









NIN(Network in Network)和Inception v1(Google Netv1)
因为前几天看论文用到了GAP,加上之前看Unet++的时候就想再多了解一下deep supervision,所以回来看了看NIN和GoogleNetv1,都写了笔记了,不发岂不是亏啦!
NIN(Network in Network)和Inception v1(Google Netv1)
NIN
前言
传统的卷积神经网络通常由卷积层和池化层交替堆叠进行feature exaction,最后接全连接层整个所有特征得到分类结果。
卷积是通过线性滤波器对应特征图位置相乘并求和,然后进行用activation function引入非线性表达,得到feature map。
这样的linear filter足以抽象线性可分的隐含特征,但实际上,特征通常是高度非线性的,传统的CNN是通过堆叠一组超完备的linear filter(足够多),用足够多的数量,提取统一潜在特征的各种变体(宁可错杀一千,也不放过一个)
但是同一潜在特征使用太多的滤波器会给下一层带来额外的计算负担,需要考虑来自前一层的所有变化的组合,来自更高层的滤波器会映射到原始输入的更大区域,它通过结合下层的较低级概念生成较高级的特征,因此作者认为网络局部模块做出更好的特征抽象会更好,顺势引入Network in Network则能达到这个目标,在每个卷积层内引入一个微型网络,来计算和抽象每个局部块的特征。
个人理解:这段事实上在说,与传统CNN的特征提取不同的时,作者并不想使用那么多的传统卷积层,希望使用较少的传统卷积层,在每个卷积层里引入一个小的网络,来表达隐含特征,从而提供计算效率。
网络结构

黄色框为创新点1
橘色框为创新点2
MLP Convolution Layers
论文提到一开始并不知道潜在特征的分布,因此用一个通用的函数逼近器提取局部块特征,这样可以尽可能逼近潜在特征的抽象表示。
径向基(Radial basis network)和 从多层感知机(multilayer perceptron)是两种通用的函数逼近器,作者选择了多层感知机,因为多层感知器与卷积神经网络的结构一样,都是通过反向传播训练。其次多层感知器本身就是一个深度模型,符合特征再利用的原则。
所谓MLPConv其实就是在常规卷积(感受野大于1的)后接若干1x1卷积,每个特征图视为一个神经元,特征图通过1x1卷积就类似多个神经元线性组合,这样就像是MLP(多层感知机)了,这是文章最大的创新点,也就是Network in Network(网络中内嵌微型网络)。
每个特征图视为一个神经元:
事实上很多大佬都这么看,比如FCN作者就将每个卷积核看作一个神经元,想到了全卷积网络
为什么说通过1x1 conv就相当于多个神经元线性组合呢?
因为1x1卷积层的每个kelnel的shape都是1x1xinput_channel,与输入的feature map做卷积(相乘相加)就得到一个input_h x input_w x 1的feature map,相当于一个神经元,一共有output_channel个神经元
所以我认为这样的1x1 conv就是一种fully—connected 的卷积
个人理解
个人理解:神经网络设计出来就是逼近任意的非线性连续函数,这样的NIN设计,即外层Network提取特征,内嵌的Network进行潜在特征的逼近,来表达特征的非线性性,而传统的CNN就是通过堆叠卷积层、用激活函数提升非线性表达,增加层数之后即可表达非线性的潜在特征(浅层用来提取特征,深层利用浅层提取的特征进行潜在特征的非线性表达)所以NIN并不需要那么多的传统卷积层。
GAP(Global Average Pooling)
传统卷积神经网络在网络的浅层进行卷积运算。对于分类任务,最后一个卷积层得到的特征图被向量化(flatten)然后送入全连接层,接一个softmax逻辑回归层。这种结构将卷积结构与传统神经网络分类器连接起来,卷积层作为特征提取器,得到的特征用传统神经网络进行分类。全连接层参数量是非常庞大的,模型通常会容易过拟合,针对这个问题,Hinton提出Dropout方法来提高泛化能力,但是全连接的计算量依旧很大。
全连接层的参数一般占整个传统CNN网络的百分之60左右,可以说是很庞大的参数,在没那么大的dataset上很容易overfitting 也是想得到的。
基于此,论文提出用**GAP(全局平均池化)**代替全连接层,具体做法是对最后一层的特征图进行平均池化,得到的结果向量直接输入softmax层。这样做好处之一是使得特征图与分类任务直接关联,另一个优点是全局平均池化不需要优化额外的模型参数,因此模型大小和计算量较全连接大大减少,并且可以避免过拟合。
具体做法:对feature map的每一个channel做平均得到一个数,共得到channel_of_feature_map个数(即这个大的一个vector),如下图所示


GoogleNetv1
应用NIN的1x1 Conv
GoogleNetv1网络中,1x1卷积有两个目的:最重要的是,它作为一个降维模块,可以降低计算量。这允许我们可以增加深度和宽度,却不降低网络的性能。
即瓶颈层Bottleneck,先把1x1卷积通道降下来,再标准卷积升回去,计算量就大大减小,有兴趣可以自己计算对比一下,Andrew Ng举得例子里,直接下降到原来1/10
Inception架构实现“自动构建”网络结构

