







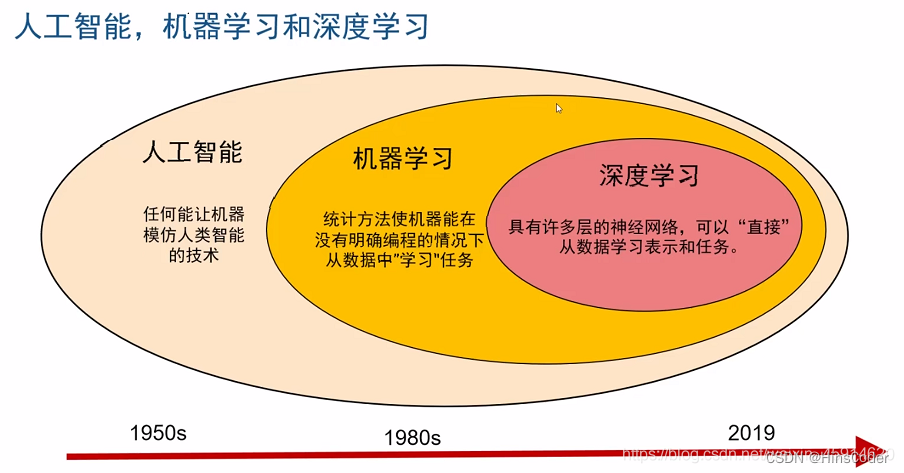
📖 前言:近年来,随着互联网和大数据应用的快速发展,人工智能技术正在迅速走进人们的日常工作与生活。在巨大的潜在市场价值面前,全球互联网企业纷纷卷入其中,如谷歌、微软、苹果、百度、腾讯等都在积极进行人工智能领域的科学研究与产品开发。从谷歌的智能软件“阿尔法围棋(AlphaGo)”以4:1战胜韩国围棋名将李世石,到腾讯的写稿机器人“梦幻写手(Dreamwriter)”在国家统计局公布年度居民消费价格指数(CPI)的第一时间就写出新闻稿,人工智能已经实实在在地来到了我们面前。所谓智能,通常是指人类大脑的高级活动,人工智能则是针对人类智能行为的模拟、延伸和扩展的技术应用。如果说300多年前蒸汽机的出现解放了人类的体力,那么人工智能的应用则有望进一步解放人类的智力。

🕒 1. 人工智能简介
🕘 1.1 什么是人工智能
Artificial intelligence (AI, also machine intelligence, MI) is intelligence displayed by machines, in contrast with the natural intelligence (NI) displayed by humans and other animals.
