






1. sorted()不会对原来的数据产生更改,如果需要排序好的数据,请单独赋值。同时他的返回值是list类型【li = sorted(dict1)】
2.关于使用format进行格式化输出的时候。如果需要输出百分数,可以参考下面
# 输出没有全为整数的百分数
print('{:0%}'.format(11/12))
# 输出带有小数位数的百分数
print('{:3%}'.format(11/12))
请与输出带小数位数(非百分数)的格式做对比。输出的是百分数的时候不用加 f
# 普通的输出小数格式
print('{:3f}'.format(11/12))
但是,以上的这种小数点保留方式不完全符合四舍五入。
3、一维差分算法
首先介绍前缀和。前缀和在数列中就是前n项和。它在题目中的运用是“通过计算差分数列的前缀和,再与原数组对应相加,可以得到结果。”其中,原数组就是需要做修改的数组。
差分数列(d):用后一项减去前一项得到的差作为数列。
一维差分算法使用的前提:题目只进行一次询问(即不需要直到中间数据,只需要结果。询问的次数越多,差分时间复杂度越大,越容易失去使用意义),但是进行多次不同范围的数据操作。
一维差分算法的核心理论:
首先三个变量,L(left),R(right), val.这三个量代表了题目想对原数组的操作范围和具体的值。
其次需要知道,我们不直接对原数组进行操作,而是对差分数列d进行操作。尽管差分数列的定义是后一项与前一项的差,但是解题时,我们直接设全为0就行(按定义设也可以,只是部分计算过程需要变通)。设置全0的差分数列时,需要比原数组的位数多1位,否则之后的操作会出现越界。
核心公式:对d进行的操作是 d[L] += val; d[R+1] -= val;
为什么本是对一个范围进行操作,最后却只需要变动两位数据?
因为最后会对d进行前缀和操作,对于全0的d来说,从第一位发生变动的下标开始,一直到数组结尾所有的数据都会受到影响。因此d[R+1] -= val是为了控制影响不向后延续(左加右减),达到控制范围的作用。
最后把d和原数组相加就能得到原数组修改后的结果
例题:


解法1:暴力(此类问题均超时)
解法2:差分(此类问题最优解)
N, Q = input().split()
init_bgt = list(map(int, input().split()))
q = int(Q)
d = [0 for _ in range(int(N)+1)]
# 定义一个函数用于完成对差分数组的操作
def add(li, left, right, val):
li[left] += val
li[right+1] -= val
