际的手写数字识别应用中,数据集的了解和预处理是确保模型性能的关键步骤。
第一部分代码
#手写数字识别
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize']=(7,7)
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.utils import np_utils
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPool2D
from keras.layers.normalization import BatchNormalization
epochs = 20
input_shape = (28,28,1)
nb_classes = 10
(X_train,y_train),(X_test,y_test) = mnist.load_data()
print('X_train shape:',X_train.shape)
print('X_test shape:',X_test.shape)第一部分运行结果
Using TensorFlow backend.
X_train shape: (60000, 28, 28)
X_test shape: (10000, 28, 28)第二部分:显示训练集中前9个手写数字图像
然后在第二部分中我通过使用Matplotlib库的子图功能,迭代显示MNIST数据集中前9个手写数字图像。每个子图以灰度图像形式展示,并带有相应的类别标签作为标题,以便直观了解数据集的样本内容和标签分布。这种可视化方法有助于初步检查数据的正确加载和确保图像与标签的匹配关系。总的来说就是通过循环迭代,将MNIST数据集中前9个图像以3x3的网格形式显示在Matplotlib的子图中,每个子图的标题表示相应图像的类别标签,而图像本身以灰度图像形式呈现,保留了原始像素的细节。
第二部分代码
for i in range(9):
plt.subplot(3,3,i+1)
plt.imshow(X_train[i],cmap='gray',interpolation='none') #interpolation='none'不需要插值
plt.title('Class {}'.format(y_train[i])) #类别标签第二部分运行结果

第三部分:调整训练集和测试集的图像数据形状,将其转换为适用于卷积神经网络的格式
在第三部分中,我的主要目的是确保MNIST数据集中的图像数据在输入深度学习模型之前具有正确的形状。深度学习模型通常期望输入数据的形状符合其设计,因此这种数据预处理是确保模型能够正确处理图像数据的重要步骤。在这里,通过添加一个通道维度,数据的形状被调整为四维数组,以满足卷积神经网络等模型的输入要求。
第三部分代码
X_train = X_train.reshape(X_train.shape[0],28,28,1)
X_test = X_test.reshape(X_test.shape[0],28,28,1)
print('X_train shape:',X_train.shape)
print('X_test shape:',X_test.shape)第三部分运行结果
X_train shape: (60000, 28, 28, 1)
X_test shape: (10000, 28, 28, 1)第四部分
4.1 绘制训练集中手写数字的类别分布
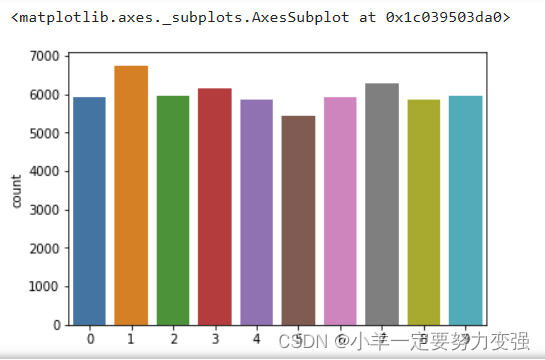
然后我使用Seaborn库的countplot函数,绘制了训练集中手写数字的类别分布,这样可以可视化训练集中各个手写数字类别的分布情况,有助于了解数据集的类别平衡或不平衡。在手写数字识别问题中,良好的类别分布有助于训练模型更好地泛化到各个数字。通过观察直方图,可以判断是否有某些数字的样本数量较少或过多,从而在训练模型前对数据集进行适当的处理或调整。
4.2 打印训练集标签 y_train 的形状信息
然后我打印训练集标签 y_train 的形状信息,这样做的目的是为了输出训练集标签的形状信息,以便开发者了解标签数组的维度和大小。这对于确保标签与训练数据相匹配以及正确构建深度学习模型非常重要。
4.3 将训练集和测试集的类别标签进行独热编码
在这一部分中我使用 np_utils.to_categorical 函数将训练集和测试集的类别标签进行独热编码。将原始的类别标签转换为独热编码,以便在深度学习模型中进行多类别分类任务。独热编码的好处在于,它将类别信息表示为二进制向量,每个类别对应一个唯一的位置,有助于模型更好地理解类别之间的关系。
第四部分代码
4.1 类别分布代码
sns.countplot(y_train)4.2 形状信息代码
print('y_train:',y_train.shape)4.3 转换独热编码
Y_train = np_utils.to_categorical(y_train,nb_classes) #转换成独热编码
Y_test = np_utils.to_categorical(y_test,nb_classes)
print('Y_train:',Y_train.shape)第四部分运行结果
4.1类别分类结果
4.2 打印信息结果
y_train: (60000,)4.3 转换成独热编码
Y_train: (60000, 10)第五部分:定义一个卷积神经网络
首先,我创建一个顺序模型,该模型允许按照顺序一层一层地添加神经网络层,然后通过 add 方法,逐层添加卷积层、ReLU激活函数、He正态分布初始化权重、池化层和Dropout层。这些层的组合有助于提取图像中的特征并减少过拟合。将卷积层的输出展平成一维数组,为全连接层做准备。添加全连接层、ReLU激活函数、批量归一化层和Dropout层,有助于更好地训练和泛化。使用交叉熵作为损失函数,Adam优化器进行模型编译,并设置准确率作为评估指标。
总体而言,我在下面这段代码中定义了一个卷积神经网络,采用了卷积层、池化层、全连接层、批量归一化等技术,旨在用于手写数字识别任务。模型的搭建结构和参数配置通过 model.summary() 可以清晰地查看。
第五部分代码
model = Sequential()
model.add(Conv2D(32,kernel_size=(3,3),activation='relu',kernel_initializer='he_normal',input_shape=input_shape)) # he正态分布初始化方法
model.add(Conv2D(32,kernel_size=(3,3),activation='relu',kernel_initializer='he_normal'))
model.add(MaxPool2D(2,2))
model.add(Dropout(0.2))
model.add(Conv2D(64,kernel_size=(3,3),activation='relu',kernel_initializer='he_normal',padding='same')) #padding='same':输出矩阵大小与输入一样
model.add(Conv2D(64,kernel_size=(3,3),activation='relu',kernel_initializer='he_normal',padding='same'))
model.add(MaxPool2D(2,2))
model.add(Dropout(0.25))
model.add(Conv2D(128,kernel_size=(3,3),activation='relu',kernel_initializer='he_normal',padding='same'))
model.add(Conv2D(128,kernel_size=(3,3),activation='relu',kernel_initializer='he_normal',padding='same'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128,activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(nb_classes,activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
model.summary()第五部分运行结果

