






最终效果图
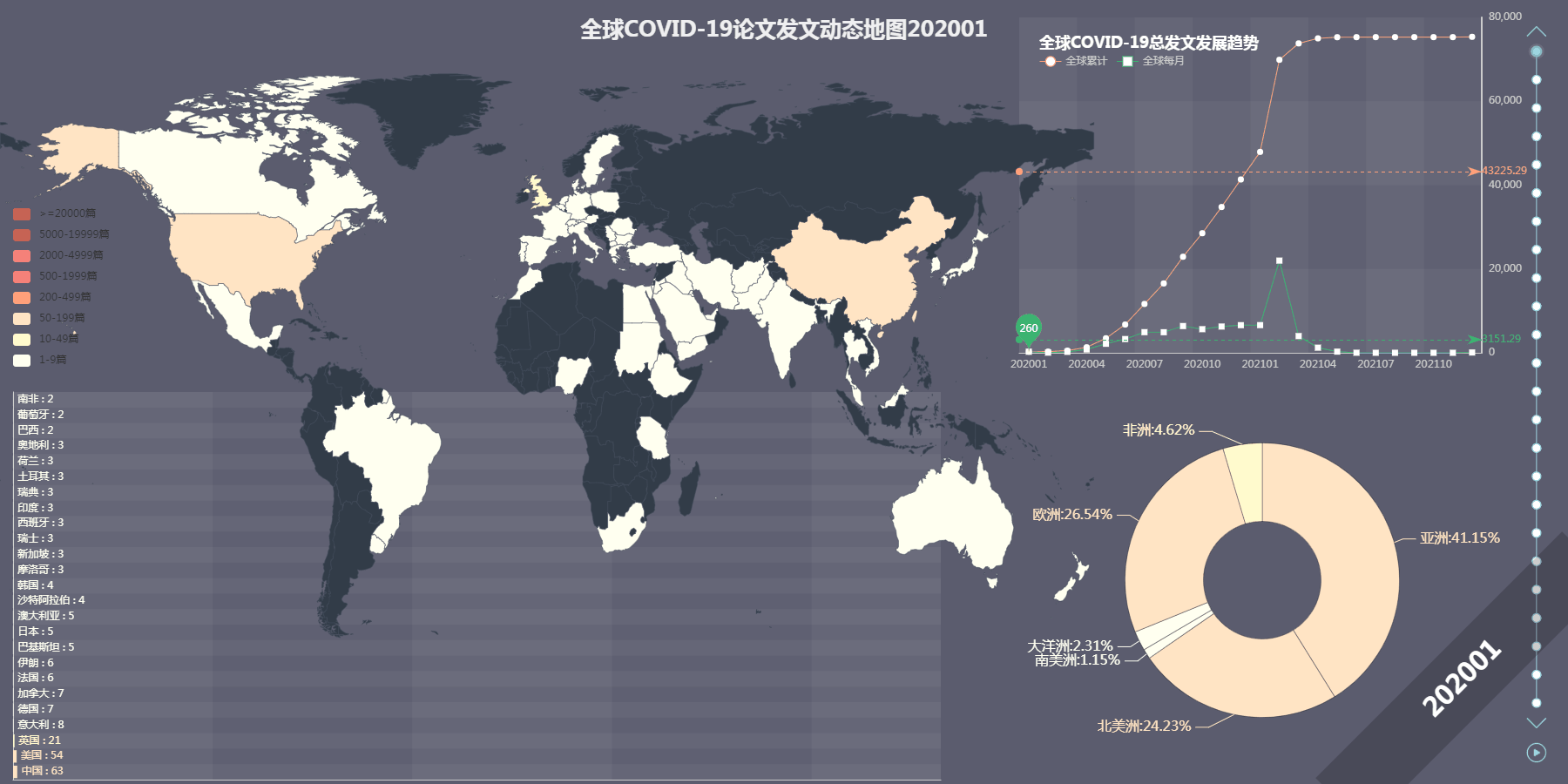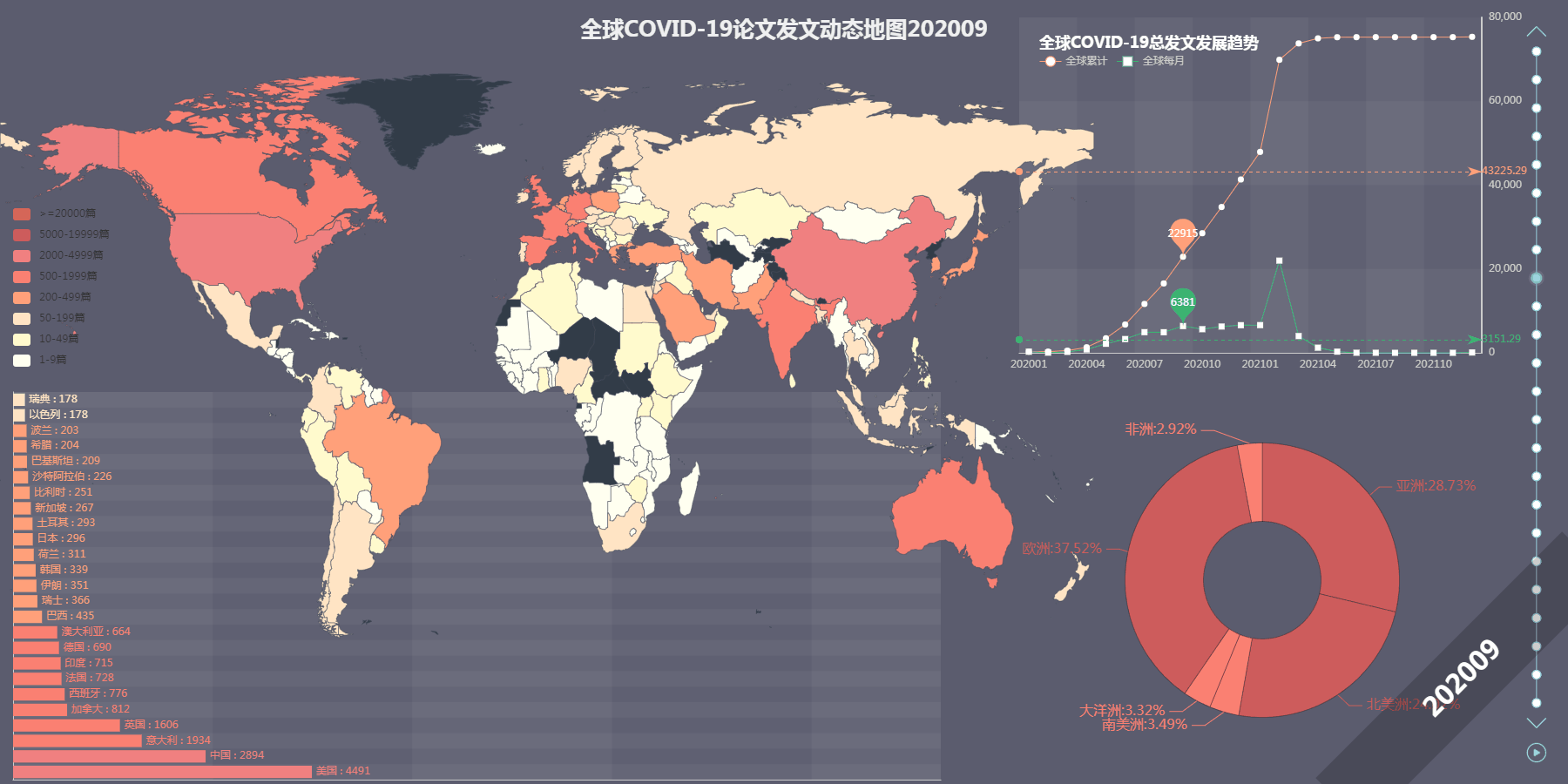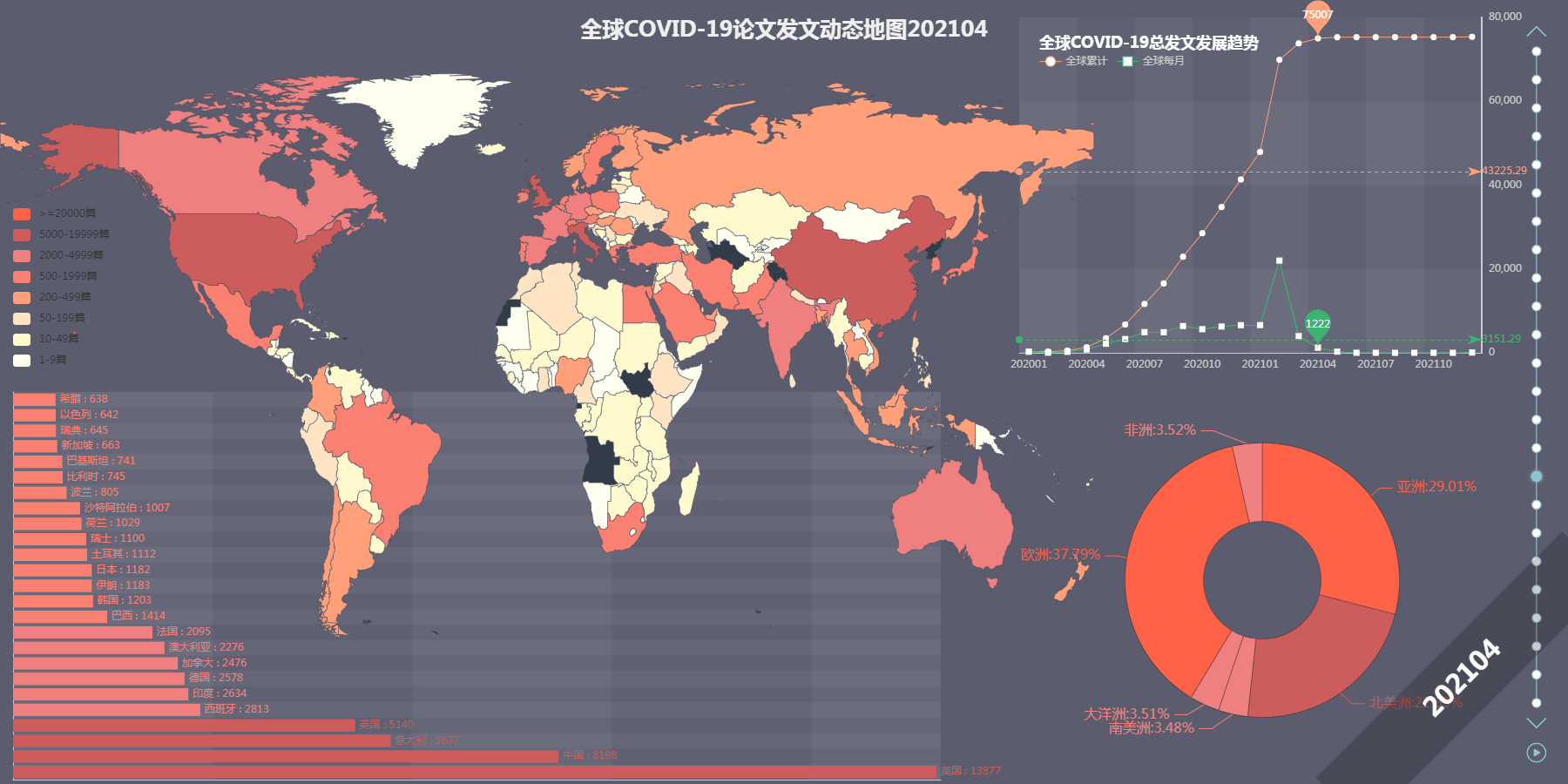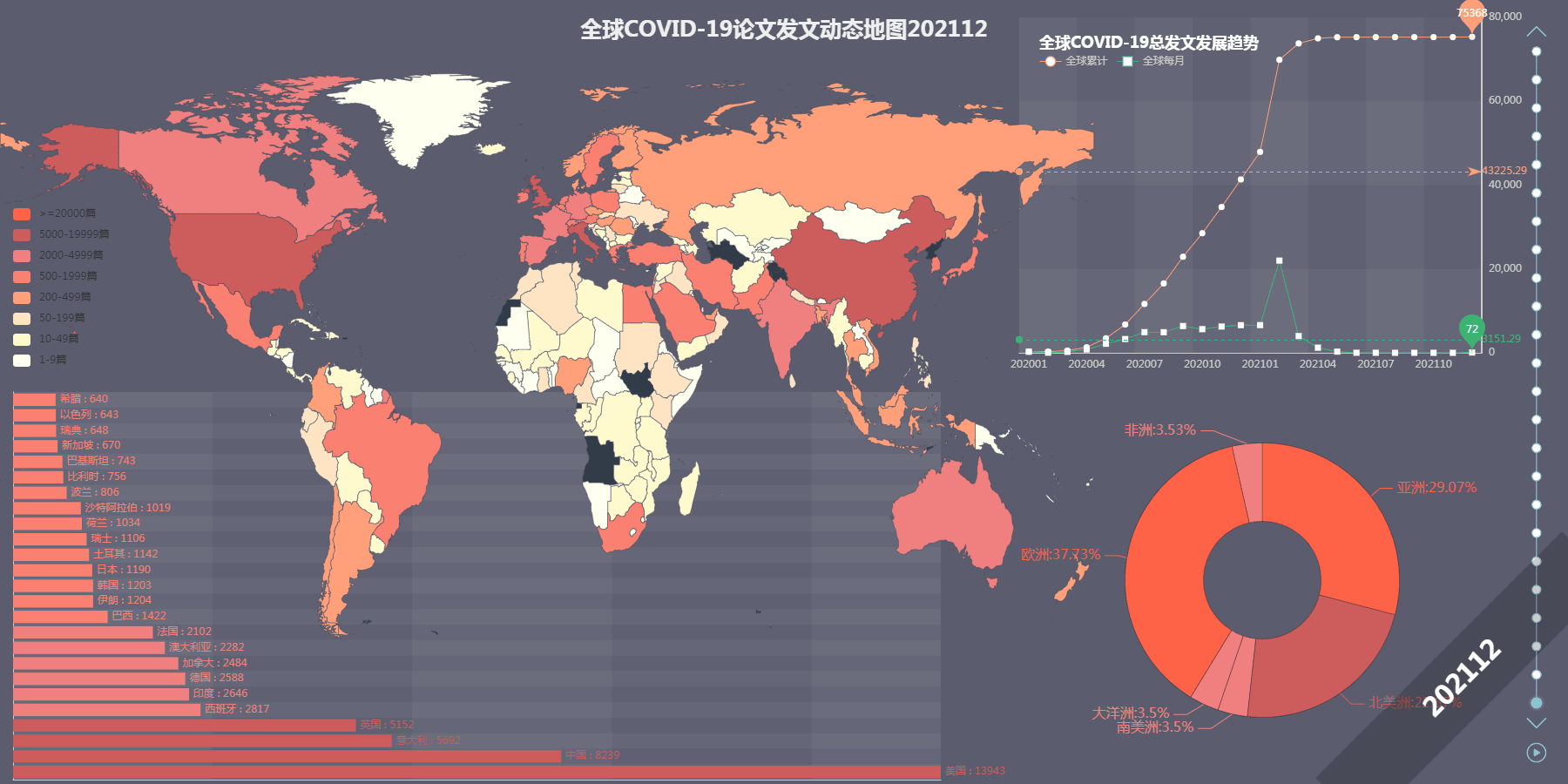
首先下载数据,本文以 Web of Science 核心合集为基础,选取以“COVID-19” 为主题的文章
将其汇总至一个csv文件中,选取想分析的列写入新的csv文件
import numpy as np
import csv
nd = np.genfromtxt('et01.csv', delimiter=',', skip_header=False)
list = nd.tolist()
for i in list:
print(list)
#
#
# for i in list:
# print(i)
# print(x)
imp = [5, 8, 9, 13, 19, 22, 23, 27, 30, 31, 32, 33, 34, 35, 36, 43, 44, 58]
with open('et01.csv', 'r') as cf:
reader = csv.reader(cf)
data = []
for item in reader:
flag = True
for i in imp:
if item[i] == '':
flag = False
if flag: data.append(item)
# for i in data:
# print(i)
cf.close()
# 1. 创建文件对象
f = open('et02.csv', 'w', newline='', encoding='GBK')
# 2. 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
for i in range(1,len(data)):
csv_writer.writerow([i[5], i[8], i[9], i[13], i[19], i[22], i[23], i[27], i[30], i[31],
i[32], i[33], i[34], i[35], i[36], i[43], i[44], i[58]])
然后对数据进行规范化,生成一个只有3列的csv文件(国家名,发文数,日期(月))
import numpy as np
import csv
with open('sj1-80690.csv', 'r', encoding='UTF-8') as cf:
reader = csv.reader(cf)
rows = -1
data = []
country = []
year = []
month = []
riqi = []
for i in reader:
rows += 1
data.append(i)
dicct={}#定义国家合作关系字典
for item in data[1:rows - 1]:
k = 0
C1 = item[4]
listct = [] # 定义国家名称列表
sum = 0
for i in C1[1:len(C1) - 1]:
k += 1
if i == '[':
k1 = k
ct = ''
while C1[k1] != '+':
k1 -= 1
for j in C1[k1 + 2:k - 2]:
ct += j
if 'china'.upper() in ct.upper():
ct = 'China'
elif 'usa'.upper() in ct.upper():
ct = 'United States'
elif 'U Arab Emirates'.upper() in ct.upper():
ct = 'United Arab Emirates'
elif 'ANTIGUA BARBU'.upper() in ct.upper():
ct = 'Antigua and Barb.'
elif 'bosnia herceg'.upper() in ct.upper():
ct = 'Bosnia and Herz.'
elif 'cent afr republ'.upper() in ct.upper():
