







 本文总结了阿里天池O2O优惠券使用预测项目的实践经验,包括数据集分析、特征工程和模型选择。通过构建历史行为特征、用户与商户、优惠券的交叉特征,使用Xgboost模型,取得了0.74的AUC成绩。优化方向包括更精细的特征处理和模型融合。
本文总结了阿里天池O2O优惠券使用预测项目的实践经验,包括数据集分析、特征工程和模型选择。通过构建历史行为特征、用户与商户、优惠券的交叉特征,使用Xgboost模型,取得了0.74的AUC成绩。优化方向包括更精细的特征处理和模型融合。
O2O优惠券使用预测笔记
前言
笔者希望通过本篇文章总结阿里天池O2O优惠券使用预测比赛的实践成果,以期不断提高自身数据分析和数据挖掘技能的落地能力。
由于没有过多借鉴其他大神的思路,笔者本次实践的成绩为0.74,排名在前5%以内,相信在进一步优化后,能取得比较不错的成绩。
项目介绍
数据
赛题提供的数据为用户在2016年1月1日至2016年6月30日之间真实线上线下消费行为,用以预测用户在2016年7月领取优惠券后15天以内的使用情况,用户及商家隐私信息已做脱敏处理。
数据集主要分为三个部分,依次为用户线下领券及消费行为-测试集、用户线下领券及消费行为-训练集、用户线上领券及消费行为-训练集:
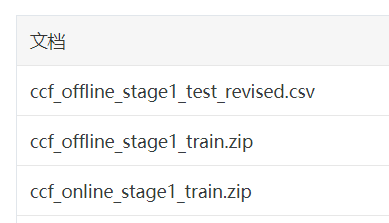
用户线下领券及消费行为-测试集的字段说明如下:
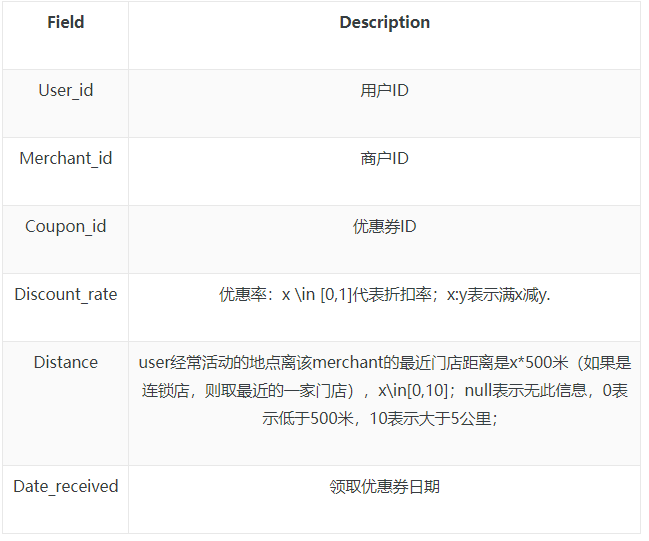
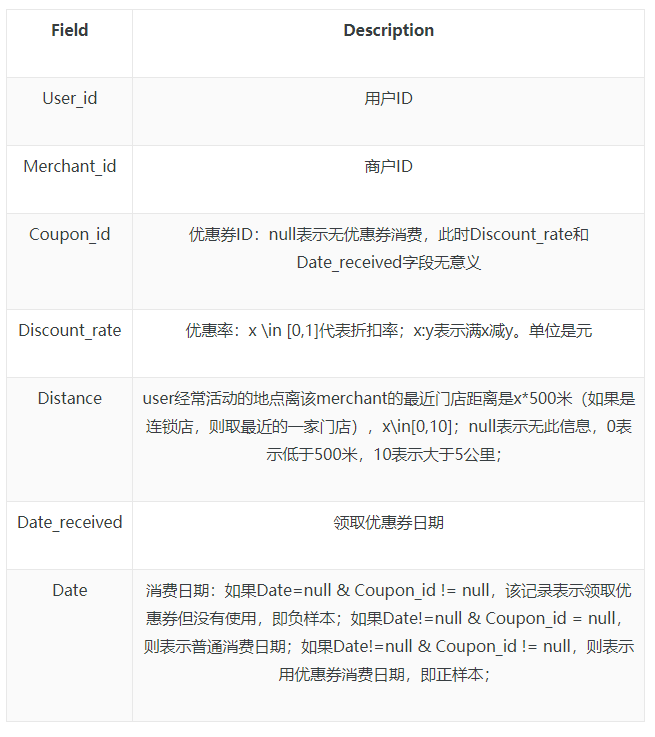
用户线下领券及消费行为-训练集的字段说明如下:
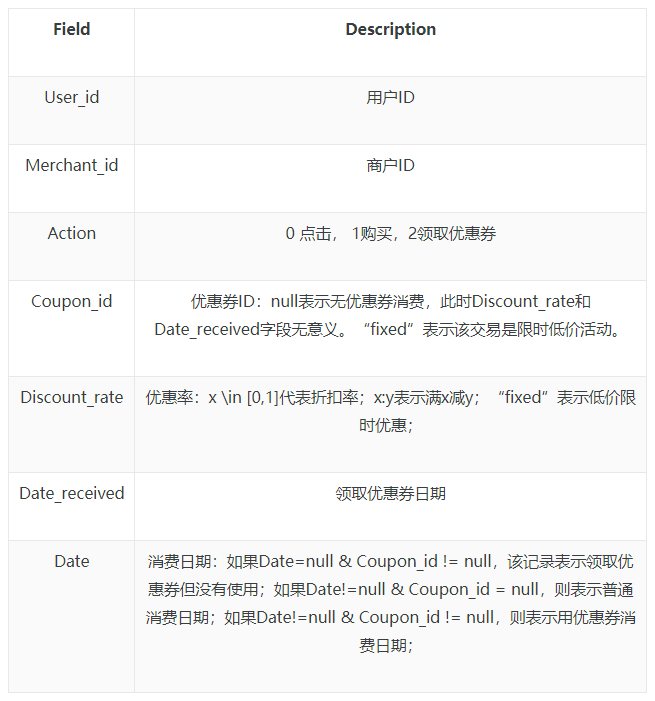
用户线上领券及消费行为-训练集的字段说明如下:
评价方式
赛题以使用优惠券核销预测的平均AUC(ROC曲线下面积)作为评价标准,即对每个优惠券coupon_id单独计算核销预测的AUC值,再对所有优惠券的AUC值求平均作为最终的评价标准。
可见该评分方式与 roc_auc_score 直接计算的AUC评分结果将存在一定的差异。
赛题分析
观察数据集及字段说明后,笔者引出如下思考:
- 数据集方面:
线下训练集与线上训练集之间可能存在关联,因为如果用户存在线上消费的习惯,则在线下进行消费的行为可能会较少;此外,若商户存在线上和线下两个渠道,则有网购习惯的用户在领取指定商家发放的优惠券后,通过线下渠道使用优惠券的可能性也会较小。 - 字段方面:
数据集提供特征维度很少,直观上可能有用的特征维度仅有Discount_rate(不同优惠力度对用户用券的刺激是不同的)、Distance(用户与商家距离越远,用户到店用券的成本理论上越高)、Date_received(节假日领券的话,用户可能更有精力和时间到店消费),因此做特征工程时应考虑构建交叉特征,以丰富特征维度,提高预测的准确性。 - 其他方面:
理论上,短期内用户的消费习惯、用券偏好不会发生重大改变,这意味着用户历史的用券和消费行为可能对预测有帮助,由于测试集是用户2016年7月份的数据,可考虑用训练集中2016年1月至2016年6月的全部或部分数据构造出历史行为特征。
基本思路
数据集划分
基于对赛题的初步分析,我希望利用训练集构造出用户的历史行为特征,因此需要将训练集划分成多份,分别用于特征提取和训练模型。
写baseline时采用的是以下的划分方式:
| 数据集类型 | 训练/测试集时间区间 | 特征提取时间区间 |
|---|---|---|
| 测试集 | 20160701-20160731 | 20160201-20160630 |
| 训练集 | 20160601-20160630 | 20160101-20160531 |
由于baseline预测成绩较为一般,最终参考wepe大神的划分方法,优化后的数据集划分方式如下:
| 数据集类型 | 训练/测试集时间区间 | 特征提取时间区间 |
|---|---|---|
| 测试集 | 20160701-20160731 | 20160315-20160630 |
| 训练集1 | 20160515-20160615 | 20160201-20160514 |
| 训练集2 | 20160414-20160514 | 20160101-20160413 |
优化后的划分方法较优化前主要有两个方面的优势:
- 优化后训练集由训练集1和训练集2合并而成,样本量增加至40W条,训练集数据量越大通常模型学习的效果越好;