# 完成操作的输入
for i in range(q):
fuc = list(map(int, input().split()))
add(d, fuc[0]-1, fuc[1]-1, fuc[2])
# 对差分数组进行求前缀和
for j in range(len(d)):
if j == 0:
d[j] = d[j]
else:
d[j] += d[j-1]
# 输出结果
for k in range(len(init_bgt)):
init_bgt[k] += d[k]
if init_bgt[k] < 0:
print(0, end=' ')
else:
print(init_bgt[k], end=' ')4.LIS(最长上升子序列)问题的解决方法1(n²模板):
首先什么是LIS。LIS是指在一个无序数列中,找出同时满足升序、长度最长的子数列。
解决LIS问题的思路是:开辟一个数列用于记录每个元素的LIS。如[1,3,2,6,5,2]的LIS是[1,3,6]。
状态转移方程:每个位置上的元素都有两种可能。第一个就是自己是最开始元素,LIS=1.第二个是有前面的元素比这个位置上的元素小,可以被接在后面。(这种查找前面元素可不可接需要遍历,最后统计出所有接法中最长的那一个。每次都选最长的,结果就是最长的LIS)
状态转移方程式:f[i] = max(f[i], f[j] + 1) 这里的f列表便是用于记录每个元素的LIS
li = [1, 4, 2, 2, 5, 6]
f = [0 for i in range(len(li))] # f列表用于记录每个位置的LIS
for i in range(len(li)): # 第一层循环是真正的循环,顺便初始化每个位置上的LIS
f[i] = 1 # 进行初始化
for j in range(i): # 第二层循环是为了对i元素前的所有元素进行遍历,看看i位置的元素可不可以接在后面
if li[j] < li[i]:
f[i] = max(f[i], f[j] + 1)
f.sort()
print(f[-1])上述是LIS的基础算法,复杂度为O(n²)。很多题目中会超时,因此一般用下面这种通过二分加贪心优化后的算法,它的时间复杂度为O(nlogn)
5.LIS(最长上升子序列)问题的解决方法2(二分加贪心模板)
PS: 优化后是算法只能保证LIS的值是正确的,但是无法输出正确具体的数列
此算法分为两部分。第一部分需要写一个二分查找。
第二部分:此时算法中不再创建每个元素的LIS列表f,而是直接创建一个可能的LIS列表b(尽管最后这个列表并不正确,但列表长度和正确答案一致)。