ct = 'Central African Rep.'
elif 'cote ivoires'.upper() in ct.upper():
ct = "科特迪瓦"
elif 'czech republic'.upper() in ct.upper():
ct = 'Czech Rep.'
elif 'dem rep congo'.upper() in ct.upper():
ct = 'Dem. Rep. Congo'
elif 'eng'.upper() in ct.upper():
ct = 'United Kingdom'
elif 'england'.upper() in ct.upper():
ct = 'United Kingdom'
elif 'falkland island'.upper() in ct.upper():
ct = 'Falkland Is.'
elif 'guinea bissaus'.upper() in ct.upper():
ct = 'Guinea-Bissau'
elif 'laos'.upper() in ct.upper():
ct = 'Lao PDR'
elif 'north macedonia'.upper() in ct.upper():
ct = 'Macedonia'
elif 'north ireland'.upper() in ct.upper():
ct = 'Ireland'
elif 'north sudan'.upper() in ct.upper():
ct = 'Sudan'
elif 'papua n guinea'.upper() in ct.upper():
ct = 'Papua New Guinea'
elif 'scotland'.upper() in ct.upper():
ct = "United Kingdom"
elif 'solomon islands'.upper() in ct.upper():
ct = 'Solomon Is.'
elif 'south sudan'.upper() in ct.upper():
ct = '南苏丹'
elif 'timor leste'.upper() in ct.upper():
ct = 'Timor-Leste'
elif 'trinidad tobago'.upper() in ct.upper():
ct = 'Trinidad and Tobago'
elif 'united kingdom'.upper() in ct.upper():
ct = 'United Kingdom'
elif 'south korea'.upper() in ct.upper():
ct = 'Korea'
elif 'aruba'.upper() in ct.upper():
ct = 'Netherlands'
elif 'british virgin isl'.upper() in ct.upper():
ct = 'British Virgin Islands'
elif 'eswatini'.upper() in ct.upper():
ct = 'Swaziland'
elif 'french guiana'.upper() in ct.upper():
ct = 'Guyana'
elif 'kosovo'.upper() in ct.upper():
ct = 'Serbia'
elif 'ramon cajal uni'.upper() in ct.upper():
ct = 'Spain'
elif 'rep congo'.upper() in ct.upper():
ct = 'Congo'
elif 'st kitts nevi'.upper() in ct.upper():
ct = 'Saint Kitts and Nevis'
elif 'st lucia'.upper() in ct.upper():
ct = 'Saint Lucia'
elif 'vatican'.upper() in ct.upper():
ct = 'Vatican City'
elif 'taiwan'.upper() in ct.upper():
ct = 'China'
elif 'Dominican Rep' in ct:
ct = 'Dominican Rep.'