— from Wikepedia
人工智能(Artificial Intelligence,简称AI)是以机器为载体所展示的人类智能,因此人工智能也被称为机器智能(Machine Intelligence)。
- 人工智能学科是研究人类智能活动的规律,构造
具有一定智能的人工系统,研究如何应用计算机的软硬件来模拟人类某些智能行为的基本理论、方法和技术的学科。
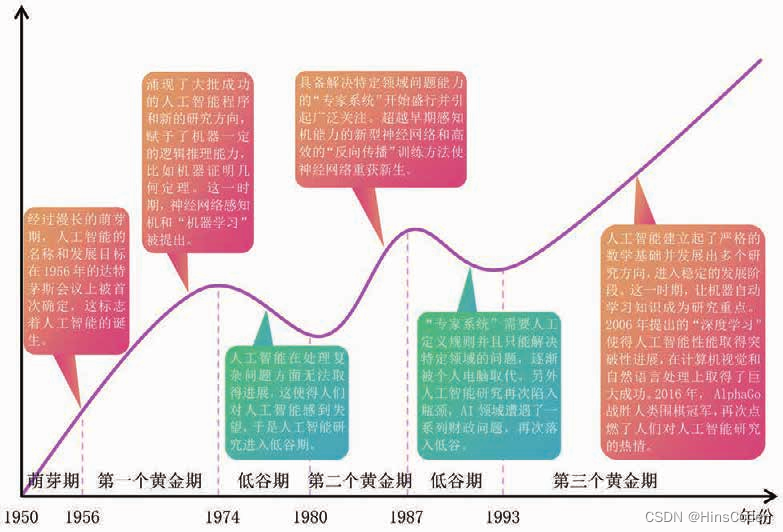
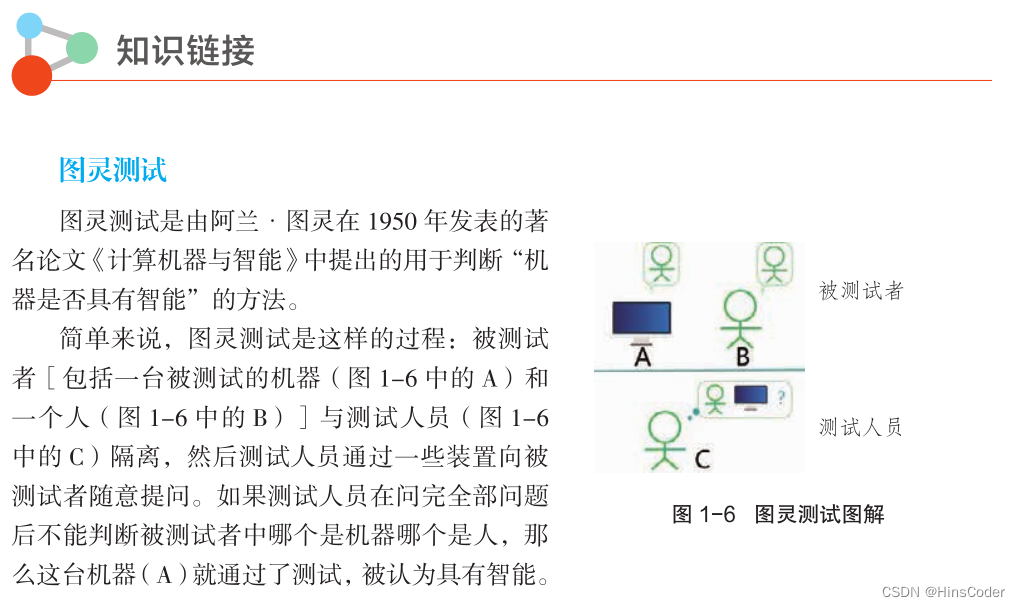
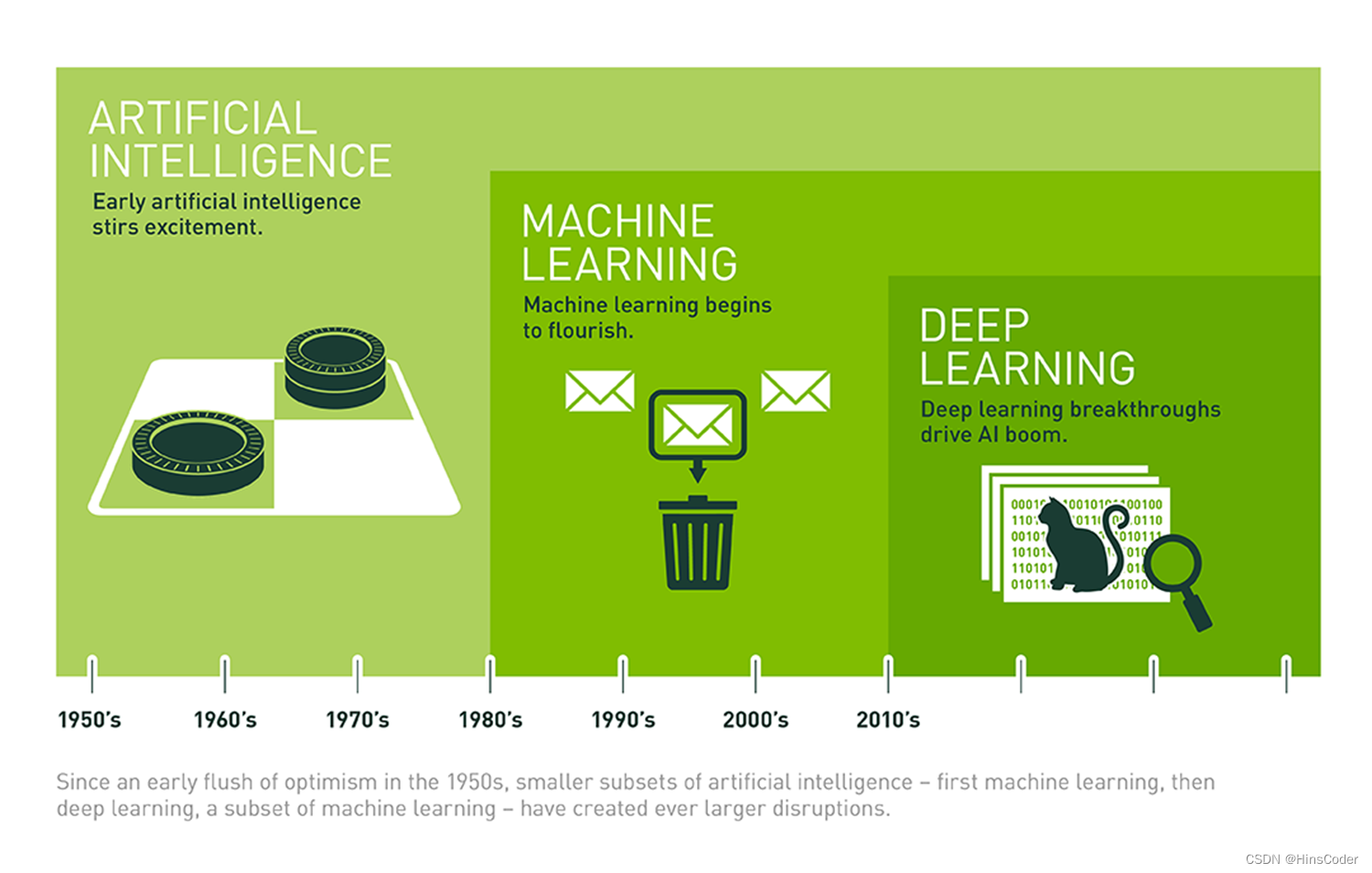
🕘 1.2 人工智能简史
🕒 2. 机器学习简介
🕘 2.1 什么是机器学习
[Machine learning is the] field of study that gives computers the ability to learn without being explicitly programmed.