- 历史行为的特征提取区间从5个月缩短到3个月,更符合用户行为习惯在短期内不会轻易改变的假设。
特征工程
如赛题分析所述,数据集提供的原始特征较少,为了从用户行为、商户行为、优惠券特点等维度获取更多信息。笔者基于业务理解和常识尽可能穷举所有维度的特征,再选取对预测结果的贡献度大于某阈值的特征,作为最终的特征。
拟提取以下几个维度的特征信息:
- 用户历史线下特征提取(用户维度)
- 商户历史线下特征提取(商户维度)
- 优惠券历史线下特征提取(优惠券维度)
- 用户-商户历史线下交叉特征提取(用户-商户维度)
- 用户-优惠券历史线下交叉特征提取(用户-优惠券维度)
- 商户-优惠券历史线下交叉特征提取(商户-优惠券维度)
- 历史线上特征提取
- 当期特征提取
各维度下具体的特征信息如下:
-
用户历史线下特征——by user
A.历史上各用户领券的次数
B.历史上各用户领券但未核销的次数
C.历史上各用户领券且核销的次数
D.历史上各用户领券后的核销率
E.历史上各用户核销的优惠券中平均/最小/最大用户与商户的距离
F.历史上用户平均核销每个商户的优惠券数量
G.历史上各用户核销过优惠券所属的商家数量及其占总商家数量的比重
H.历史上各用户核销过优惠券所属的优惠券类型及其占总优惠券类型的比重 -
商户历史线下特征——by merchant
A. 历史上各商户被领券的次数
B. 历史上各商户被领券但未核销的次数
C. 历史上各商户被领券且核销的次数
D. 历史上各商户被领券后的核销率
E. 历史上各商户被核销的优惠券中平均/最小/最大用户与商户距离
F. 历史上各商家的优惠券平均被核销的时间
G. 历史上各商家平均被每个用户核销的优惠券数量
H. 历史上核销各商家优惠券的用户数量及其占总用户数量的比重
I. 历史上各商家被核销的各类优惠券数量占总优惠券类型的比重 -
优惠券历史线下特征——by type
A.历史上各优惠券历史被领取次数
B.历史上各优惠券历史被领取但未核销次数
C.历史上各优惠券历史被领取且核销次数
D.历史上各优惠券历史核销率
E.历史上各优惠券平均被核销的时间
F.历史上各优惠券的领取时间(一周中第几天) -
用户与商户历史线下交叉特征——by user & by merchant
A.历史上各用户领取各商家优惠券的数量
B.历史上各用户领取各商家优惠券未核销的数量
C.历史上各用户领取各商家优惠券核销的数量
D.历史上各用户对各商家优惠券的核销率
E.历史上用户对每个商家的不核销次数占用户总不核销次数的比重
F.历史上用户对每个商家的核销次数占用户总核销次数的比重
G.历史上用户对每个商家的不核销次数占商家不核销次数的比重
H.历史上用户对每个商家的核销次数占商家核销次数的比重 -
用户与优惠券历史线下交叉特征——by user & by type
A.历史上各用户领取的各类优惠券次数
B.历史上各用户领取各类优惠券后未核销的次数
C.历史上各用户领取各类优惠券后核销的次数
D.历史上各用户对各类优惠券的核销率
E.历史上各用户对各类优惠券的不核销数量占其用户总不核销数量的比重
F.历史上各用户对各类优惠券的核销数量占其用户总核销数量的比重
G.历史上各用户对各类优惠券的不核销数量占各类优惠券总不核销数量的比重
H. 历史上各用户对各类优惠券的核销数量占各类优惠券总核销数量的比重 -
商家与优惠券历史线下交叉特征——by merchant & by type
A.历史上各商家被领取的各类优惠券数量
B.历史上各商家被领取未核销的各类优惠券数量
C.历史上各商家被领取且核销的各类优惠券数量
D.历史上各商家的各类优惠券核销率
E.历史上各商家各类优惠券的不核销数量占其商家总不核销数量的比重
F.历史上各商家各类优惠券的核销数量占其商家总核销数量的比重
G.历史上各商家各类优惠券的不核销数量占各类优惠券总不核销数量的比重
H.历史上各商家各类优惠券的核销数量占各类优惠券总核销数量的比重 -
用户历史线上特征——by user1
A. 历史上用户线上领券的次数
B. 历史上用户线上消费的次数
- 当期特征
A. 当期各用户领取优惠券的数目
B. 当期各用户领取各类优惠券的数目
C. 当期各用户当天领取的优惠券数量
D. 当期各用户当天领取的各类优惠券数量
E. 当期各用户此次领券之前/之后的领券数量
F. 当期各用户此次领券之前/之后的各类优惠券领券数量
G. 当期各用户领取各商家的优惠券数目