elif 'Bosnia & Herceg' in ct:
ct = 'Bosnia and Herz.'
elif 'Cote Ivoire' in ct:
ct = "科特迪瓦"
elif 'Wales' in ct:
ct = 'United Kingdom'
elif 'St Kitts & Nevi' in ct:
ct = 'Saint Kitts and Nevis'
elif 'Guinea Bissau' in ct:
ct = 'Guinea-Bissau'
elif 'BELARUS'.upper() in ct.upper():
ct = 'Belarus'
# print(i, end='')
# print(end=',')
f = True
for j in listct[0:sum]:
if 'china'.upper() in j.upper():
j = 'China'
elif 'usa'.upper() in j.upper():
j = 'United States'
elif 'U Arab Emirates'.upper() in j.upper():
j = 'United Arab Emirates'
elif 'ANTIGUA BARBU'.upper() in j.upper():
j = 'Antigua and Barb.'
elif 'bosnia herceg'.upper() in j.upper():
j = 'Bosnia and Herz.'
elif 'cent afr republ'.upper() in j.upper():
j = 'Central African Rep.'
elif 'cote ivoires'.upper() in j.upper():
j = "科特迪瓦"
elif 'czech republic'.upper() in j.upper():
j = 'Czech Rep.'
elif 'dem rep congo'.upper() in j.upper():
j = 'Dem. Rep. Congo'
elif 'eng'.upper() in j.upper():
j = 'United Kingdom'
elif 'england'.upper() in j.upper():
j = 'United Kingdom'
elif 'falkland island'.upper() in j.upper():
j = 'Falkland Is.'
elif 'guinea bissaus'.upper() in j.upper():
j = 'Guinea-Bissau'
elif 'laos'.upper() in j.upper():
j = 'Lao PDR'
elif 'north macedonia'.upper() in j.upper():
j = 'Macedonia'
elif 'north ireland'.upper() in j.upper():
j = 'Ireland'
elif 'north sudan'.upper() in j.upper():
j = 'Sudan'
elif 'papua n guinea'.upper() in j.upper():
j = 'Papua New Guinea'
elif 'scotland'.upper() in j.upper():
j = "United Kingdom"
elif 'solomon islands'.upper() in j.upper():
j = 'Solomon Is.'
elif 'south sudan'.upper() in j.upper():
j = '南苏丹'
elif 'timor leste'.upper() in j.upper():
j = 'Timor-Leste'
elif 'trinidad tobago'.upper() in j.upper():
j = 'Trinidad and Tobago'
elif 'united kingdom'.upper() in j.upper():
j = 'United Kingdom'
elif 'south korea'.upper() in j.upper():
j = 'Korea'
elif 'aruba'.upper() in j.upper():
j = 'Netherlands'
elif 'british virgin isl'.upper() in j.upper():
j = 'British Virgin Islands'
elif 'eswatini'.upper() in j.upper():
j = 'Swaziland'
elif 'french guiana'.upper() in j.upper():
j = 'Guyana'
elif 'kosovo'.upper() in j.upper():
j = 'Serbia'
elif 'ramon cajal uni'.upper() in j.upper():
j = 'Spain'
elif 'rep congo'.upper() in j.upper():
j = 'Congo'
elif 'st kitts nevi'.upper() in j.upper():
j = 'Saint Kitts and Nevis'
elif 'st lucia'.upper() in j.upper():
j = 'Saint Lucia'
elif 'vatican'.upper() in j.upper():
j = 'Vatican City'
elif 'taiwan'.upper() in j.upper():
j = 'China'
elif 'Dominican Rep' in j:
j = 'Dominican Rep.'
elif 'Bosnia & Herceg' in j:
j = 'Bosnia and Herz.'
elif 'Cote Ivoire' in j:
j = "科特迪瓦"
elif 'Wales' in j:
j = 'United Kingdom'
elif 'St Kitts & Nevi' in j:
j = 'Saint Kitts and Nevis'
elif 'Guinea Bissau' in j:
j = 'Guinea-Bissau'
elif 'BELARUS'.upper() in j.upper():
j = 'Belarus'
if j == ct:
f = False
if f:
sum += 1
listct.append(ct)
ct = ''
k = len(C1) - 1
k1 = k
while C1[k1] != '+':
k1 -= 1
for i in C1[k1 + 2:k + 1]:
ct += i
if 'china'.upper() in ct.upper():
ct = 'China'
elif 'usa'.upper() in ct.upper():
ct = 'United States'
elif 'U Arab Emirates'.upper() in ct.upper():
ct = 'United Arab Emirates'
elif 'ANTIGUA BARBU'.upper() in ct.upper():
ct = 'Antigua and Barb.'
elif 'bosnia herceg'.upper() in ct.upper():
ct = 'Bosnia and Herz.'
elif 'cent afr republ'.upper() in ct.upper():
ct = 'Central African Rep.'
elif 'cote ivoires'.upper() in ct.upper():
ct = "科特迪瓦"
elif 'czech republic'.upper() in ct.upper():
ct = 'Czech Rep.'
elif 'dem rep congo'.upper() in ct.upper():
ct = 'Dem. Rep. Congo'
elif 'eng'.upper() in ct.upper():
ct = 'United Kingdom'
elif 'england'.upper() in ct.upper():
ct = 'United Kingdom'
elif 'falkland island'.upper() in ct.upper():
ct = 'Falkland Is.'
elif 'guinea bissaus'.upper() in ct.upper():
ct = 'Guinea-Bissau'
elif 'laos'.upper() in ct.upper():
ct = 'Lao PDR'
elif 'north macedonia'.upper() in ct.upper():
ct = 'Macedonia'
elif 'north ireland'.upper() in ct.upper():
ct = 'Ireland'
elif 'north sudan'.upper() in ct.upper():
ct = 'Sudan'
elif 'papua n guinea'.upper() in ct.upper():
ct = 'Papua New Guinea'
elif 'scotland'.upper() in ct.upper():
ct = "United Kingdom"
elif 'solomon islands'.upper() in ct.upper():
ct = 'Solomon Is.'
elif 'south sudan'.upper() in ct.upper():
ct = '南苏丹'
elif 'timor leste'.upper() in ct.upper():
ct = 'Timor-Leste'
elif 'trinidad tobago'.upper() in ct.upper():
ct = 'Trinidad and Tobago'
elif 'united kingdom'.upper() in ct.upper():
ct = 'United Kingdom'
elif 'south korea'.upper() in ct.upper():
ct = 'Korea'
elif 'aruba'.upper() in ct.upper():
ct = 'Netherlands'
elif 'british virgin isl'.upper() in ct.upper():
ct = 'British Virgin Islands'
elif 'eswatini'.upper() in ct.upper():
ct = 'Swaziland'
elif 'french guiana'.upper() in ct.upper():
ct = 'Guyana'
elif 'kosovo'.upper() in ct.upper():
ct = 'Serbia'
elif 'ramon cajal uni'.upper() in ct.upper():
ct = 'Spain'
elif 'rep congo'.upper() in ct.upper():
ct = 'Congo'
elif 'st kitts nevi'.upper() in ct.upper():
ct = 'Saint Kitts and Nevis'
elif 'st lucia'.upper() in ct.upper():
ct = 'Saint Lucia'
elif 'vatican'.upper() in ct.upper():
ct = 'Vatican City'
elif 'taiwan'.upper() in ct.upper():
ct = 'China'
elif 'Dominican Rep' in ct:
ct = 'Dominican Rep.'
elif 'Bosnia & Herceg' in ct:
ct = 'Bosnia and Herz.'
elif 'Cote Ivoire' in ct:
ct = "科特迪瓦"
elif 'Wales' in ct:
ct = 'United Kingdom'
elif 'St Kitts & Nevi' in ct:
ct = 'Saint Kitts and Nevis'
elif 'Guinea Bissau' in ct:
ct = 'Guinea-Bissau'
elif 'BELARUS'.upper() in ct.upper():
ct = 'Belarus'
f = True
for j in listct[0:sum]:
if 'china'.upper() in j.upper():
j = 'China'
elif 'usa'.upper() in j.upper():
j = 'United States'
elif 'U Arab Emirates'.upper() in j.upper():
j = 'United Arab Emirates'
elif 'ANTIGUA BARBU'.upper() in j.upper():
j = 'Antigua and Barb.'
elif 'bosnia herceg'.upper() in j.upper():
j = 'Bosnia and Herz.'
elif 'cent afr republ'.upper() in j.upper():
j = 'Central African Rep.'
elif 'cote ivoires'.upper() in j.upper():
j = "科特迪瓦"
elif 'czech republic'.upper() in j.upper():
j = 'Czech Rep.'
elif 'dem rep congo'.upper() in j.upper():
j = 'Dem. Rep. Congo'
elif 'eng'.upper() in j.upper():
j = 'United Kingdom'
elif 'england'.upper() in j.upper():
j = 'United Kingdom'
elif 'falkland island'.upper() in j.upper():
j = 'Falkland Is.'
elif 'guinea bissaus'.upper() in j.upper():
j = 'Guinea-Bissau'
elif 'laos'.upper() in j.upper():
j = 'Lao PDR'
elif 'north macedonia'.upper() in j.upper():
j = 'Macedonia'
elif 'north ireland'.upper() in j.upper():
j = 'Ireland'
elif 'north sudan'.upper() in j.upper():
j = 'Sudan'
elif 'papua n guinea'.upper() in j.upper():
j = 'Papua New Guinea'
elif 'scotland'.upper() in j.upper():
j = "United Kingdom"
elif 'solomon islands'.upper() in j.upper():
j = 'Solomon Is.'