—Arthur Samuel, 1959
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
—Tom Mitchell, 1997
对于某类任务 T(Tasks)和性能指标 P(Performance),如果一个计算机程序在任务T 中以 P 衡量的性能随着经验 E(Experience) 自我完善,那么就称这个计算机程序在从经验 E 中学习。
通常,为了很好地定义一个学习问题,我们必须明确以下三个要素:任务T,任务性能指标P,经验来源E。
以垃圾邮件分类系统为例,机器学习的三个要素如下:
(1)任务(T):区分正常邮件与垃圾邮件。
(2)性能指标(P):成功过滤垃圾邮件的百分比。
(3)经验(E):“阅读”现有的邮件内容。
以“阿尔法围棋”为例,机器学习的三个要素如下:
(1)任务(T):确定当前局面下一步的落子位置。
(2)性能指标(P):落子后击败对手的概率。
(3)经验(E):与自己进行对弈。
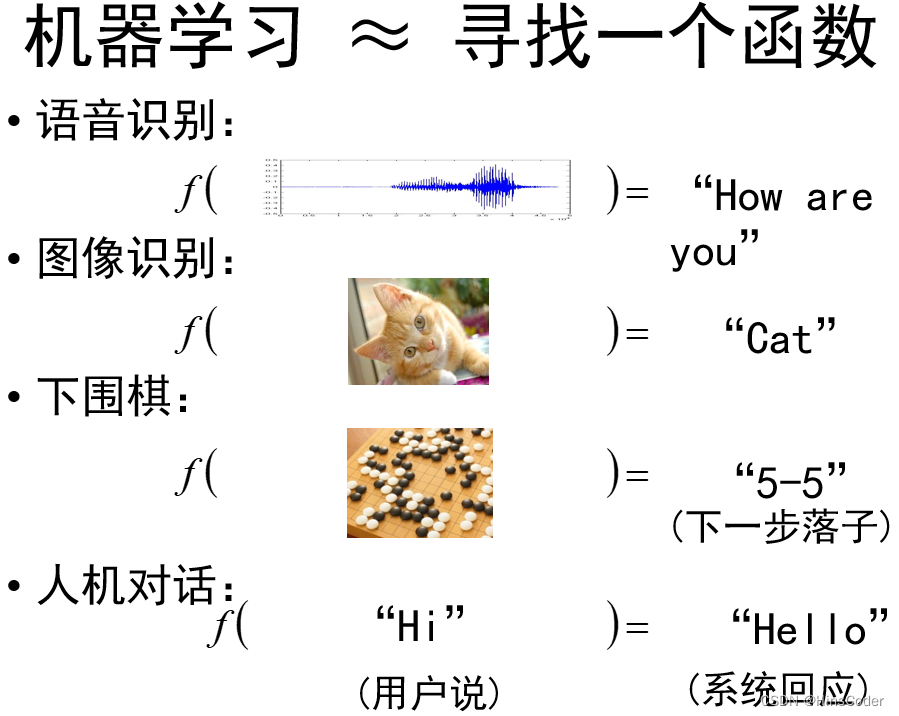
- 机器学习(Machine Learning,ML)是人工智能的一门分支科学,该领域专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构,使之不断改善自身的性能。从实践的角度看,机器学习是利用过去的数据对模型进行训练,然后使用模型对将来进行预测的一种方法。
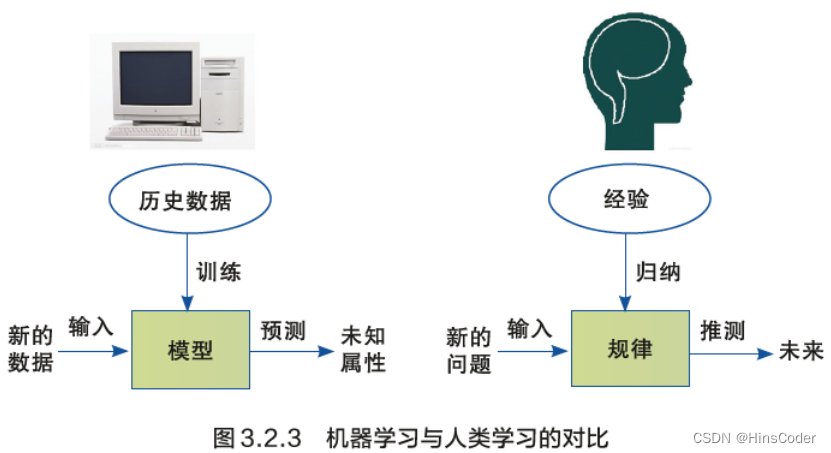
- 所谓模型,可以简单理解为函数。确定模型就是选择符合数据特征的函数;训练模型就是用已有的数据,通过各种优化算法确定函数的参数;参数确定后,再把新的数据代入函数求值就是使用模型的过程。
- 机器学习涉及概率论、统计学、算法复杂度理论等多门学科。它从学习方式上可分为有监督学习和无监督学习。有监督学习是指通过已有的训练样本(已知数据以及其对应的输出)来训练,建立起模型,再利用这个模型计算出测试数据(未知数据)的输出结果,从而实现数据的分类与判断。无监督学习事先没有训练数据样本,直接对数据进行分类建模,即没有经验和训练数据样本做参考,需要计算机自己根据整体数据特点进行分类等建模。