H. 当期各用户领取过优惠券的商家数量
I. 当期各用户领取的优惠券种类数量
J. 当期各商家被领取的优惠券数量
K. 当期各商家被领取的各类优惠券数量
L. 当期各商家被领取的优惠券种类数量
M. 当期各商家被不同用户领券的数目
模型选取
笔者采用的模型是以决策树为弱处理器的Xgboost算法,主要原因如下:
- 某一时间段内的活跃用户包括新用户和老用户,在构造训练集与预测集的历史特征时,由于缺少新用户的历史数据,会产生较多缺失值,而与LR相比Xgboost算法对处理缺失值的要求并不高。
- 训练集样本量较大,有效规避Xgboost容易产生过拟合的缺点,与RF相比可调的参数较多,有助于提升训练效果。
- Xgboost算法在很多比赛上的训练效果不错。
过程及代码
本部分开始用python代码实现和验证上述的分析和思考。
导入python库
# 导入库
import pandas as pd
import numpy as np
import os
import xgboost as xgb
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import roc_auc_score
import datetime as dt
导入与划分数据集
# 导入训练集和特征提取区间-线下消费情况
def get_data(path):
df=pd.read_csv(path,encoding='gbk')
return df
path=os.getcwd()
df=get_data(path+'\\ccf_offline_stage1_train.csv')
# 训练集1- date_received 20160515-20160615
df_0515_0615=df[(df['Date_received']>=20160515) & (df['Date_received']<=20160615)]
# 训练集1的特征提取区间- date_received 20160201-20160514
df_0201_0514=df[(df['Date_received']>=20160201) & (df['Date_received']<=20160514)]
# 训练集2- date_received 20160414-20160514
df_0414_0514=df[(df['Date_received']>=20160414) & (df['Date_received']<=20160514)]
# 训练集2的特征提取区间- date_received 20160101-20160413
df_0101_0413=df[(df['Date_received']>=20160101) & (df['Date_received']<=20160413)]
# 测试集的特征提取区间- date_received 20160315-20160630
df_0315_0630=df[(df['Date_received']>=20160315) & (df['Date_received']<=20160630)]
# 数据清洗-选取发生领券的数据
def clean_df(df):
df_c=df[df['Coupon_id'].notnull()]
return df_c.reset_index()
df_0515_0615_c=clean_df(df_0515_0615)
df_0201_0514_c=clean_df(df_0201_0514)
df_0414_0514_c=clean_df(df_0414_0514)
df_0101_0413_c=clean_df(df_0101_0413)
df_0315_0630_c=clean_df(df_0315_0630)
特征工程
- 用户历史线下特征提取——by user
# 用户线下特征的提取-by user
def GetFeatureByUser(df):
# 历史各用户历史领券次数
df_times_byuser=df.groupby(['User_id']).agg({
'Coupon_id':'count'}).rename(columns={
'Coupon_id':'Times_received_byuser'}).reset_index()
# 历史各用户领券未核销的次数
df_times_notused_byuser=df[df['Date'].isnull()].groupby(['User_id']).agg({