elif 'south sudan'.upper() in j.upper():
j = '南苏丹'
elif 'timor leste'.upper() in j.upper():
j = 'Timor-Leste'
elif 'trinidad tobago'.upper() in j.upper():
j = 'Trinidad and Tobago'
elif 'united kingdom'.upper() in j.upper():
j = 'United Kingdom'
elif 'south korea'.upper() in j.upper():
j = 'Korea'
elif 'aruba'.upper() in j.upper():
j = 'Netherlands'
elif 'british virgin isl'.upper() in j.upper():
j = 'British Virgin Islands'
elif 'eswatini'.upper() in j.upper():
j = 'Swaziland'
elif 'french guiana'.upper() in j.upper():
j = 'Guyana'
elif 'kosovo'.upper() in j.upper():
j = 'Serbia'
elif 'ramon cajal uni'.upper() in j.upper():
j = 'Spain'
elif 'rep congo'.upper() in j.upper():
j = 'Congo'
elif 'st kitts nevi'.upper() in j.upper():
j = 'Saint Kitts and Nevis'
elif 'st lucia'.upper() in j.upper():
j = 'Saint Lucia'
elif 'vatican'.upper() in j.upper():
j = 'Vatican City'
elif 'taiwan'.upper() in j.upper():
j = 'China'
elif 'Dominican Rep' in j:
j = 'Dominican Rep.'
elif 'Bosnia & Herceg' in j:
j = 'Bosnia and Herz.'
elif 'Cote Ivoire' in j:
j = "科特迪瓦"
elif 'Wales' in j:
j = 'United Kingdom'
elif 'St Kitts & Nevi' in j:
j = 'Saint Kitts and Nevis'
elif 'Guinea Bissau' in j:
j = 'Guinea-Bissau'
elif 'BELARUS'.upper() in j.upper():
j = 'Belarus'
if j == ct:
f = False
if f:
sum += 1
listct.append(ct)
for i in range(len(listct)):
country.append(listct[i])
year.append(item[11])
month.append(item[10])
print(len(year))
print(month)
print(len(country))
#清洗时间数据
for i in range (len(year)):
if '1905/7/12' in year[i]:
year[i] = '2020'
for i in range(len(month)):
if 'jan'.upper() in month[i].upper():
month[i]='01'
elif 'feb'.upper() in month[i].upper():
month[i]='02'
elif 'mar'.upper() in month[i].upper():
month[i]='03'
elif 'apr'.upper() in month[i].upper():
month[i]='04'
elif 'may'.upper() in month[i].upper():
month[i]='05'
elif 'jun'.upper() in month[i].upper():
month[i]='06'
elif 'jul'.upper() in month[i].upper():
month[i]='07'
elif 'aug'.upper() in month[i].upper():
month[i]='08'
elif 'sep'.upper() in month[i].upper():
month[i]='09'
elif 'oct'.upper() in month[i].upper():
month[i]='10'
elif 'nov'.upper() in month[i].upper():
month[i]='11'
elif 'dec'.upper() in month[i].upper():
month[i]='12'
elif 'sum'.upper() in month[i].upper():
month[i]='06'
elif 'win'.upper() in month[i].upper():
month[i]='12'
elif 'fal'.upper() in month[i].upper():
month[i]='09'
elif 'spr'.upper() in month[i].upper():
month[i]='03'
#print(month)
for i in range(len(month)):
riqi.append(year[i]+month[i])
#print(riqi)
for i in range(len(month)):
riqi[i]=int(riqi[i])
#清洗国家
for i in range(len(country)):
country[i] = country[i].strip()
print(country)
#日期计数
dict={}
time0=[202001,202002,202003,202004,202005,202006,202007,202008,202009,202010,202011,202012,202101,202102,202103,202104,202105,202106,202107,202108,202109,202110,202111,202112]
country0=['Somalia','Liechtenstein','Morocco','W. Sahara','Serbia','Afghanistan','Angola','Albania','Andorra','United Arab Emirates','Argentina','Armenia','Australia','Austria','Azerbaijan','Burundi','Belgium','Benin','Burkina Faso','Bangladesh','Bulgaria','Bahrain','Bahamas','Bosnia and Herz.','Belarus','Belize','Bermuda','Bolivia','Brazil','Barbados','Brunei','Bhutan','Botswana','Central African Rep.','Canada','Switzerland','Chile','China','Côte d’Ivoire','Cameroon','Dem. Rep. Congo','Congo','Colombia','Cape Verde','Costa Rica','Cuba','N. Cyprus','Cyprus','Czech Rep.','Germany','Djibouti','Denmark','Dominican Rep.','Algeria','Ecuador','Egypt','Eritrea','Spain','Estonia','Ethiopia','Finland','Fiji','France','Gabon','United Kingdom','Georgia','Ghana','Guinea','Gambia','Guinea-Bissau','Eq. Guinea','Greece','Grenada','Greenland','Guatemala','Guam','Guyana','Honduras','Croatia','Haiti','Hungary','Indonesia','India','Br.Indian Ocean Ter.','Ireland','Iran','Iraq','Iceland','Israel','Italy','Jamaica','Jordan','Japan','Siachen Glacier','Kazakhstan','Kenya','Kyrgyzstan','Cambodia','Korea','Kuwait','Lao PDR','Lebanon','Liberia','Libya','Sri Lanka','Lesotho','Lithuania','Luxembourg','Latvia','Moldova','Madagascar','Mexico','Macedonia','Mali','Malta','Myanmar','Montenegro','Mongolia','Mozambique','Mauritania','Mauritius','Malawi','Malaysia','Namibia','New Caledonia','Niger','Nigeria','Nicaragua','Netherlands','Norway','Nepal','New Zealand','Oman','Pakistan','Panama','Peru','Philippines','Papua New Guinea','Poland','Puerto Rico','Dem. Rep. Korea','Portugal','Paraguay','Palestine','Qatar','Romania','Russia','Rwanda','Saudi Arabia','Sudan','S. Sudan','Senegal','Singapore','Solomon Is.','Sierra Leone','El Salvador','Suriname','Slovakia','Slovenia','Sweden','Swaziland','Seychelles','Syria','Chad','Togo','Thailand','Tajikistan','Turkmenistan','Timor-Leste','Tonga','Trinidad and Tobago','Tunisia','Turkey','Tanzania','Uganda','Ukraine','Uruguay','United States','Uzbekistan','Venezuela','Vietnam','Vanuatu','Yemen','South Africa','Zambia','Zimbabwe','Aland','American Samoa','Fr. S. Antarctic Lands','Antigua and Barb.','Comoros','Curaçao','Cayman Is.','Dominica','Falkland Is.','Faeroe Is.','Micronesia','Heard I. and McDonald Is.','Isle of Man','Jersey','Kiribati','Saint Lucia','N. Mariana Is.','Montserrat','Niue','Palau','Fr. Polynesia','S. Geo. and S. Sandw. Is.','Saint Helena','St. Pierre and Miquelon','São Tomé and Principe','Turks and Caicos Is.','St. Vin. and Gren.','U.S. Virgin Is.','Samoa']
for time in time0:
t = repr(time)
for i in range(len(country)):
if riqi[i] == time :
ct=country[i]+'_'+t
if ct in dict:
dict[ct]=dict[ct]+1
else:
dict[ct] = 1
print(dict)
# #检验dict
# jydict0 = 0
# jydict1 = 0
# for i in dict:
# if 'China' in i:
# jydict1 += dict[i]
# for i in country:
# if 'China' == i:
# jydict0+=1
# print(jydict1)
# print(jydict0)
#存放数据
f_country= []
f_time = []
f_count = []
for key in dict:
f_country.append(key.split('_')[0])
f_time.append(key.split('_')[1])
f_count.append(dict[key])
print('结果')
print(f_country)
print(f_time)
print(f_count)
time0 = [202001, 202002, 202003, 202004, 202005, 202006, 202007, 202008, 202009, 202010, 202011, 202012, 202101,
202102, 202103, 202104, 202105, 202106, 202107, 202108, 202109, 202110, 202111, 202112]
list1 = []
for month in time0:
jishu = 0
for i in range(len(f_time)):
if int(f_time[i]) == month:
jishu += f_count[i]