- 机器学习是人工智能的核心技术之一,是使计算机具有智能的重要途径,其应用遍及人工智能的各个领域。机器学习也是所有语音助手产品(包括Apple的Siri与小米的小爱同学等)能够跟人交互的关键技术。除了自然语言理解,机器学习还广泛应用于图像识别、数据挖掘、专家系统、机器人和机器博弈等领域。

🕘 2.2 机器学习的分类
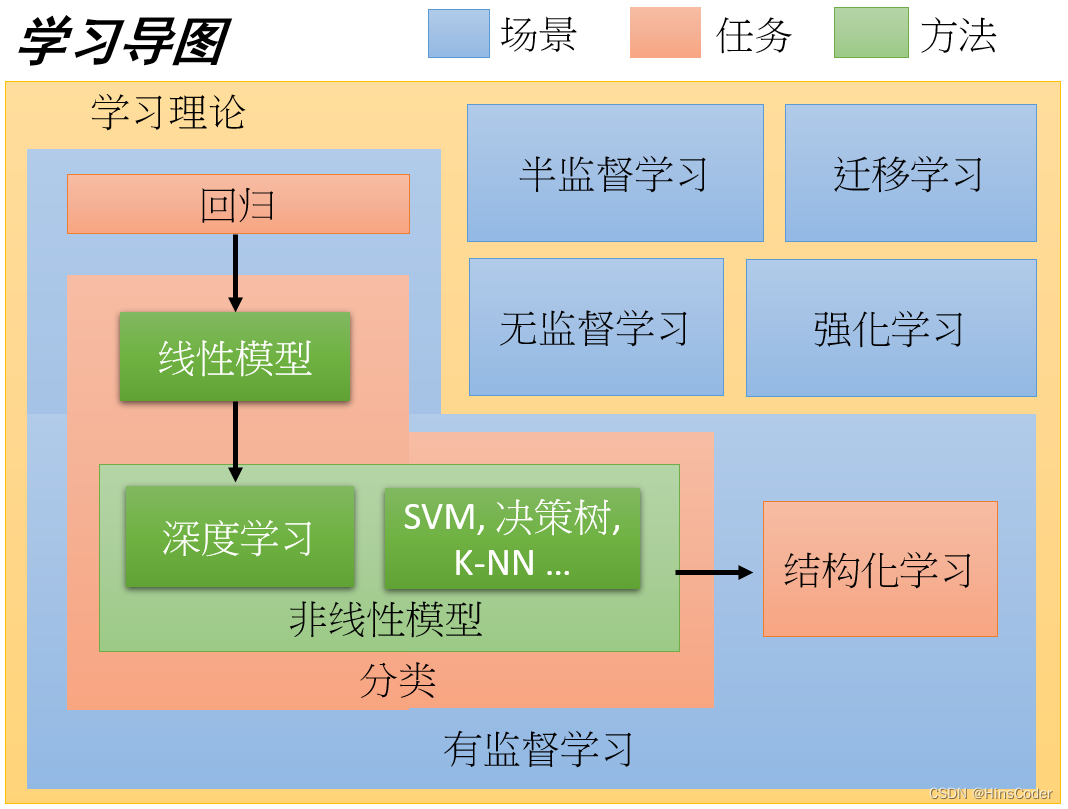
机器学习随着研究的不断深入,产生了很多适用于不同情况的算法。主要的机器学习算法类型有:
🕤 2.2.1 监督学习
监督学习是常见的机器学习方法。在监督学习中,训练数据由一组训练实例组成。每一实例都是由一个输入对象(通常是一个向量)和一个期望的输出值(也被称为监督信号)组成。
机器进行学习时,用已知某种或某些特性的样本作为训练集,以建立一个数学模型(如模式识别中的判别模型),再用已建立的模型来预测未知样本。
监督学习算法主要用来解决两类任务:分类(对实例数据预测合适的类别,如应用分类器对邮件是否包含垃圾信息进行分类)和回归(对实例数据预测具体的数值,如应用决策树对房屋的价格进行预测)。
🕤 2.2.2 无监督学习
无监督学习,顾名思义,就是不受监督的学习,一种自由的学习方式。例如,应用聚类算法的学习方式就不需要先验知识进行指导,而是不断地自我认知,自我巩固,最后进行自我归纳。在机器学习中,无监督学习可以被简单理解为不为训练集提供对应的类别标签。
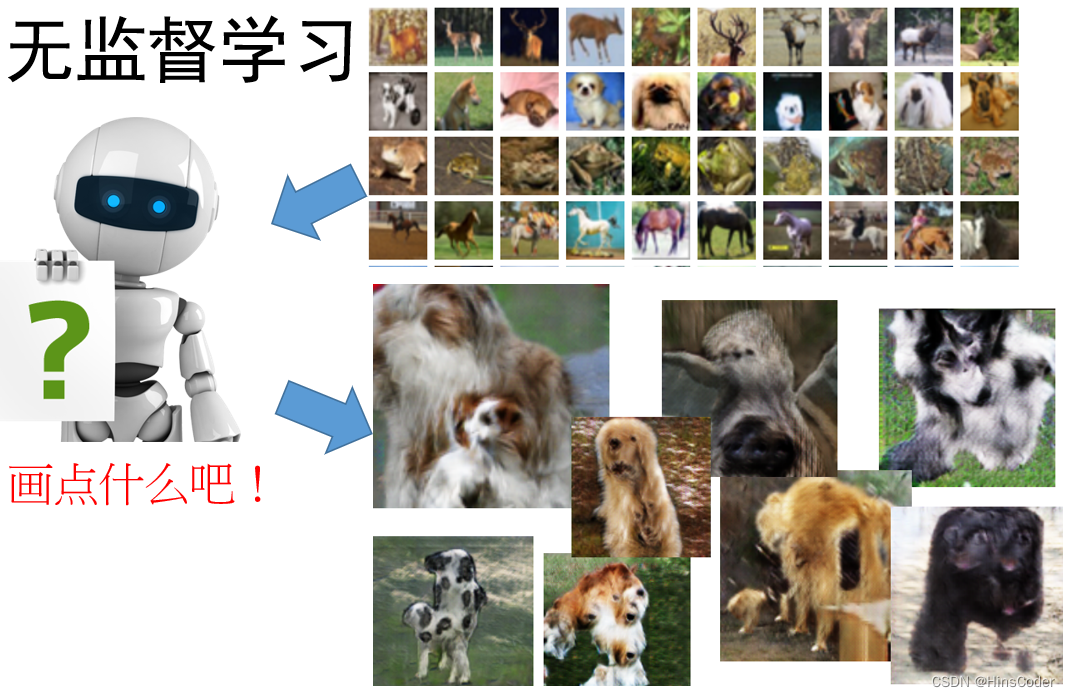

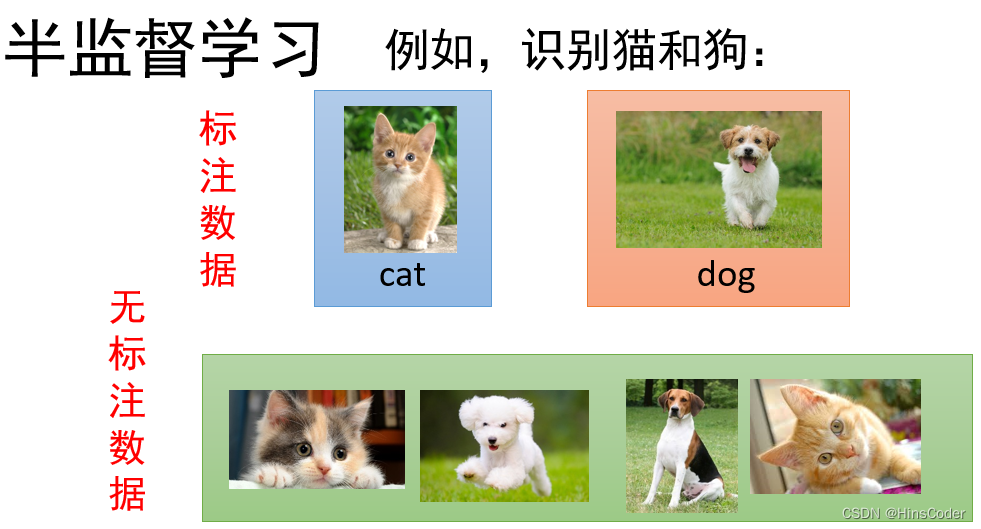
🕤 2.2.3 半监督学习
与监督学习和无监督学习不同,半监督学习综合了监督学习和无监督学习的特征。它主要考虑如何利用少量有标签的样本和大量没有标签的样本进行学习和预测。单独使用有标签的样本,能够生成监督分类算法;单独使用无标签样本,能够生成无监督聚类算法。一般而言,半监督学习通过在监督分类算法中加入无标签样本来实现半监督分类,或者是在无标签样本中加入有标签样本,增强无监督聚类的效果。