第六部分:模型训练
在训练模型时,我使用 ImageDataGenerator 对训练数据进行数据增强,并通过 ModelCheckpoint 回调保存在验证集上取得最佳性能的模型。
首先我创建了一个 ImageDataGenerator 对象 datagen,并设置了 featurewise_center 为 True 和 featurewise_std_normalization 为 True。这两个参数表示对输入的图片进行归一化,使其均值为零,方差为标准方差。然后使用 datagen.fit 方法对训练集的数据进行归一化,计算训练集的均值和标准方差,然后用于后续训练过程中的数据增强。
设置了模型保存的文件路径为 'model.hdf5',并使用 ModelCheckpoint 回调,以监视验证集的准确率 (val_acc),仅保存在验证集上取得最佳性能的模型。
利用 fit_generator 方法进行模型的训练。这里使用了数据生成器 datagen.flow,对训练数据进行批量生成,每次生成1000个样本。steps_per_epoch 表示每个训练轮次需要的步数,而 validation_steps 表示每个验证轮次需要的步数。模型的训练过程中通过 callbacks 参数使用了之前设置的 ModelCheckpoint 回调,以在每次验证集准确率提高时保存模型。
总体而言,我通过数据增强提高了模型的泛化能力,并在训练过程中使用 ModelCheckpoint 保存了在验证集上表现最好的模型。这有助于在训练过程中避免过拟合,同时确保了在训练结束后可以使用效果最好的模型进行推断。
第六部分代码
datagen = ImageDataGenerator(featurewise_center=True,featurewise_std_normalization=True)
# ImageDataGenerator()是keras.preprocessing.image模块中的图片生成器,同时也可以在batch中对数据进行增强,
# 扩充数据集大小,增强模型的泛化能力。比如进行旋转,变形,归一化等等。
# 数据归一化:均值为零,方差为标准方差
# featurewise_center: Boolean. 对输入的图片每个通道减去每个通道对应均值。
#https://www.jianshu.com/p/d23b5994db64
datagen.fit(X_train)
#保存效果最好的模型
filepath = 'model.hdf5'
from keras.callbacks import ModelCheckpoint
checkpointer = ModelCheckpoint(filepath,monitor='val_acc',save_best_only=True,mode='max')
h = model.fit_generator(datagen.flow(X_train,Y_train,batch_size=1000),
steps_per_epoch=len(X_train)/1000,epochs=epochs,
validation_data=datagen.flow(X_test,Y_test,batch_size=len(X_test)),
validation_steps=1,callbacks=[checkpointer])第六部分运行结果