list1.append(jishu)
print(list1)
#
# # 年度数据
# dicty = {}
# timey = list(range(2019, 2022))
# for time in timey:
# ty = repr(time)
# for i in range(len(country)):
# if ty in repr(riqi[i]):
# cty = country[i] + '_' + ty
# if cty in dicty:
# dicty[cty] = dicty[cty] + 1
# else:
# dicty[cty] = 1
# print('dicty:')
# print((dicty))
#存放数据
# fy_country = []
# fy_time = []
# fy_count = []
# for key in dicty:
# fy_country.append(key.split('_')[0])
# fy_time.append(key.split('_')[1])
# fy_count.append(dicty[key])
# print('结果')
# print(fy_country)
# print(fy_time)
# print(fy_count)
# print(len(fy_country))
name_map = {'Liechtenstein': '列支敦士登', 'Morocco': '摩洛哥', 'W. Sahara': '西撒哈拉', 'Serbia': '塞尔维亚', 'Afghanistan': '阿富汗',
'Angola': '安哥拉', 'Albania': '阿尔巴尼亚', 'Aland': '奥兰群岛', 'Andorra': '安道尔',
'United Arab Emirates': '阿联酋', 'Argentina': '阿根廷', 'Armenia': '亚美尼亚', 'American Samoa': '美属萨摩亚',
'Fr. S. Antarctic Lands': '法属南半球和南极领地', 'Antigua and Barb.': '安提瓜和巴布达', 'Australia': '澳大利亚',
'Austria': '奥地利', 'Azerbaijan': '阿塞拜疆', 'Burundi': '布隆迪', 'Belgium': '比利时', 'Benin': '贝宁',
'Burkina Faso': '布基纳法索', 'Bangladesh': '孟加拉国', 'Bulgaria': '保加利亚', 'Bahrain': '巴林', 'Bahamas': '巴哈马',
'Bosnia and Herz.': '波黑', 'Belarus': '白俄罗斯', 'Belize': '伯利兹', 'Bermuda': '百慕大', 'Bolivia': '玻利维亚',
'Brazil': '巴西', 'Barbados': '巴巴多斯', 'Brunei': '文莱', 'Bhutan': '不丹', 'Botswana': '博茨瓦纳',
'Central African Rep.': '中非', 'Canada': '加拿大', 'Switzerland': '瑞士', 'Chile': '智利', 'China': '中国',
"Côte d'Ivoire": '科特迪瓦', 'Cameroon': '喀麦隆', 'Dem. Rep. Congo': '刚果(布)', 'Congo': '刚果(金)',
'Colombia': '哥伦比亚', 'Comoros': '科摩罗', 'Cape Verde': '佛得角', 'Costa Rica': '哥斯达黎加', 'Cuba': '古巴',
'Curaçao': '库拉索', 'Cayman Is.': '开曼群岛', 'N. Cyprus': '北塞浦路斯', 'Cyprus': '塞浦路斯', 'Czech Rep.': '捷克',
'Germany': '德国', 'Djibouti': '吉布提', 'Denmark': '丹麦', 'Dominican Rep.': '多米尼加',
'Algeria': '阿尔及利亚', 'Ecuador': '厄瓜多尔', 'Egypt': '埃及', 'Eritrea': '厄立特里亚', 'Spain': '西班牙',
'Estonia': '爱沙尼亚', 'Ethiopia': '埃塞俄比亚', 'Finland': '芬兰', 'Fiji': '斐济', 'Falkland Is.': '福克兰群岛(马尔维纳斯)',
'France': '法国', 'Faeroe Is.': '法罗群岛', 'Micronesia': '密克罗尼西亚', 'Gabon': '加蓬', 'United Kingdom': '英国',
'Georgia': '格鲁吉亚', 'Ghana': '加纳', 'Guinea': '几内亚', 'Gambia': '冈比亚', 'Guinea-Bissau': '几内亚比绍',
'Eq. Guinea': '赤道几内亚', 'Greece': '希腊', 'Grenada': '格林纳达', 'Greenland': '格陵兰', 'Guatemala': '危地马拉',
'Guam': '关岛', 'Heard I. and McDonald Is.': '赫德岛和麦克唐纳群岛', 'Honduras': '洪都拉斯',
'Croatia': '克罗地亚', 'Haiti': '海地', 'Hungary': '匈牙利', 'Indonesia': '印度尼西亚', 'Isle of Man': '英国属地曼岛',
'India': '印度', 'Br. Indian Ocean Ter.': '英属印度洋领土', 'Ireland': '爱尔兰', 'Iran': '伊朗', 'Iraq': '伊拉克',
'Iceland': '冰岛', 'Israel': '以色列', 'Italy': '意大利', 'Jamaica': '牙买加', 'Jersey': '泽西岛', 'Jordan': '约旦',
'Japan': '日本', 'Siachen Glacier': '锡亚琴冰川', 'Kazakhstan': '哈萨克斯坦', 'Kenya': '肯尼亚',
'Kyrgyzstan': '吉尔吉斯斯坦', 'Cambodia': '柬埔寨', 'Kiribati': '基里巴斯', 'Korea': '韩国', 'Kuwait': '科威特',
'Lao PDR': '老挝', 'Lebanon': '黎巴嫩', 'Liberia': '利比里亚', 'Libya': '利比亚', 'Saint Lucia': '圣卢西亚',
'Sri Lanka': '斯里兰卡', 'Lesotho': '莱索托', 'Lithuania': '立陶宛', 'Luxembourg': '卢森堡', 'Latvia': '拉脱维亚',
'Moldova': '摩尔多瓦', 'Madagascar': '马达加斯加', 'Mexico': '墨西哥', 'Macedonia': '北马其顿', 'Mali': '马里',
'Malta': '马耳他', 'Myanmar': '缅甸', 'Montenegro': '黑山', 'Mongolia': '蒙古', 'N. Mariana Is.': '北马里亚纳',
'Mozambique': '莫桑比克', 'Mauritania': '毛利塔尼亚', 'Montserrat': '蒙特塞拉特', 'Mauritius': '毛里求斯',
'Malawi': '马拉维', 'Malaysia': '马来西亚', 'Namibia': '纳米比亚', 'New Caledonia': '新喀里多尼亚', 'Niger': '尼日尔',
'Nigeria': '尼日利亚', 'Nicaragua': '尼加拉瓜', 'Niue': '纽埃', 'Netherlands': '荷兰', 'Norway': '挪威',
'Nepal': '尼泊尔', 'New Zealand': '新西兰', 'Oman': '阿曼', 'Pakistan': '巴基斯坦', 'Panama': '巴拿马', 'Peru': '秘鲁',
'Philippines': '菲律宾', 'Palau': '帕劳', 'Papua New Guinea': '巴布亚新几内亚', 'Poland': '波兰',
'Puerto Rico': '波多黎各', 'Dem. Rep. Korea': '朝鲜', 'Portugal': '葡萄牙', 'Paraguay': '巴拉圭',
'Palestine': '巴勒斯坦', 'Fr. Polynesia': '法属波利尼西亚', 'Qatar': '卡塔尔', 'Romania': '罗马尼亚', 'Russia': '俄罗斯',
'Rwanda': '卢旺达', 'Saudi Arabia': '沙特阿拉伯', 'Sudan': '苏丹', 'S. Sudan': '南苏丹', 'Senegal': '塞内加尔',
'Singapore': '新加坡', 'S. Geo. and S. Sandw. Is.': '南乔治亚岛和南桑威奇群岛', 'Saint Helena': '圣赫勒拿',
'Solomon Is.': '所罗门群岛', 'Sierra Leone': '塞拉利昂', 'El Salvador': '萨尔瓦多',
'St. Pierre and Miquelon': '圣皮埃尔和密克隆', 'São Tomé and Principe': '圣多美和普林西比', 'Suriname': '苏里南',
'Slovakia': '斯洛伐克', 'Slovenia': '斯洛文尼亚', 'Sweden': '瑞典', 'Swaziland': '斯威士兰', 'Seychelles': '塞舌尔',
'Syria': '叙利亚', 'Turks and Caicos Is.': '特克斯和凯科斯群岛', 'Chad': '乍得', 'Togo': '多哥', 'Thailand': '泰国',
'Tajikistan': '塔吉克斯坦', 'Turkmenistan': '土库曼斯坦', 'Timor-Leste': '东帝汶', 'Tonga': '汤加',
'Trinidad and Tobago': '特立尼达和多巴哥', 'Tunisia': '突尼斯', 'Turkey': '土耳其', 'Tanzania': '坦桑尼亚',
'Uganda': '乌干达', 'Ukraine': '乌克兰', 'Uruguay': '乌拉圭', 'United States': '美国', 'Uzbekistan': '乌兹别克斯坦',
'St. Vin. and Gren.': '圣文森特和格林纳丁斯', 'Venezuela': '委内瑞拉', 'U.S. Virgin Is.': '美属维尔京群岛', 'Vietnam': '越南',
'Vanuatu': '瓦努阿图', 'Samoa': '萨摩亚', 'Yemen': '也门', 'South Africa': '南非', 'Zambia': '赞比亚',
'Zimbabwe': '津巴布韦', 'Somalia': '索马里', "Anguilla": "安圭拉", 'Dominica': '多米尼克', 'Gibraltar': '直布罗陀',
'Guyana': '圭亚那', 'Saint Kitts and Nevis': '圣基茨和尼维斯', 'Monaco': '摩纳哥', 'Maldives': '马尔代夫',
'San Marino': '圣马力诺',
'Vatican City': '梵蒂冈', 'British Virgin Islands': '英属维尔京群岛'}
for i in range(len(f_country)):
for key in name_map:
if f_country[i] == key:
f_country[i]=name_map[key]
#
with open('exmap.csv','w',newline='',encoding='utf-8') as f:
# 2. 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
# 3. 构建列表头
csv_writer.writerow(["country","count","date"])
# 4. 写入csv文件内容
for i in range(len(f_country)):
csv_writer.writerow([f_country[i],f_count[i],f_time[i]])
# 5. 关闭文件
f.close()
在对国家进行统一命名的时候由于一开始思路没想好导致写出了如此冗余的代码,后续可以进行修改
接下来将当月计数改为累计计数,因为最终要表现的主题用累计值更好一些
import pandas as pd
import csv
country = []
date = []
count = []
df = pd.read_csv('exmap.csv') # 读取数据
for i in df['country']:
country.append(i)
for i in df['count']:
count.append(i)
for i in df['date']:
date.append(i)
print(len(date))
print(len(count))
print((len(country)))
ct=[]
for i in range(len(country)):
ct.append(country[i]+'+'+str(date[i]))
dict={}
for i in range(len(ct)):
dict[ct[i]]=count[i]
for i in range(len(ct)):
if '中国' in ct[i]:
print(ct[i])
print(count[i])
cou=['中国', '蒙古', '朝鲜', '韩国', '日本', '菲律宾', '越南', '老挝', '柬埔寨', '缅甸', '泰国', '马来西亚', '文莱', '新加坡', '印度尼西亚', '东帝汶',