'Coupon_id':'count'})\
.rename(columns={
'Coupon_id':'Times_received_notused_byuser'}).reset_index()
# 历史各用户领券核销的次数
df_times_used_byuser=df[df['Date'].notnull()].groupby(['User_id']).agg({
'Coupon_id':'count'})\
.rename(columns={
'Coupon_id':'Times_received_used_byuser'}).reset_index()
# 历史各用户领券后的核销率
df_tem1=pd.merge(df_times_byuser,df_times_notused_byuser,how='left',left_on='User_id',right_on='User_id')
df_tem1=pd.merge(df_tem1,df_times_used_byuser,how='left',left_on='User_id',right_on='User_id').fillna(0)
df_tem1.loc[:,'ConsumeRate_byuser']=df_tem1.loc[:,'Times_received_used_byuser']/df_tem1.loc[:,'Times_received_byuser']
# 历史用户核销优惠券中平均、最大、最小用户-商户距离
# 知识点:.ravel() 转化成数组 xx.join() 用xx组合join中的字符
df_distance_byuser=df[df['Date'].notnull()].groupby(['User_id']).agg({
'Distance':['mean','min','max']})
df_distance_byuser.columns=['_byuser_'.join(x) for x in df_distance_byuser.columns.ravel()]
# 历史上各用户平均核销每个商家的优惠券数量
df_merchant_number_byuser=df.groupby(['User_id']).agg({
'Merchant_id':'nunique'})\
.rename(columns={
'Merchant_id':'Number_merchant_byuser'}).reset_index()
df_tem2=pd.merge(df_tem1,df_merchant_number_byuser,how='left',left_on='User_id',right_on='User_id')
df_tem2.loc[:,'AvgUse_byuser']=df_tem2.loc[:,'Times_received_used_byuser']/df_tem2.loc[:,'Number_merchant_byuser']
# 将上述结果组合成一张表
df_merge=pd.merge(df_tem2,df_distance_byuser,how='left',left_on='User_id',right_on='User_id')
df_merge=pd.merge(df,df_merge,how='left',left_on='User_id',right_on='User_id')
# 历史上各用户核销优惠券所属的商家数量及其占总商家数量的比重(去重)
df_number_byuser_onmerchant=df[df['Date'].notnull()].groupby(['User_id']).agg({
'Merchant_id':'nunique'})\
.rename(columns={
'Merchant_id':'Number_used_byuser_onmerchant'}).reset_index()
df_merge=pd.merge(df_merge,df_number_byuser_onmerchant,how='left',left_on='User_id',right_on='User_id')
df_merge.loc[:,'Number_used_byuser_onmerchant'].fillna(0,inplace=True)