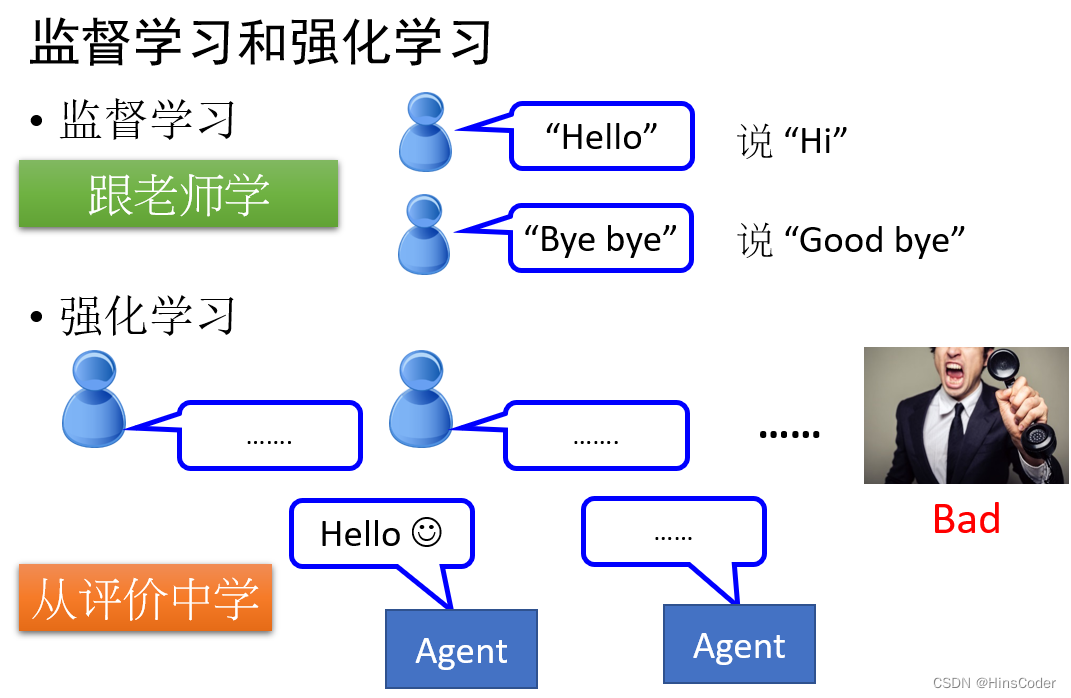
🕤 2.2.4 强化学习
强化学习是机器学习的一个重要分支,是多学科多领域交叉的产物。它的目的是解决自动决策的问题,并且可以做连续决策。它主要包含四个元素:agent,环境状态,行动和奖励。所谓强化学习,就是智能系统从环境到行为映射的学习,从而使奖励信号(强化信号)函数值最大。强化学习不同于监督学习,强化学习中由环境提供的强化信号对产生动作的好坏做评价(通常为标量信号),而不是告诉强化学习系统如何去产生正确的动作。由于外部环境提供的信息很少,强化学习系统必须靠自身的经历进行学习。通过这种方式,强化学习系统在行动—评价的环境中获得知识,改进行动方案以适应环境。

强化学习通常应用在机器人技术上。机器人中的强化学习算法是通过感知机器人当前的环境状态,训练机器人做出各种特定行为。机器人在训练过程中不断尝试,错了就扣分,对了就奖励,由此训练得到在各个环境状态下最好的决策。即机器人从以往的行动经验中得到提升并最终找到最好的知识内容来帮助它做出最有效的行为决策。
🕤 2.2.5 深度学习
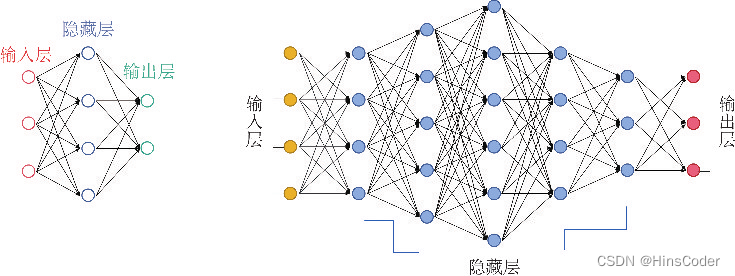
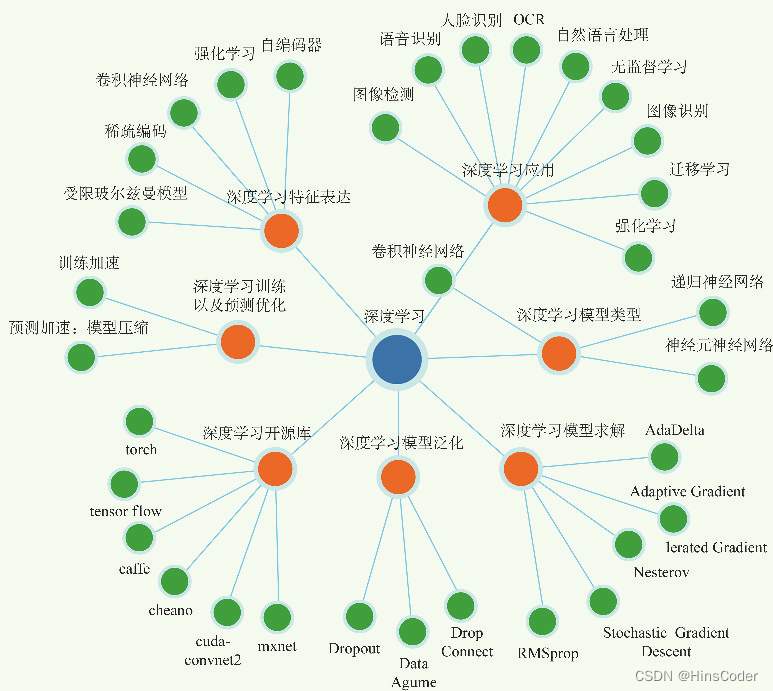
深度学习是在人工神经网络的基础上,通过更深的结构和更智能的学习算法,达到更好的大数据处理能力的一种计算模型。在这次人工智能的热潮中,深度学习发挥了举足轻重的作用,并被广泛应用于图像识别、文件处理、声音合成、金融科技等各个领域。
深度学习其实说的是“深度神经网络的学习”,因此,深度学习泛指包含很多中间层(隐藏层)的多层神经网络
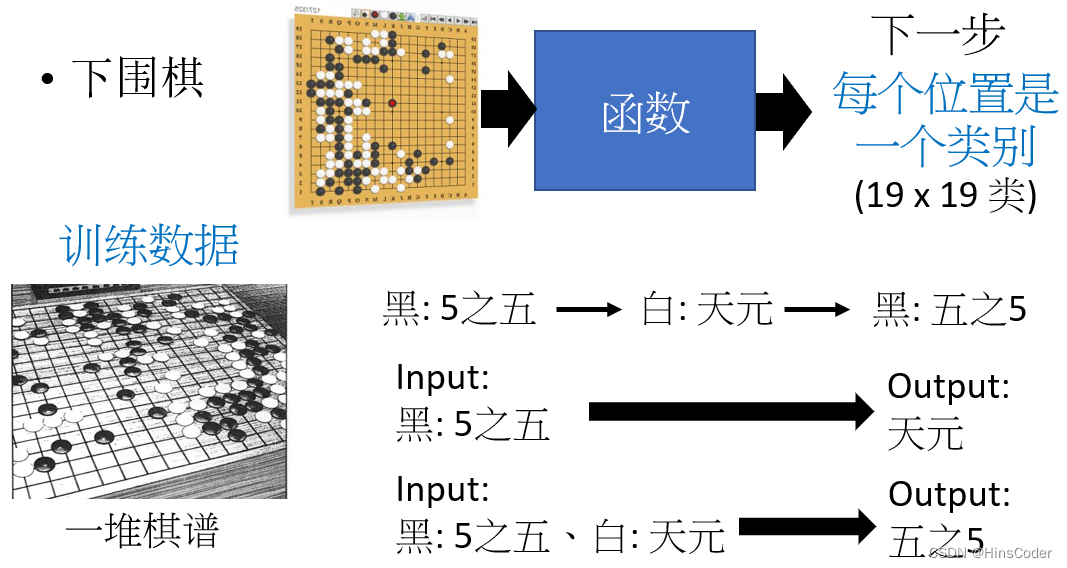
在实际应用中,环境、知识库和执行部分决定了机器学习具体的工作内容。环境向学习部分提供信息,学习部分利用这些信息修改知识库,以增进系统执行部分完成任务的效能,执行部分根据知识库完成任务的同时,把获得的信息反馈给学习部分。