'尼泊尔','不丹', '孟加拉国', '印度', '巴基斯坦', '斯里兰卡', '马尔代夫', '哈萨克斯坦', '吉尔吉斯斯坦', '塔吉克斯坦', '乌兹别克斯坦', '土库曼斯坦', '阿富汗',
'伊拉克','伊朗', '北马里亚纳','叙利亚', '约旦', '黎巴嫩', '以色列', '巴勒斯坦', '沙特阿拉伯', '巴林', '卡塔尔', '科威特', '阿联酋', '阿曼', '也门', '格鲁吉亚',
'亚美尼亚','阿塞拜疆','土耳其','英国', '法国', '荷兰', '爱尔兰', '比利时', '卢森堡', '摩纳哥', '丹麦', '挪威', '瑞典', '芬兰', '冰岛', '罗马尼亚', '保加利亚', '塞尔维亚', '黑山',
'北马其顿', '阿尔巴尼亚', '希腊', '斯洛文尼亚', '克罗地亚', '波黑', '意大利', '梵蒂冈', '圣马力诺', '马耳他', '西班牙', '葡萄牙', '安道尔',
'塞浦路斯', '波兰', '捷克', '斯洛伐克', '奥地利', '匈牙利', '德国', '瑞士', '列支敦士登', '爱沙尼亚', '拉脱维亚', '立陶宛', '白俄罗斯', '俄罗斯',
'乌克兰', '泽西岛','摩尔多瓦', '海峡群岛', '福克兰群岛(马尔维纳斯)', '英国属地曼岛', '圣马丁', '法罗群岛', '直布罗陀','埃及', '利比亚', '突尼斯', '阿尔及利亚', '摩洛哥', '埃塞俄比亚', '厄立特里亚', '索马里', '吉布提', '肯尼亚', '坦桑尼亚', '乌干达', '卢旺达', '布隆迪',
'塞舌尔','苏丹', '南苏丹', '乍得', '中非', '喀麦隆', '赤道几内亚', '加蓬', '刚果(布)', '刚果(金)', '圣多美和普林西比', '毛利塔尼亚', '塞内加尔', '冈比亚',
'马里','布基纳法索', '几内亚', '几内亚比绍', '佛得角', '塞拉利昂', '利比里亚', '科特迪瓦', '加纳', '多哥', '贝宁', '尼日尔', '尼日利亚', '赞比亚', '安哥拉',
'津巴布韦','马拉维', '莫桑比克', '博茨瓦纳', '纳米比亚', '南非', '斯威士兰', '莱索托', '马达加斯加', '科摩罗', '毛里求斯', '马约特', '留尼汪','加拿大', '美国', '墨西哥', '危地马拉', '伯利兹', '萨尔瓦多', '洪都拉斯', '尼加拉瓜', '哥斯达黎加', '巴拿马', '巴哈马', '古巴', '牙买加', '海地',
'圣皮埃尔和密克隆','多米尼加', '安提瓜和巴布达', '圣基茨和尼维斯', '多米尼克', '圣卢西亚', '圣文森特和格林纳丁斯', '格林纳达', '巴巴多斯', '特立尼达和多巴哥',
'圣皮埃尔', '百慕大','英属维尔京群岛', '安圭拉', '特克斯和凯科斯群岛', '蒙特塞拉特', '格陵兰', '瓜德罗普', '开曼群岛', '阿鲁巴', '库拉索', '圣巴泰勒米岛',
'马提尼克', '波多黎各','美属维尔京群岛','哥伦比亚', '委内瑞拉', '圭亚那', '苏里南', '厄瓜多尔', '秘鲁', '玻利维亚', '巴西', '智利', '阿根廷', '乌拉圭', '巴拉圭', '法属圭亚那','澳大利亚', '新西兰', '帕劳', '密克罗尼西亚联邦', '马绍尔群岛', '基里巴斯', '瑙鲁', '巴布亚新几内亚', '所罗门群岛', '瓦努阿图', '斐济', '图瓦卢', '萨摩亚',
'汤加', '关岛','库克群岛', '纽埃', '新喀里多尼亚', '法属波利尼西亚']
time0=[202001,202002,202003,202004,202005,202006,202007,202008,202009,202010,202011,202012,202101,202102,202103,202104,202105,202106,202107,202108,202109,202110,202111,202112]
t=0
for i in range(1,24):
for j in range(len(cou)):
cd = cou[j]+'+'+str(time0[i-1])
cd0=cou[j]+'+'+str(time0[i])
if cd in dict:
if cd0 in dict:
dict[cd0]=dict[cd0]+dict[cd]
else:
dict[cd0]=dict[cd]
print(dict['中国+202002'])
print(dict['中国+202003'])
print(dict['中国+202004'])
print(dict['中国+202005'])
f_country= []
f_time = []
f_count = []
for key in dict:
f_country.append(key.split('+')[0])
f_time.append(key.split('+')[1])
f_count.append(dict[key])
print('结果')
print(len(dict))
print(len(f_country))
print(len(f_time))
print(len(f_count))
print(max(f_count))
list1=[]
for month in time0:
jishu=0
for i in range(len(f_time)):
if int(f_time[i])==month:
jishu+=f_count[i]
list1.append(jishu)
print(list1)
with open('map.csv','w',newline='',encoding='utf-8') as f:
# 2. 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
# 3. 构建列表头
csv_writer.writerow(["country","count","date"])
# 4. 写入csv文件内容
for i in range(len(f_country)):
csv_writer.writerow([f_country[i],f_count[i],f_time[i]])
# 5. 关闭文件
f.close()至此数据处理工作全部完成,接下来就是使用pyechart进行可视化
import pandas as pd
import pyecharts.options as opts
from pyecharts.globals import ThemeType
from pyecharts.commons.utils import JsCode
from pyecharts.charts import Timeline, Grid, Bar, Map, Pie, Line
from pyecharts.faker import Faker
from pyecharts import options
name_map = {'Liechtenstein': '列支敦士登', 'Morocco': '摩洛哥', 'W. Sahara': '西撒哈拉', 'Serbia': '塞尔维亚', 'Afghanistan': '阿富汗',
'Angola': '安哥拉', 'Albania': '阿尔巴尼亚', 'Aland': '奥兰群岛', 'Andorra': '安道尔',
'United Arab Emirates': '阿联酋', 'Argentina': '阿根廷', 'Armenia': '亚美尼亚', 'American Samoa': '美属萨摩亚',
'Fr. S. Antarctic Lands': '法属南半球和南极领地', 'Antigua and Barb.': '安提瓜和巴布达', 'Australia': '澳大利亚',
'Austria': '奥地利', 'Azerbaijan': '阿塞拜疆', 'Burundi': '布隆迪', 'Belgium': '比利时', 'Benin': '贝宁',
'Burkina Faso': '布基纳法索', 'Bangladesh': '孟加拉国', 'Bulgaria': '保加利亚', 'Bahrain': '巴林', 'Bahamas': '巴哈马',
'Bosnia and Herz.': '波黑', 'Belarus': '白俄罗斯', 'Belize': '伯利兹', 'Bermuda': '百慕大', 'Bolivia': '玻利维亚',
'Brazil': '巴西', 'Barbados': '巴巴多斯', 'Brunei': '文莱', 'Bhutan': '不丹', 'Botswana': '博茨瓦纳',
'Central African Rep.': '中非', 'Canada': '加拿大', 'Switzerland': '瑞士', 'Chile': '智利', 'China': '中国',
"Côte d'Ivoire": '科特迪瓦', 'Cameroon': '喀麦隆', 'Dem. Rep. Congo': '刚果(布)', 'Congo': '刚果(金)',
'Colombia': '哥伦比亚', 'Comoros': '科摩罗', 'Cape Verde': '佛得角', 'Costa Rica': '哥斯达黎加', 'Cuba': '古巴',
'Curaçao': '库拉索', 'Cayman Is.': '开曼群岛', 'N. Cyprus': '北塞浦路斯', 'Cyprus': '塞浦路斯', 'Czech Rep.': '捷克',
'Germany': '德国', 'Djibouti': '吉布提', 'Denmark': '丹麦', 'Dominican Rep.': '多米尼加',
'Algeria': '阿尔及利亚', 'Ecuador': '厄瓜多尔', 'Egypt': '埃及', 'Eritrea': '厄立特里亚', 'Spain': '西班牙',
'Estonia': '爱沙尼亚', 'Ethiopia': '埃塞俄比亚', 'Finland': '芬兰', 'Fiji': '斐济', 'Falkland Is.': '福克兰群岛(马尔维纳斯)',
'France': '法国', 'Faeroe Is.': '法罗群岛', 'Micronesia': '密克罗尼西亚', 'Gabon': '加蓬', 'United Kingdom': '英国',
'Georgia': '格鲁吉亚', 'Ghana': '加纳', 'Guinea': '几内亚', 'Gambia': '冈比亚', 'Guinea-Bissau': '几内亚比绍',
'Eq. Guinea': '赤道几内亚', 'Greece': '希腊', 'Grenada': '格林纳达', 'Greenland': '格陵兰', 'Guatemala': '危地马拉',
'Guam': '关岛', 'Heard I. and McDonald Is.': '赫德岛和麦克唐纳群岛', 'Honduras': '洪都拉斯',
'Croatia': '克罗地亚', 'Haiti': '海地', 'Hungary': '匈牙利', 'Indonesia': '印度尼西亚', 'Isle of Man': '英国属地曼岛',
'India': '印度', 'Br. Indian Ocean Ter.': '英属印度洋领土', 'Ireland': '爱尔兰', 'Iran': '伊朗', 'Iraq': '伊拉克',
'Iceland': '冰岛', 'Israel': '以色列', 'Italy': '意大利', 'Jamaica': '牙买加', 'Jersey': '泽西岛', 'Jordan': '约旦',
'Japan': '日本', 'Siachen Glacier': '锡亚琴冰川', 'Kazakhstan': '哈萨克斯坦', 'Kenya': '肯尼亚',
'Kyrgyzstan': '吉尔吉斯斯坦', 'Cambodia': '柬埔寨', 'Kiribati': '基里巴斯', 'Korea': '韩国', 'Kuwait': '科威特',
'Lao PDR': '老挝', 'Lebanon': '黎巴嫩', 'Liberia': '利比里亚', 'Libya': '利比亚', 'Saint Lucia': '圣卢西亚',
'Sri Lanka': '斯里兰卡', 'Lesotho': '莱索托', 'Lithuania': '立陶宛', 'Luxembourg': '卢森堡', 'Latvia': '拉脱维亚',
'Moldova': '摩尔多瓦', 'Madagascar': '马达加斯加', 'Mexico': '墨西哥', 'Macedonia': '北马其顿', 'Mali': '马里',
'Malta': '马耳他', 'Myanmar': '缅甸', 'Montenegro': '黑山', 'Mongolia': '蒙古', 'N. Mariana Is.': '北马里亚纳',
'Mozambique': '莫桑比克', 'Mauritania': '毛利塔尼亚', 'Montserrat': '蒙特塞拉特', 'Mauritius': '毛里求斯',
'Malawi': '马拉维', 'Malaysia': '马来西亚', 'Namibia': '纳米比亚', 'New Caledonia': '新喀里多尼亚', 'Niger': '尼日尔',
'Nigeria': '尼日利亚', 'Nicaragua': '尼加拉瓜', 'Niue': '纽埃', 'Netherlands': '荷兰', 'Norway': '挪威',
'Nepal': '尼泊尔', 'New Zealand': '新西兰', 'Oman': '阿曼', 'Pakistan': '巴基斯坦', 'Panama': '巴拿马', 'Peru': '秘鲁',
'Philippines': '菲律宾', 'Palau': '帕劳', 'Papua New Guinea': '巴布亚新几内亚', 'Poland': '波兰',
'Puerto Rico': '波多黎各', 'Dem. Rep. Korea': '朝鲜', 'Portugal': '葡萄牙', 'Paraguay': '巴拉圭',