第七部分:绘制准确率曲线
在这部分我通过绘制训练过程中的准确率曲线,显示训练集和验证集在每个训练周期的准确率变化。
首先从训练历史数据 history 中提取训练集和验证集的准确率以及损失值,生成一个横轴的范围,表示训练过程中的每个训练周期。然后我使用 Matplotlib 绘制训练集准确率和验证集准确率曲线。'bo' 表示使用蓝色的圆点标记训练集准确率,'b' 表示使用蓝色的线表示验证集准确率。
通过可视化展示训练过程中模型的准确率变化情况,以便分析模型的训练效果和是否存在过拟合或欠拟合的情况。通过观察图表,可以判断模型是否在训练过程中逐渐收敛,以及是否在验证集上表现良好。
第七部分代码
accuracy = history['acc']
val_accuracy = history['val_acc']
loss = history['loss']
val_loss = history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs,accuracy,'bo',label='Training Accuracy')
plt.plot(epochs,val_accuracy,'b',label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.show()第七部分运行结果

第八部分:评估学习模型在测试集上的性能
在这一部分中我使用了 model.evaluate 方法来评估模型在测试集上的性能,输出测试集上的损失值和准确率。这一部分的目的是提供模型在独立的测试集上的性能评估。损失值衡量了模型预测的输出与真实标签之间的差异,而准确率则表示模型在测试集上正确分类样本的比例。通过这些指标,可以更全面地了解模型的性能,评估其在新数据上的泛化能力。
首先我使用模型的 evaluate 方法对测试集进行评估。该方法返回一个包含损失值和指标值(在这里是准确率)的列表。然后打印测试集上的损失值和准确率。score[0] 表示测试集上的损失值,而 score[1] 表示测试集上的准确率。
第八部分代码
score = model.evaluate(X_test,Y_test)
print("Test score:",score[0])
print("Test accuracy:",score[1])第八部分运行结果

第九部分:图像可视化展示模型在测试集上正确分类的一些样本
我在这一部分的目的是在测试集上对模型的预测结果进行可视化,显示正确分类的一些样本,通过图像可视化展示模型在测试集上正确分类的一些样本,有助于直观了解模型的性能。
在这之前,我首先使用模型的 predict_classes 方法对测试集进行预测,得到预测的类别,然后找到正确分类和错误分类的样本索引,通过比较预测类别和真实类别,找到模型正确分类和错误分类的样本索引,最后使用 Matplotlib 绘制一个3x3的子图,显示模型正确分类的前9个样本。每个子图包含一张图像,以灰度图像形式展示,标题显示了模型的预测类别和真实类别。
第九部分代码
predicted_classes = model.predict_classes(X_test)
correct_indices = np.nonzero(predicted_classes == y_test)[0]
incorrect_indices = np.nonzero(predicted_classes != y_test)[0]
plt.figure()
for i,correct in enumerate(correct_indices[:9]):
plt.subplot(3,3,i+1)
plt.imshow(X_test[correct].reshape(28,28),cmap='gray',interpolation='none')
plt.title("Predicted {},Class {}".format(predicted_classes[correct],y_test[correct]))第九部分运行结果

第十部分:通过图像可视化展示模型在测试集上错误分类的一些样本
我在这一部分中考虑的是通过图像可视化展示模型在测试集上错误分类的一些样本,以便直观了解模型在某些样本上可能存在的分类错误。
第十部分代码:
plt.figure()
for i,incorrect in enumerate(incorrect_indices[:9]):
plt.subplot(3,3,i+1)
plt.imshow(X_test[incorrect].reshape(28,28),cmap='gray',interpolation='none')
plt.title("Predicted {},Class {}".format(predicted_classes[incorrect],y_test[incorrect]))第十部分运行结果



















 2379
2379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