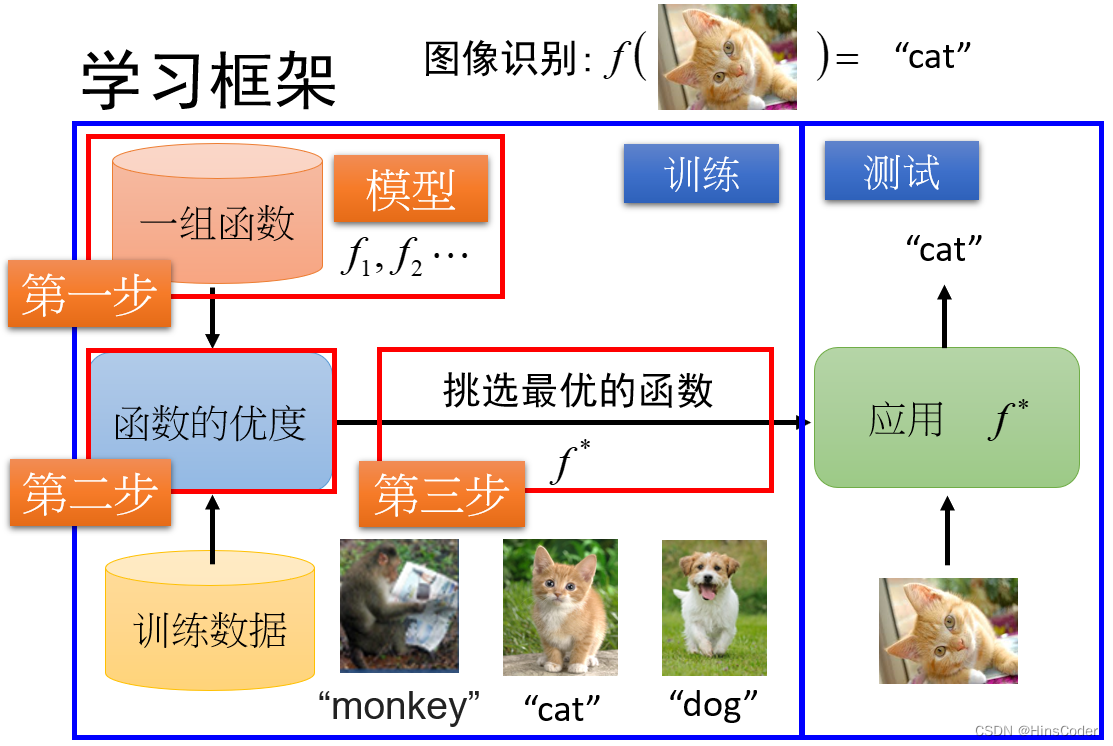
🕘 2.3 机器学习任务的一般步骤
- 给定任务,分析可能的相关特征,收集训练数据
- 特征工程 :获取数据,特征预处理
- 确定函数集合:
确定学习的目标函数:学习目的通常是通过对训练数据学习、优化模型参数,最终使得目标函数取得极小值。如监督学习的目标函数通常包括:训练集上的损失(也称残差、误差等)之和和正则项
损失函数L:计算预测结果和测量(真实结果)的差异的函数正则项R:对模型复杂度“施加惩罚”,以改善模型性能(自动削弱不重要特征参数,避免过拟合)引入。
- 模型训练:确定优化算法
- 根据训练数据得到模型参数
- 模型选择:在验证集上
评估模型预测性能
机器学习任务是一个迭代的过程,在步骤6之后可回到步骤1~5
🕒 3. Python简介
🕘 3.1 为什么使用Python
此处不再深入探究Python的特点,之后会专门开一个介绍Python的专栏
🕘 3.2 Python的开发环境
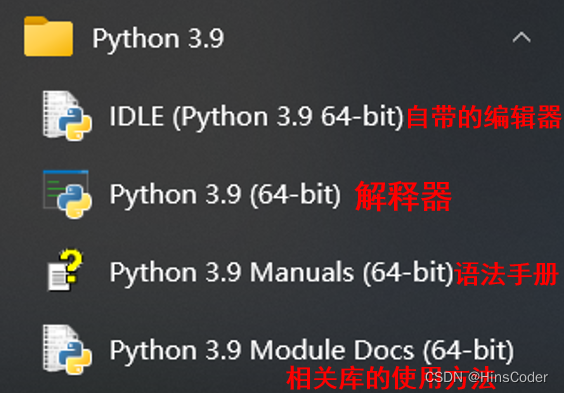
🕤 3.2.1 解释器
Python解释器是将python源码高级语言解析为二进制机器语言的工具。通常说安装python就是指安装python解释器。

🕤 3.2.2 编辑器
正如在电脑上编辑文档需要用Word、处理数据需要用Excel、修图需要用PS一样,编写代码也需要特定的工具。而这个用来编写代码的工具就叫做编辑器。 Python的编辑器有很多,有Python解释器自带的IDLE、基于ipython的 Jupyter Notebook、也有如PyCharm、Spyder、WingIDE等主要针对Python代码编辑的编辑器;还有很多编辑器,如Sublime Text、VSCode、Vim等适合各种编程语言的编辑器。
PyCharm
🔎 下载链接
🕤 3.2.3 包管理工具
