






 博客介绍了ResNet - 50的网络结构,并给出相关参考资料。同时对FLOPs进行解释,指出FLOPS全大写指每秒浮点运算次数,是衡量硬件性能指标;FLOPs小写指浮点运算数,可衡量算法/模型复杂度,也提供了相关参考链接。
博客介绍了ResNet - 50的网络结构,并给出相关参考资料。同时对FLOPs进行解释,指出FLOPS全大写指每秒浮点运算次数,是衡量硬件性能指标;FLOPs小写指浮点运算数,可衡量算法/模型复杂度,也提供了相关参考链接。
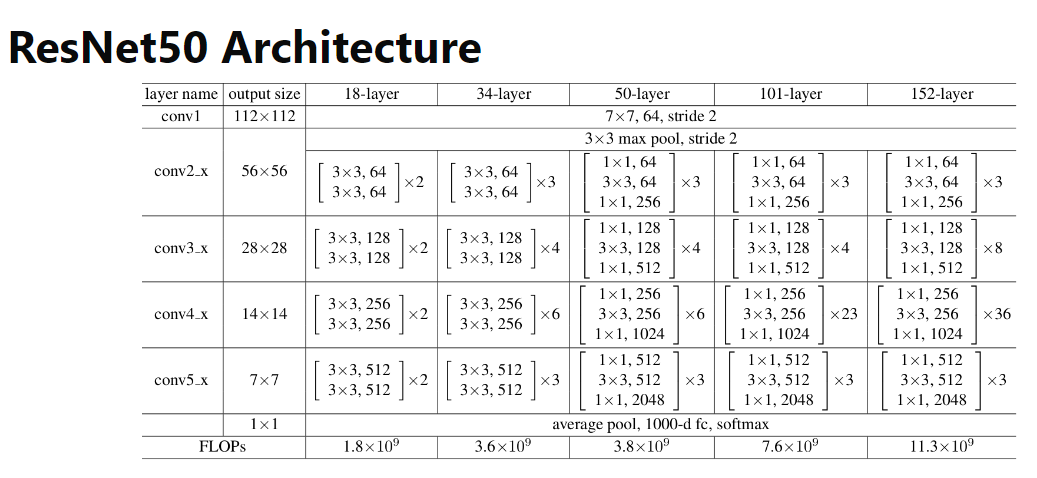
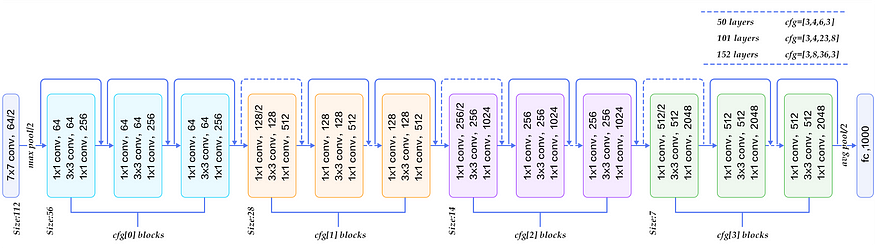
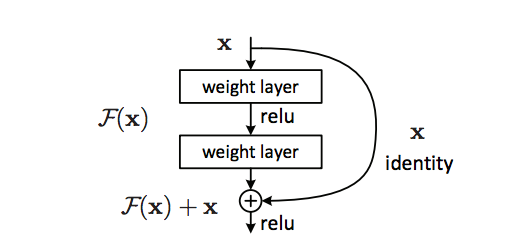
ResNet-50的网络结构:
参考资料:
https://iq.opengenus.org/resnet50-architecture/
https://blog.devgenius.io/resnet50-6b42934db431
https://viso.ai/deep-learning/resnet-residual-neural-network/
https://datagen.tech/guides/computer-vision/resnet-50/
https://towardsdatascience.com/understanding-and-coding-a-resnet-in-keras-446d7ff84d33
啥是FLOPs ( floating-point operations per second)
每秒浮点运算次数 (FLOPS)
https://zhuanlan.zhihu.com/p/137719986
- FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
- FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