上面的架构(至少naive版本)有一个很大的问题:即使5x5卷积的计算量很大(当前层有很多channel时)。这个问题随着max-pooling的加入,变得更明显。所以作者在b中加了1x1卷积,减少计算量。
由于训练时的内存efficiency,所以只在高层使用Inception模块,低层仍然使用传统的卷积配置。
这个架构的 最主要特点是,在计算量不显著变化的情况下,它允许增加网络宽度(这主要归功于1x1卷积)。另一个特点是,它将多尺度考虑了进去。
Inception架构对于计算资源的高效利用允许增加网络尺寸(深度、宽度),同时几乎不增加计算量。并且Inception的推理速度很快。
为什么说考虑了多尺度因素呢?
因为大尺度的大目标,会考虑更大的领域空间的特征,即需要大的size的卷积核(如5x5,7x7)
小尺度的小目标则正好相反,比较适合小的size的卷积核(如3x3)
为什么可以自动构建网络结构?
因为这样设计的Inception,事实上网络会学习到要使用3x3还是5x5的卷积,是否要使用池化这样的信息比较会得到好的结果
例如:如果不使用用,就让那层参数都是0就好了
所以具备这样的自动构建的能力,更加贴合AI的I(很智能对吧)
GoogleNetv1的网络架构与Deep Supervision
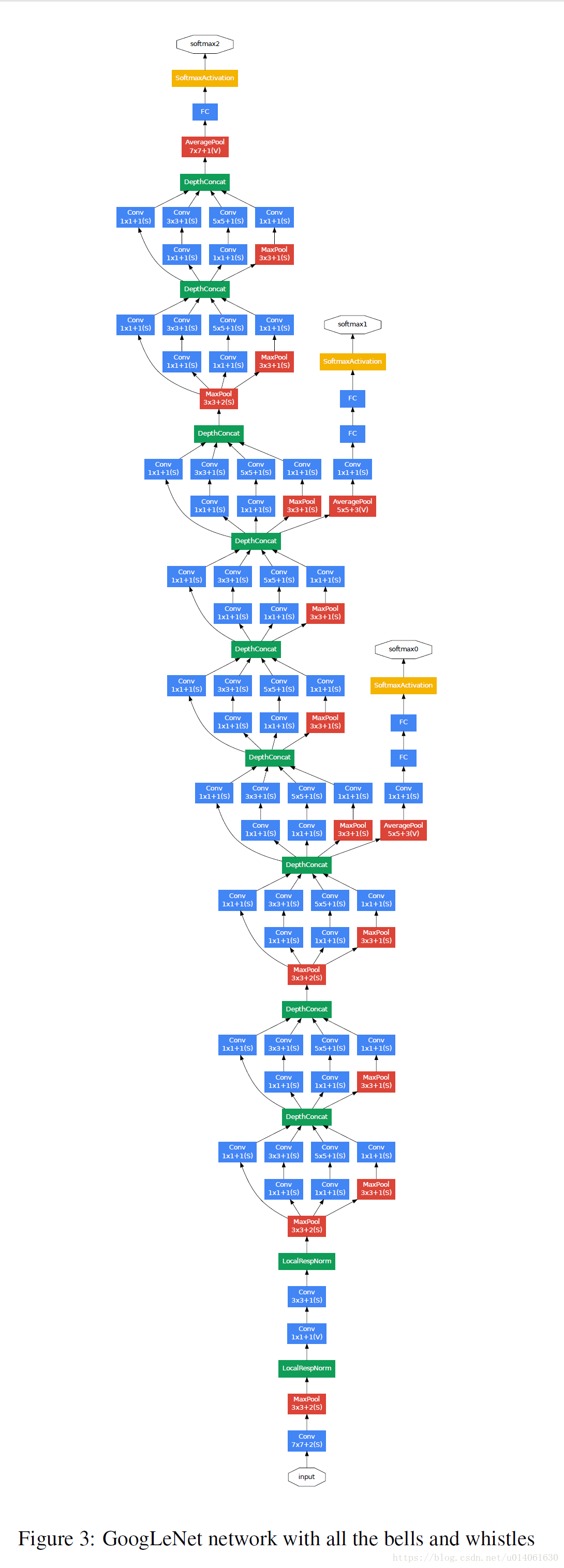
可以看到,Inception模块的max pool事实上和我们通常的max pool不太一样,这个max pool是以1为stride的,不会改变feature map的H和W
Deep Supervision深度监督是什么
看一下图中,事实上有3个softmax,softmax0,softmax1和softmax2,即有三种分类器,三种输出
这就是deep supervision,在同一个网络的不同深度处,拉出来一个分支的输出,这样不仅可以让深度网络的梯度传播得到优化,一定程度避免梯度消失和梯度爆炸;还可以在测试时进行prune(剪枝)(U-Net++的思想),看看哪个深度的输出更适合验证集,能得到更好的验证以及测试的效果
网络这么深,梯度怎么合理的反向传播,作者给网络额外增加了两个分类器(Inception 4a和4d输出)。
训练时,将额外的两个分类器的loss乘以0.3加到最后的cost上
inference时,去除额外的分类器。(增加额外的分类器就是为了解决梯度反向传播的问题)
两个额外分类器的配置如下:
A average pooling with 5x5 filter size and stride 3. resulting in an 4x4x512 output for the (4a), and 4x4x528 for the (4d) stage.
A 1x1 conv with 128 filters and ReLU
A FC with 1024 units and ReLU
A dropoout layer with 70% ratio of dropped outputs
A linear layer with softmax as classifier (predicting the same 1000 classes as the main classifier, but removed at inference time)
参考
1.NIN: https://blog.csdn.net/ouyangfushu/article/details/90212925
2.GAP:https://www.jianshu.com/p/510072fc9c62
3.GoogleNetv1:https://blog.csdn.net/u014061630/article/details/80308245















 590
590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