Python最大的优点之一就在于其丰富的库,pip(package installer for Python)就是库管理工具,通过pip就可以安装、卸载、更新众多的库。
注:Python 3.4以后版本的解释器自带pip工具。
- Anaconda
一个用于科学计算的Python发行版
提供了包管理与环境管理的功能,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题
🔎 下载链接
Anaconda优点:集成了相当多的第三方库,一键安装,无需手动配置- NumPy( http://www.numpy.org/ ):用于处理(大)数组
- Pandas(http://pandas.pydata.org/):数据分析工具包
- Matplotlib(http://matplotlib.org):用于绘制图表
- SciPy(http://www.scipy.org):包含许多有用的科学函数
- Scikit-learn(http://scikit-learn.org/):机器学习算法
- IPython(http://ipython.org/):基于Shell或浏览器的开发环境
- Spyder( https://www.spyder-ide.org/ ):交互式集成开发环境
🕤 3.2.4 小结
- 安装python涉及到python解释器、代码编辑器和pip包管理工具这3个工具。
- 方法1:安装python解释器+第三方编辑器
python解释器3.4以后的版本自带pip包管理工具,且自带代码编辑器IDLE,因此安装了3.4之后版本的解释器相当于安装了3个工具。但是,由于自带的IDLE不好用,只适合少量代码编辑,因此一般会再安装一个第三方的编辑器,如pycharm,vscode等。 - 方法2:安装Anaconda+第三方编辑器(推荐)
anaconda有两个好处,一是集成了很多常用的,尤其是和数据分析相关的第三方库以及python3.7版本解释器以及很多编辑器(如jupyter、Spyder等);二是可以创建虚拟环境,兼容python2.x和python3.x,因此更加方便,因此很多人会选择安装anaconda(安装anaconda就不用按照第2点,方法1操作了),只要安装了anaconda,也就相当于集齐了安装python需要的3个工具,而且更多。