df_merge.loc[:,'Percent_used_byuser_onmerchant']=df_merge.loc[:,'Number_used_byuser_onmerchant']/\
df_merge.loc[:,'Merchant_id'].nunique()
# 历史上各用户核销优惠券的类型数及其占总优惠券类型的比重(去重)
df_number_byuser_ontype=df[df['Date'].notnull()].groupby(['User_id']).agg({
'Discount_rate':'nunique'})\
.rename(columns={
'Discount_rate':'Number_used_byuser_ontype'}).reset_index()
df_merge=pd.merge(df_merge,df_number_byuser_ontype,how='left',left_on='User_id',right_on='User_id')
df_merge.loc[:,'Number_used_byuser_ontype'].fillna(0,inplace=True)
df_merge.loc[:,'Percent_used_byuser_ontype']=df_merge.loc[:,'Number_used_byuser_ontype']/\
df_merge.loc[:,'Discount_rate'].nunique()
return df_merge
df_0201_0514_c1=GetFeatureByUser(df_0201_0514_c)
df_0101_0413_c1=GetFeatureByUser(df_0101_0413_c)
df_0315_0630_c1=GetFeatureByUser(df_0315_0630_c)
- 商户历史线下行为特征——by merchant
# 商家线下特征提取-by merchant
def GetFeatureByMerchant(df):
# 历史上各商家优惠券被领取的次数
df_times_bymerchant=df.groupby(['Merchant_id']).agg({
'Coupon_id':'count'}).rename(columns={
'Coupon_id':'Times_received_bymerchant'}).reset_index()
# 历史上各商家优惠券被领取后不核销的次数
df_times_notused_bymerchant=df[df['Date'].isnull()].groupby(['Merchant_id']).agg({
'Coupon_id':'count'})\
.rename(columns={
'Coupon_id':'Times_received_notused_bymerchant'}).reset_index()
# 历史上各商家优惠券被领取后核销的次数
df_times_used_bymerchant=df[df['Date'].notnull()].groupby(['Merchant_id']).agg({
'Coupon_id':'count'})\
.rename(columns={
'Coupon_id':'Times_received_used_bymerchant'}).reset_index()
# 历史上各商家优惠券被领取后的核销率
df_tem1=pd.merge(df_times_bymerchant,df_times_notused_bymerchant,how='left',left_on='Merchant_id',right_on='Merchant_id')
df_tem1=pd.merge(df_tem1,df_times_used_bymerchant,how='left',left_on='Merchant_id',right_on='Merchant_id').fillna(0)
df_tem1.loc[:,'ConsumeRate_bymerchant']=df_tem1.loc[: 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4843
4843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