'Palestine': '巴勒斯坦', 'Fr. Polynesia': '法属波利尼西亚', 'Qatar': '卡塔尔', 'Romania': '罗马尼亚', 'Russia': '俄罗斯',
'Rwanda': '卢旺达', 'Saudi Arabia': '沙特阿拉伯', 'Sudan': '苏丹', 'S. Sudan': '南苏丹', 'Senegal': '塞内加尔',
'Singapore': '新加坡', 'S. Geo. and S. Sandw. Is.': '南乔治亚岛和南桑威奇群岛', 'Saint Helena': '圣赫勒拿',
'Solomon Is.': '所罗门群岛', 'Sierra Leone': '塞拉利昂', 'El Salvador': '萨尔瓦多',
'St. Pierre and Miquelon': '圣皮埃尔和密克隆', 'São Tomé and Principe': '圣多美和普林西比', 'Suriname': '苏里南',
'Slovakia': '斯洛伐克', 'Slovenia': '斯洛文尼亚', 'Sweden': '瑞典', 'Swaziland': '斯威士兰', 'Seychelles': '塞舌尔',
'Syria': '叙利亚', 'Turks and Caicos Is.': '特克斯和凯科斯群岛', 'Chad': '乍得', 'Togo': '多哥', 'Thailand': '泰国',
'Tajikistan': '塔吉克斯坦', 'Turkmenistan': '土库曼斯坦', 'Timor-Leste': '东帝汶', 'Tonga': '汤加',
'Trinidad and Tobago': '特立尼达和多巴哥', 'Tunisia': '突尼斯', 'Turkey': '土耳其', 'Tanzania': '坦桑尼亚',
'Uganda': '乌干达', 'Ukraine': '乌克兰', 'Uruguay': '乌拉圭', 'United States': '美国', 'Uzbekistan': '乌兹别克斯坦',
'St. Vin. and Gren.': '圣文森特和格林纳丁斯', 'Venezuela': '委内瑞拉', 'U.S. Virgin Is.': '美属维尔京群岛', 'Vietnam': '越南',
'Vanuatu': '瓦努阿图', 'Samoa': '萨摩亚', 'Yemen': '也门', 'South Africa': '南非', 'Zambia': '赞比亚',
'Zimbabwe': '津巴布韦', 'Somalia': '索马里', "Anguilla": "安圭拉", 'Dominica': '多米尼克','Gibraltar': '直布罗陀',
'Guyana': '圭亚那','Saint Kitts and Nevis': '圣基茨和尼维斯','Monaco': '摩纳哥','Maldives': '马尔代夫','San Marino': '圣马力诺',
'Vatican City': '梵蒂冈','British Virgin Islands': '英属维尔京群岛'}
def get_data():
df = pd.read_csv('map.csv') # 读取数据
# 每个国家对应的洲dict
continent = {
'亚洲': ['中国', '蒙古', '朝鲜', '韩国', '日本', '菲律宾', '越南', '老挝', '柬埔寨', '缅甸', '泰国', '马来西亚', '文莱', '新加坡', '印度尼西亚', '东帝汶',
'尼泊尔','不丹', '孟加拉国', '印度', '巴基斯坦', '斯里兰卡', '马尔代夫', '哈萨克斯坦', '吉尔吉斯斯坦', '塔吉克斯坦', '乌兹别克斯坦', '土库曼斯坦', '阿富汗',
'伊拉克','伊朗', '北马里亚纳','叙利亚', '约旦', '黎巴嫩', '以色列', '巴勒斯坦', '沙特阿拉伯', '巴林', '卡塔尔', '科威特', '阿联酋', '阿曼', '也门', '格鲁吉亚',
'亚美尼亚','阿塞拜疆','土耳其'],
'欧洲': ['英国', '法国', '荷兰', '爱尔兰', '比利时', '卢森堡', '摩纳哥', '丹麦', '挪威', '瑞典', '芬兰', '冰岛', '罗马尼亚', '保加利亚', '塞尔维亚', '黑山',
'北马其顿', '阿尔巴尼亚', '希腊', '斯洛文尼亚', '克罗地亚', '波黑', '意大利', '梵蒂冈', '圣马力诺', '马耳他', '西班牙', '葡萄牙', '安道尔',
'塞浦路斯', '波兰', '捷克', '斯洛伐克', '奥地利', '匈牙利', '德国', '瑞士', '列支敦士登', '爱沙尼亚', '拉脱维亚', '立陶宛', '白俄罗斯', '俄罗斯',
'乌克兰', '泽西岛','摩尔多瓦', '海峡群岛', '福克兰群岛(马尔维纳斯)', '英国属地曼岛', '圣马丁', '法罗群岛', '直布罗陀'],
'非洲': ['埃及', '利比亚', '突尼斯', '阿尔及利亚', '摩洛哥', '埃塞俄比亚', '厄立特里亚', '索马里', '吉布提', '肯尼亚', '坦桑尼亚', '乌干达', '卢旺达', '布隆迪',
'塞舌尔','苏丹', '南苏丹', '乍得', '中非', '喀麦隆', '赤道几内亚', '加蓬', '刚果(布)', '刚果(金)', '圣多美和普林西比', '毛利塔尼亚', '塞内加尔', '冈比亚',
'马里','布基纳法索', '几内亚', '几内亚比绍', '佛得角', '塞拉利昂', '利比里亚', '科特迪瓦', '加纳', '多哥', '贝宁', '尼日尔', '尼日利亚', '赞比亚', '安哥拉',
'津巴布韦','马拉维', '莫桑比克', '博茨瓦纳', '纳米比亚', '南非', '斯威士兰', '莱索托', '马达加斯加', '科摩罗', '毛里求斯', '马约特', '留尼汪'],
'北美洲': ['加拿大', '美国', '墨西哥', '危地马拉', '伯利兹', '萨尔瓦多', '洪都拉斯', '尼加拉瓜', '哥斯达黎加', '巴拿马', '巴哈马', '古巴', '牙买加', '海地',
'圣皮埃尔和密克隆','多米尼加', '安提瓜和巴布达', '圣基茨和尼维斯', '多米尼克', '圣卢西亚', '圣文森特和格林纳丁斯', '格林纳达', '巴巴多斯', '特立尼达和多巴哥',
'圣皮埃尔', '百慕大','英属维尔京群岛', '安圭拉', '特克斯和凯科斯群岛', '蒙特塞拉特', '格陵兰', '瓜德罗普', '开曼群岛', '阿鲁巴', '库拉索', '圣巴泰勒米岛',
'马提尼克', '波多黎各','美属维尔京群岛'],
'南美洲': ['哥伦比亚', '委内瑞拉', '圭亚那', '苏里南', '厄瓜多尔', '秘鲁', '玻利维亚', '巴西', '智利', '阿根廷', '乌拉圭', '巴拉圭', '法属圭亚那'],
'大洋洲': ['澳大利亚', '新西兰', '帕劳', '密克罗尼西亚联邦', '马绍尔群岛', '基里巴斯', '瑙鲁', '巴布亚新几内亚', '所罗门群岛', '瓦努阿图', '斐济', '图瓦卢', '萨摩亚',
'汤加', '关岛','库克群岛', '纽埃', '新喀里多尼亚', '法属波利尼西亚']
}
def assortment(x): # 定义一个分类函数
for k,v in continent.items():
if x in v:
return k
df['contient'] = df['country'].apply(assortment) # df中添加一列各国对应的大洲名
time_list = [202001,202002,202003,202004,202005,202006,202007,202008,202009,202010,202011,202012,202101,202102,202103,202104,202105,202106,202107,202108,202109,202110,202111,202112]
data_list = [] # 所有数据列表
for i in time_list:
map_data = []
country_name = df.loc[df['date'] == i]['country'].tolist() # 国家列表
country_count_num = df.loc[df['date'] == i]['count'].tolist()
for x,y in zip(country_name,country_count_num):
map_data.append({"name":x,"value":[y,x]})
global_count_num = df.loc[df['date'] == i].sum()['count']
contient_count_num = df.loc[df['date'] == i].groupby('contient').sum()['count'].tolist()
contient_name = df.loc[df['date'] == i].groupby('contient').sum()['count'].index.tolist() # 大洲名
pie_data = [i for i in zip(contient_name, contient_count_num)] # 饼图数据
bar_data = [] # 柱状图数据
df_top25_count_country = pd.DataFrame(data=country_count_num,index=country_name,columns=['num'])
df_top25_count_country = df_top25_count_country.sort_values('num',ascending=False).head(25)
top25_count_country= df_top25_count_country.index.tolist()
top25_count_country_num = df_top25_count_country['num'].tolist()
for a,b in zip(top25_count_country,top25_count_country_num):
bar_data.append({"name":a,"value":b})
data_list.append({"time":i,"data": {"map_data":map_data,"bar_data": {"name":top25_count_country,"value":bar_data},"pie_data":pie_data,"line_data":global_count_num}})
# print(data_list)
# print(time_list)
time_line(data_list,time_list)
def get_day_chart(data,time_list,day):
# 折线图因为一些问题只能先把数据打印出来再输出为折线图
global_count_num = [10,100,100,223,423,888,999,1221,1233,1444,1555,1666,1777,1888,1999,2000,1212,1212,123,123,123,4213,4232,323]
minNum = 0
maxNum = 13943 # 国家确诊人数的最大值
map_data = [
[[x["name"], x["value"]] for x in d["data"]["map_data"]] for d in data if d["time"] == day][0]
map_chart = (
Map()
.add(
series_name="",
data_pair=map_data,
zoom=0.9,
center=[78, 5],
maptype='world',
name_map=name_map,
is_map_symbol_show=False,
# itemstyle_opts={
# "normal": {"areaColor": "#323c48", "borderColor": "#404a59"},
# "emphasis": {
# "label": {"show": Timeline},
# "areaColor": "rgba(255,255,255, 0.5)",
# },
# },
itemstyle_opts={
"normal": {"areaColor": "#323c48", "borderColor": "#404a59"},
"emphasis": {
"areaColor": "rgba(255,255,255, 0.5)",
},
},
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(
title="全球COVID-19论文发文动态地图{}".format(day),
subtitle="",
pos_left="center",
pos_top="2%",
title_textstyle_opts=opts.TextStyleOpts(
font_size=25, color="rgba(255,255,255, 0.9)"
),
),
tooltip_opts=opts.TooltipOpts(
is_show=True,
formatter=JsCode(
"""function(params) {
if ('value' in params.data) {
return params.data.value[1] + ': ' + params.data.value[0];
}
}"""
),
),
)
)
count_y = [260, 292, 517, 1319, 3467, 6740, 11655, 16545, 22915, 28525, 34777, 41347, 47925, 69894, 73804, 75007,
75280, 75292, 75295, 75295, 75296, 75296, 75296, 75368]