为什么还要安装pycharm呢(只要安装了anaconda,完全可以不安装pycharm),只是因为anaconda虽然有很多编辑器(如jupyter、Spyder等),但是pycharm是专门针对python的,非常方便,行业应用多,因此,作为长期学习工作考虑,有必要安装学习。此外,尽量使用英文原版是最合适的。
🕘 3.3 Python的使用
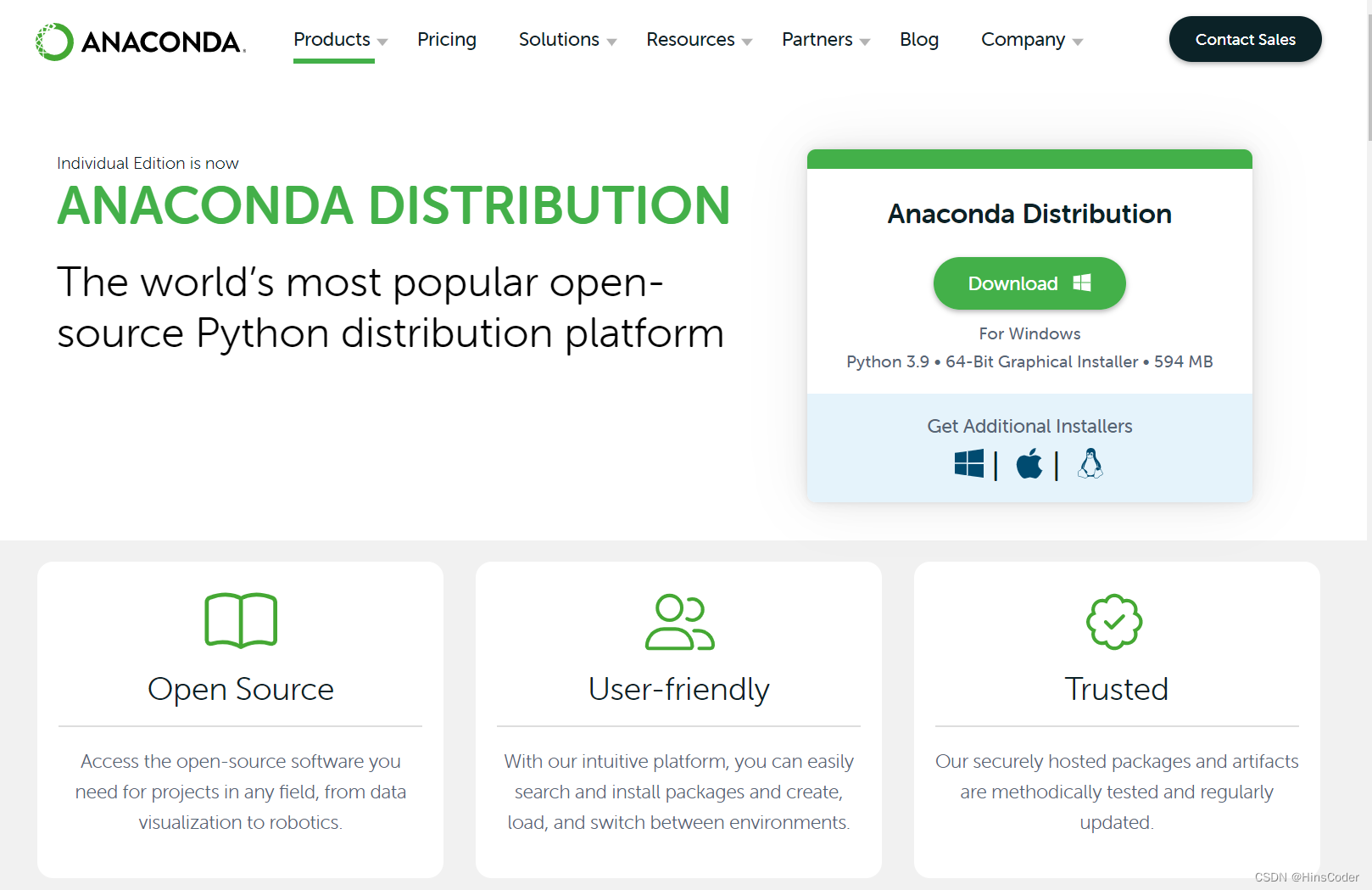
注:安装后在开始菜单找到打开
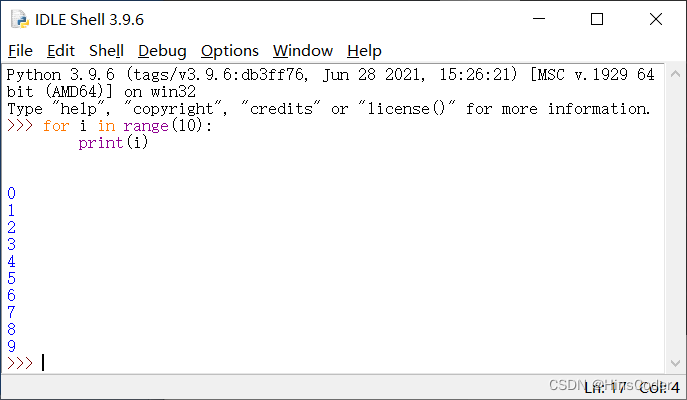
前面提到,尽管自带的编辑器可以完成代码的编写,但是效率不高,不适合大量代码的编写。因此推荐使用Anaconda+Pycharm来编写
🕤 3.3.1 Anaconda
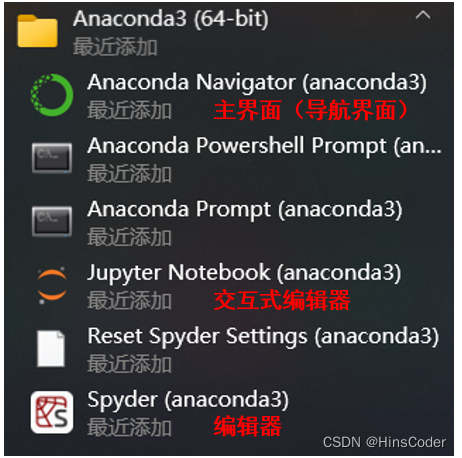
🕤 3.3.2 Jupyter Notebook
此前被称为IPython Notebook
多语分析环境—支持40多种编程语言
Jupyter是Julia, Python和R几个词的变位词
支持多种内容类型:代码、描述文本、图像、视频等等
- HTML & Markdown
- LaTeX(公式)
- Code(代码)
- 代码被划分成多个单元,可以控制执行过程
- 允许进行交互式开发
- 非常适合探索式分析与建模
🕤 3.3.3 Spyder
OK,以上就是本期知识点“基本概念简介与Python环境搭建”的知识啦~~ ,感谢友友们的阅读。后续还会继续更新,欢迎持续关注哟📌~
🎉如果觉得收获满满,可以点点赞👍支持一下哟~















 4573
4573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









