







摘要:主要介绍字符处理类命令
选取命令:grep cut
awk sed 工具
排序命令 sort 及 uniq wc
文件比较工具 diff cmp
双向重导向 tee
字符转换类命令...
....
字符处理类命令(grep,cut,awk,sed,sort,uniq...)
1.选取命令(grep cut)
1.grep "字符串" 文件名(查找文件包含字符串的行)
-v 排除指定字符串的行
-i 忽略大小写
-n 输出对应行号
-c 计算找到'搜索字串'次数
--color=auto 关键字颜色标出(可在 ~./bashrc 添加 alias grep='grep --color=auto'永久生效)
eg:grep "/bin/bash" /etc/passwd | grep -v "root" 列出所有普通用户(行)

2.
cut
文件名
字段提取 截取列(这个命令对于分割符比较较真,只能截取规律行的列,对于多空格连接数据不易处理 就要用下面 awk 工具处理)
-f
列号
提取第几列
-d
分隔符
指按照指定的分隔符分割列(默认Tab)
-c nu1-(nu2) 提取第nu1以后(到nu2)所有字串
eg:
列出所有普通用户
 2.awk工具
2.awk工具
1.printf '输出类型输出格式' 输出内容 标准输出(学习awk得先了解print使用)
输出类型
%ns:输出n个字符串
%ni:输出n个整数
%m.nf:输出m个整数,n个小数的浮点数
输出格式
\a:输出警告声
\b:输出退格键
\f:清屏
\r:回车
\t:水平输出退格键(Tab)
\v:垂直输出退格键(Tab)
2.awk命令 提取每列第几个变量
1.awk '条件1{动作1} 条件2{动作2}...' 文件名
条件一般用关系表达式(
BEGIN{}首先执行
END{}
最后执行 ">=<"
)
动作格式化输出 流程控制
注意:
awk 提取相应列字段 是把文件每行整行
先
读入
再
每个字段对应
$1,$2,$3...
判断条件,成立执行动作。
模式匹配
awk '/正则表达式/{}'
匹配含有正则表达式的行
eg:查看分区硬盘已用百分比
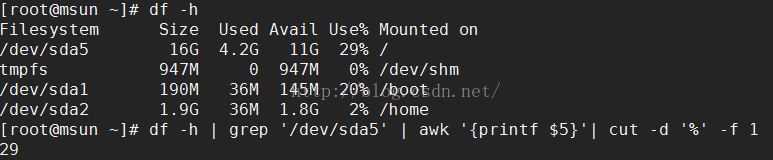
eg:
awk提取默认过程,
BEGIN作用(FS内置变量 = ":" 指定分隔符)
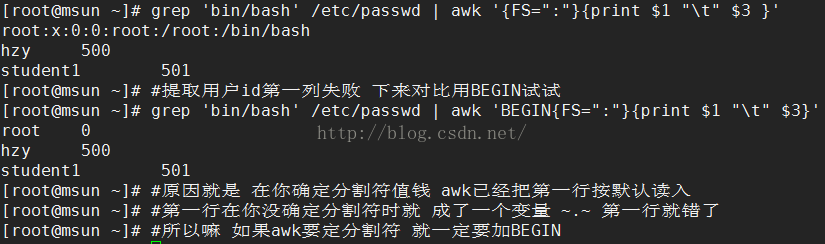
![]()
3
.sed工具
将数据进行选取、替换、删除、新增
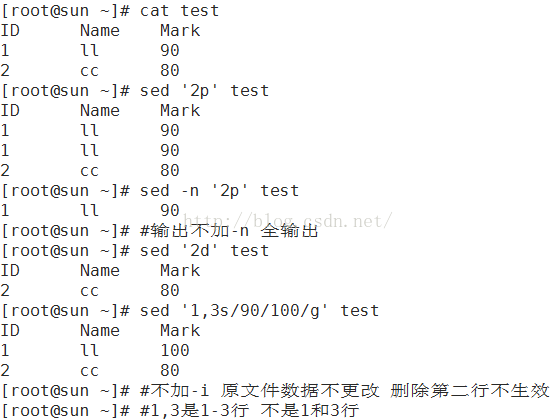
1.sed [选项] '[动作]' 文件名
选项:
-n 把经过sed处理的行输出到屏幕。默认文件全输出
-e 允许对输入数据应用多条sed命令编辑(可一次执行多次动作 '动作1;动作2')
-i sed修改结果直接修改读取数据的文件,不向屏幕输出
动作:
a 追加,在当前行后添加一行或多行
格式 '行范围a 内容'
c 行替换,c后数据的字符串替换原数据
i 插入,在行前插入一行或多行
d 删除,指定行
格式 '行范围d'
p 打印,输出指定行
s 字串替换,用字符串替换另一字符串 格式 '行范围s/旧字串/新字串/g'
eg:
4.排序命令(sort)
1.
sort 文件名
-f 忽略大小写
-n 以数值型排序,默认字符串型