原理是:每次向b列表中添加元素x。如果x大于最后b[-1],那就直接添加。如果小于b[-1],那通过二分查找,找出第一个大于x的元素,将其替换成x(这一步就不符合LIS的定义,因此说b不算正真的LIS序列,只是长度相同)。如果x等于b[-1],可以选择直接pass不管。
# 写一个二分查找
def binary_search(li, val):
left = 0
right = len(li) - 1
while left <= right:
mid = (left + right) // 2
if li[mid] > val:
right = mid - 1
elif li[mid] < val:
left = mid + 1
elif li[mid] == val:
return left
return left
li = [1, 4, 7, 7, 3, 4]
b = []
for i in range(len(li)):
if len(b) == 0 or li[i] > b[-1]: # 第一个数和之后大的数可以直接添加
b.append(li[i])
elif li[i] == b[-1]:
pass
else:
loc = binary_search(b, li[i])
b[loc] = li[i]
print(len(b)) # LIS的长度6、DP(动态规划)—0/1背包问题
0/1背包问题的标志是每个物品只可以不取或取一次,不允许重复多次取。背包问题有些像贪心算法,即每次都做出最好的选择,后一个结果又与前一个结果有关,最后得到的就是最好的结果。
背包问题需要一个二维列表,这个二维列表中存储的是每一次最好的结果(就是价值最大的)。
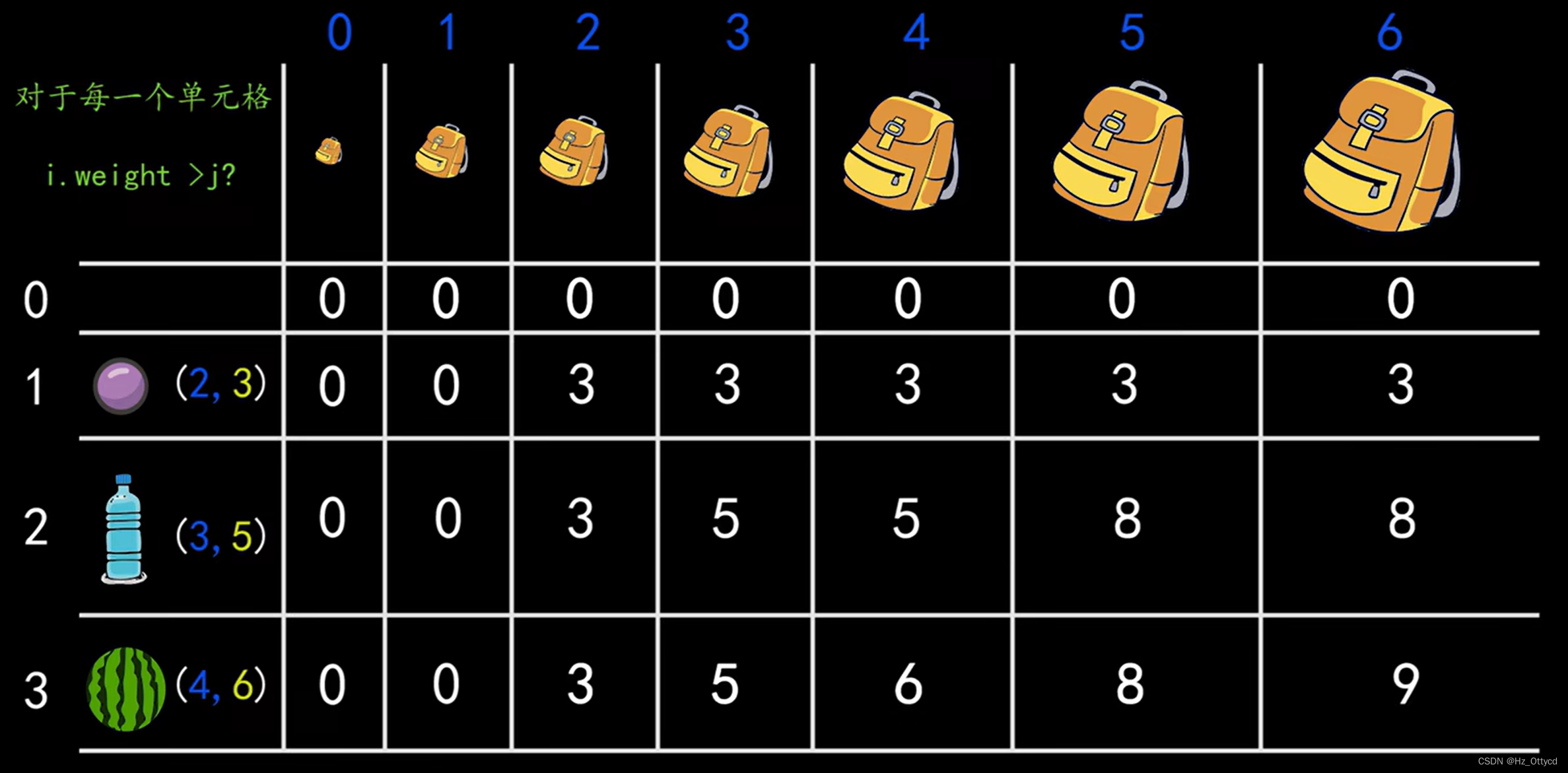
上面这个就是实现算法用的表,里面的数据是需要自己实现的。注意:这个表是横着填的,填完一行再填下一行。
首先说明表头:表的列的头部信息代表背包容量(图示0~6),行的头部信息是一个个元组,元组的第一位表示物品质量,第二位表示价值(这两个可以自行调整位置)。二维表中的元素表示当前背包容量下能够获得的最高价值。
那么,我们如何把二维表和两个表头建立联系?可以看出背包容量我们可以通过下标索引的值来实现(都是从0开始向后递增),但是元组却没有办法直接与列表相联。因此我们单独创建一个元组列表,用来存放每个物品的信息,然后将这个元组列表和二维列表相联系(通过索引可以实现两者之间必要值的比较,后面会解释)。做对应的时候,物品得从索引1开始,空出第一行,这是要求
然后是核心算法的文字解释:首先填写第一行,因为没有物品,所以第一行都填0。
再看(1,0)这个位置。因为背包容量小于物品质量2,所以继承上面一格(同一列)的值。(1,1)同样。这就是第一类情况,装不下,进行继承