count_m = [260, 33, 225, 802, 2149, 3282, 4922, 4908, 6381, 5636, 6269, 6589, 6603, 21994, 3990, 1222, 278, 12, 3,
0, 1, 0, 0, 72]
data_mark = []
i = 0
for x in time_list:
if x == day:
data_mark.append(count_y[i])
else:
data_mark.append("")
i = i + 1
data_mark2 = []
j=0
for x in time_list:
if x == day:
data_mark2.append(count_m[j])
else:
data_mark2.append("")
j = j + 1
time0 = [202001, 202002, 202003, 202004, 202005, 202006, 202007, 202008, 202009, 202010, 202011, 202012, 202101,
202102, 202103, 202104, 202105, 202106, 202107, 202108, 202109, 202110, 202111, 202112]
date=[]
for i in time0:
date.append(str(i))
print(time_list)
line_chart = (
Line()
.add_xaxis(date)
.add_yaxis("全球累计",
count_y,symbol_size=7,
symbol="emptyCircle",linestyle_opts=opts.LineStyleOpts(color="lightsalmon", width=1),
label_opts=opts.LabelOpts(color='lightsalmon'),
# 标记的颜色,描边宽度
itemstyle_opts=opts.ItemStyleOpts(color='lightsalmon', border_width=0)
)
.add_yaxis("全球每月", count_m,
symbol='emptyRect',
symbol_size=7, # 系列颜色
linestyle_opts=opts.LineStyleOpts(color="mediumseagreen", width=1),
label_opts=opts.LabelOpts(color='mediumseagreen'),
# 标记的颜色,描边宽度
itemstyle_opts=opts.ItemStyleOpts(color='mediumseagreen', border_width=0)
)
.set_series_opts(markline_opts=options.MarkLineOpts(
# 设置平均值的标记线
data=[options.MarkPointItem(type_="average", name="平均值"),
]))
.add_yaxis(
"",
data_mark,linestyle_opts=opts.LineStyleOpts(color="lightsalmon", width=1),
label_opts=opts.LabelOpts(color='lightsalmon'),
# 标记的颜色,描边宽度
itemstyle_opts=opts.ItemStyleOpts(color='lightsalmon', border_width=0),
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max")])
)
.add_yaxis(
"",
data_mark2,linestyle_opts=opts.LineStyleOpts(color="mediumseagreen", width=1),
label_opts=opts.LabelOpts(color='mediumseagreen'),
# 标记的颜色,描边宽度
itemstyle_opts=opts.ItemStyleOpts(color='mediumseagreen', border_width=0),
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max")])
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False), )
.set_global_opts(
legend_opts=opts.LegendOpts(pos_left="66%", pos_top="6.5%"),
title_opts=opts.TitleOpts(
title="全球COVID-19总发文发展趋势", pos_left="66%", pos_top="4%"
),
yaxis_opts=opts.AxisOpts(
position='right',
# 标签
# 轴线
axisline_opts=opts.AxisLineOpts(linestyle_opts=opts.LineStyleOpts(width=2)),
# 轴刻度
),
)
)
bar_x_data = [d['data']["bar_data"]["name"] for d in data if d["time"] == day][0]
bar_y_data = [d['data']["bar_data"]["value"] for d in data if d["time"] == day][0]
bar = (
Bar()
.add_xaxis(xaxis_data=bar_x_data)
.add_yaxis(
series_name="",
y_axis=bar_y_data,
yaxis_index=1,
label_opts=opts.LabelOpts(
is_show=True, position="right", formatter="{b} : {c}"
),
)
.reversal_axis()
.set_global_opts(
xaxis_opts=opts.AxisOpts(max_=maxNum, axislabel_opts=opts.LabelOpts(is_show=False)),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(is_show=False)),
tooltip_opts=opts.TooltipOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(
is_piecewise=True,
is_calculable=True,
dimension=0,
pos_left="10",
pos_top="26%",
pieces=[
{'max': 9, 'min': 0, 'label': '1-9篇', 'color': 'ivory'},
{'max': 49, 'min': 10, 'label': '10-49篇', 'color': 'lemonchiffon'},
{'max': 199, 'min': 50, 'label': '50-199篇', 'color': 'bisque'},
{'max': 499, 'min': 200, 'label': '200-499篇', 'color': 'lightsalmon'},
{'max': 1999, 'min': 500, 'label': '500-1999篇', 'color': 'salmon'},
{'max': 4999, 'min': 2000, 'label': '2000-4999篇', 'color': 'lightcoral'},
{'max': 19999, 'min': 5000, 'label': '5000-19999篇', 'color': 'indianred'},
{'max': 5000099, 'min': 20000, 'label': '>=20000篇', 'color': 'tomato'},
]
),
graphic_opts=[
opts.GraphicGroup(
graphic_item=opts.GraphicItem(
rotation=JsCode("Math.PI / 4"),
bounding="raw",
right=120,
bottom=120,
z=120,
),
children=[
opts.GraphicRect(
graphic_item=opts.GraphicItem(left="center", top="center", z=100),
graphic_shape_opts=opts.GraphicShapeOpts(width=400, height=80),
graphic_basicstyle_opts=opts.GraphicBasicStyleOpts(
fill="rgba(0,0,0,0.2)"
),
),
opts.GraphicText(
graphic_item=opts.GraphicItem(left="center", top="center", z=100),
graphic_textstyle_opts=opts.GraphicTextStyleOpts(
text=f"{str(day)}",
font="bold 30px Microsoft YaHei",
graphic_basicstyle_opts=opts.GraphicBasicStyleOpts(fill="#fff"),
),
),
],
)
],
)
)
pie_data = [
d["data"]["pie_data"] for d in data if d["time"] == day
][0]
pie = (
Pie()
.add(
series_name="",
data_pair=pie_data,
radius=["15%", "35%"],
center=["80.5%", "74%"],
label_opts=opts.LabelOpts(formatter="{b}:{d}%", position="outside", font_size=16), # formatter="{b}\n确诊人数:{c}\n占比:{d}%"
itemstyle_opts=opts.ItemStyleOpts(
border_width=1, border_color="rgba(0,0,0,0.3)"
),
)
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=False),
legend_opts=opts.LegendOpts(is_show=False),
)
)
grid_chart = (
Grid()
.add(
bar,
grid_opts=opts.GridOpts(
pos_left="15", pos_right="40%", pos_top="50%", pos_bottom="5"
),
)
.add(
line_chart,
grid_opts=opts.GridOpts(
pos_left="65%", pos_right="5.5%", pos_top="20", pos_bottom="55%"
),
)
.add(pie, grid_opts=opts.GridOpts())
.add(map_chart, grid_opts=opts.GridOpts()
)
)
return grid_chart
def time_line(data,time_list):
timeline = Timeline(
init_opts=opts.InitOpts(width="1800px", height="900px",theme = ThemeType.PURPLE_PASSION)
)
for day in time_list:
g = get_day_chart(data,time_list,day)
timeline.add(g, time_point=str(day))
timeline.add_schema(
orient="vertical",
is_auto_play=False,
is_inverse=True,
play_interval=500,
pos_left="null",
pos_right="20",
pos_top="20",
pos_bottom="20",
width="60",
label_opts=opts.LabelOpts(is_show=False),#(is_show=True, color="#fff",interval=15),
)
timeline.render("V02.html")
if __name__ == "__main__":
get_data()一些参数设置等可以参考pyechart的官方文档,本文就不做赘述
附,最终生成的可视化结果无法生成gif动图,本文所展示的gif为将所有图片保存后用python的imageio生成动图,代码如下:
import os
import imageio
def create_gif(image_list, gif_name):
frames = []
for image_name in image_list:
if image_name.endswith('.png'):
print(image_name)
frames.append(imageio.imread(image_name))
# Save them as frames into a gif
imageio.mimsave(gif_name, frames, 'GIF', duration=0.5)
return
def main():
path = r'./tp1/'
image_list = [path + img for img in os.listdir(path)]
gif_name = 'created_gif5.gif'
create_gif(image_list, gif_name)
if __name__ == "__main__":
main()















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