-r 反向排序
-t 指定分割符,默认制表符
-k n[,m] 按照指定字段范围排序。从第n字段开始,m字段结束,默认行尾
-b 忽略最前面的空白字符部分
-M 以月份名排序
2.uniq 重复数据仅显示1个
-i 忽略字符大小写
-c 进行计数
eg:
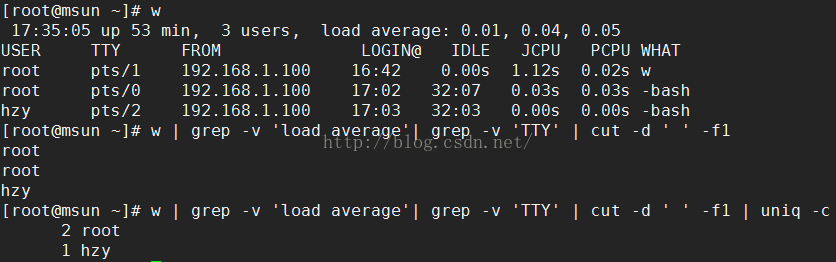
![]()
3.
wc 文件名
-l
行数
-w
单词
-m
字符数
5
.文件比较工具(diff,cmp)
1.diff file-old file-new 用于比较相近文件区别(主要是区分新旧文件)(以行为单位)(注:可用“-”代表前面一文件 其中“-”是上一个管道命令输出做为这次输入)
-
b 忽略多几个空格
-B 忽略空白行区别
-i 忽略大小写
eg:
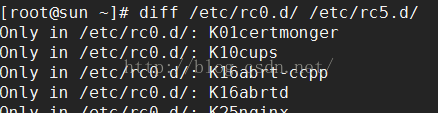
2.patch [] <file.patch (filepatch由 diff file1 file2 >file.patch(制作补丁) 产生)
-pN 取消几层目录(如果两文件(新旧版)在同一目录 则N=0)
-R 代表还原,将新的文件还原旧文件
[patch -pN < patch_file(补丁) <==更新]
[patch -R -pN < patch_file <==还原]
3.cmp file1 file2 比较文件区别(以字节为单位)
-s 将所有不同列出(默认只找第一个不同字节)
6.双向重导向(tee)
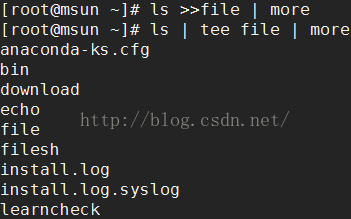
tee file(一般格式:命令1(有输出)| tee file | 命令2) tee把命令1输出存入file后,数据还是可以利用做命令2的输入(不加不可以)
-a 累加进入file(无则会覆盖原文件)
eg:
7.字符转换命令(tr,col,join,paste,expand)
1.tr '字串1' '字串2' 把字串1全变为字串2
-d '字串' 删除字串
eg:

![]()
2.join file1 file2 整合文件1和文件2的数据
对比(第一个)字段(空白字符分割)相同放一行,并把比较的字段放首列
-t 指定分割符
-i 忽略大小写
-1 nu1 -2 nu2 指定文件1的字段1和文件2字段2分析
eg:

3.paste file1 file2 把文件1和2直接对应行贴一起
-d 两文件指定分割符(默认Tab)
- 如果file用-代替则代表是上级输入
4.col
-x
把 文件中的 tab键 换成 空白键
5.expand 把tab转换空白键
-t num 一个tab转化成多少个空格键(默认8)
8.文件分割命令(split)
split file (prefile)
-b num(b/k/m) 与分割成文件大小
-l num 以行数分割
prefile:分区文件分了后启的名字(prefileaa,prefileab)
(prefile* >>file 可还原)
9
.参数代换:xargs (很多命令不支持管道命令,通过前加xargs来引用前一命令输出当输入)
10.文件打印准备:pr















 985
985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