当来到(1,2)时,背包容量和葡萄的质量2相当,因此可以装入葡萄。这是第二类情况,可以装下。第二类情况又分为两种。
一是选择不装,这就相当于第一类情况,直接进行继承。
二是选择装入。此时,背包的最大价值是当前物品的价值,加上,减去此物品质量后的背包容量,其对应的最大价值。【举个例子:如果背包容量为7,装了一个容量为3的物品,那么背包剩下容量4.此时背包的最大价值是,这个容量3物品的价值,加上背包容量为4时,前面所能够获得的最大价值。其实,这个价值一般是前一行对应的容量为4的背包价值,因为我们是一行一行填写的,而且每一个格子又是最优解,因此越在后面填的,其价格就越高】
当然,最后还是要对第二类情况的两种选择进行比较,以最大值为准。
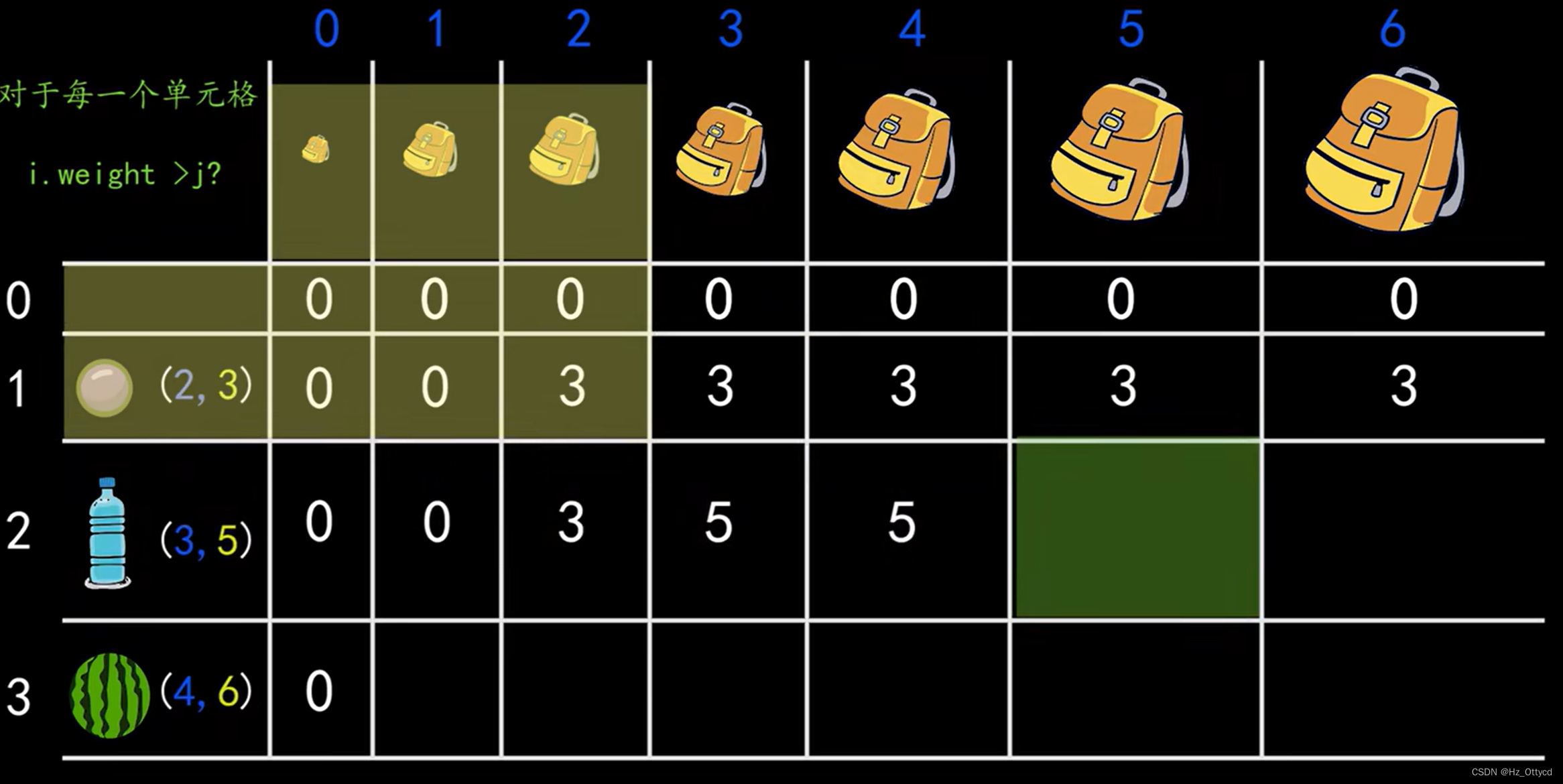
此图就表示了第二种情况种,选择装入的结果。背包容量为5,选择装入容量3的物品后,背包剩余容量2.这时候我们就要选择容量为2的时候,前面所有情况种,背包价值最大的(也就是3,他的坐标是(前一行,背包剩余容量))。最后这里要对两种情况进行比较max(3, 3+5),填入最大的。前一个是不装,后一个是装。
最后输出的结果实际上就是二维表的最右下角的那个值。
例题:


N, V = input().split()
n = int(N)
v = int(V)
items = [] # 创建一个用来存放每一个物品信息的列表
tu = [[0 for _ in range(v+1)] for _ in range(n+1)] # 创建一个二维列表
# 继续输入
for i in range(n):
item = tuple(map(int, input().split()))
items.append(item)
for j in range(1, n+1): # 外层循环表示行的推进
for k in range(1, v+1): # 内层循环表示列的推进
if k < items[j-1][0]: # 当背包容量小于此时的物品(就是这一行所代表的物品)
tu[j][k] = tu[j-1][k]
elif k >= items[j-1][0]: # 当背包容量大于此时的物品
tu[j][k] = max(tu[j-1][k], items[j-1][1] + tu[j-1][k-items[j-1][0]]) # 进行比较,选择要不要拿这个物品。前一个是不拿,后一个是拿
print(tu[n][-1])














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









