










Salient Image Matting
Abstract
- 本文提出了一种称为显著图像抠图的图像抠图框架,用于估计图像中最显著前景的每像素不透明度值
- 通过使用显著对象检测模型来产生图像中最显著对象的三分图来完成的,以便指导关于更高级对象语义的抠图模型
- 利用大量粗标注和启发式三图生成方案来训练三图预测网络,因此它可以为任意前景生成三图。此外,作者还为抠图任务引入了多尺度融合架构,以更好地捕捉更精细、更低级别的不透明度语义。
- 通过trimap网络提供的高级指导,与其他自动方法相比,该框架只需要一小部分昂贵的抠图数据,同时能够为各种输入生成alpha抠图
contributions
- 第一个将对象显著性检测任务与图像抠图相结合来创建端到端框架的人,该框架可以产生图像中任意前景对象的alpha mattes 抠图。
- 提出了一种新的显著trimaps网络,它可以为任意前景对象生成trimaps,然后可以将其传递到抠图模型中进行进一步细化。
- 针对图像抠图任务,提出了一种基于更好的多尺度特征表示和融合的新架构,该架构比常用的用于抠图的编解码架构具有更好的性能。
Related Work
Automatic Trimap Generation
- 有许多技术试图为抠图生成精确的三分图
Image Matting
- 传统的图像抠图方法包括基于采样和基于相似度的方法
- 深度学习在抠图方面取得了令人印象深刻的成果。这些方法采用图像分割编码器/解码器架构,从一个RGB图像输入和一个包含用户定义的trimaps的额外通道中预测alpha mattes
Automatic Matting Methods
- 只需要一个单一的RGB图像输入来生成alpha mattes
Multi-Scale Feature Representation
- 深度图像抠图架构传统上是基于编码器-解码器的。多尺度特征表示和融合的最新进展特别适用于密集的预测任务,如图像抠图。
Method
Overview
-
为了分别捕获高级和低级特征,我们在SIM框架中使用了两个子网络(Salient Trimap Network (STN) and a matting network)
- STN生成三通道输出,分别表示背景、未知区域和前景
- 抠图网络从STN中获取固有的三分图(intrinsic trimap )以及原始输入,并预测一个单通道alpha matte image。然后按照Chen等人的方法融合两个子网络的输出,以产生the final alpha matte
- 还引入了一个多尺度层,DensePN,它作用于来自编码器的特征金字塔

Adaptive Trimap Generation Scheme
- 为了训练STN,需要trimap ground truths,然而代价是昂贵的,作者通过收集粗略标注的分割遮罩(coarsely annotated segmentation masks ),然后构建一个方案来最好地从这些粗略遮罩中生成三分图。
- 作者观察到毛发区域周围粗略注释通常低于或高于估计的前景区域;对于毛茸茸的物体,如动物或毛绒玩具,均有类似的模式,但不太明显,因此,作者开发了一个简单但健壮的三分图生成方案,该方案考虑了对象的大小和对象特征,如头发和毛发,以从这种粗糙的遮罩生成三分图。
- 为此,将粗糙遮罩的边界像素分为三类:头发、毛发和实体,然后分别扩张每一类。
(1)对于人类的头发等,在图像上先应用最先进的人类解析网络得到头发和身体区域的mask。mask然后被转换为只有2类:头发和非头发
(2)在有动物或毛绒玩具的图像中,所有的边界像素都被标记为皮毛像素
(3)如果一个像素没有被检测为毛发或皮毛,那么它被标记为一个实体像素
Salient Trimap Network
- 用于alpha matting的图像往往含有很大的语义多样性,所以本文利用Salient Trimap Network (STN)来预测最显著前景区域的trimap,而不是依赖于外部输入。
- STN的输出是3通道分类输出,是绝对背景、未知区域和绝对前景区域的概率估计,STN可以基于任何显著性对象检测架构。抠图网络只需要专注于从高质量数据中学习低级细节。
- 本文选择使用基于U 2Net 的体系结构,因为它能够有效地捕捉准确的语义。U 2Net 的nested U-structure和residual U-blocks使得网络能够在不显著降低feature map分辨率的情况下获得多尺度特征,这有助于STN更好地对前景、背景和未知区域之间的语义进行分类。
Matting Network
- 高分辨率表示和多尺度特征融合对于抠图很重要,因为它们促进了精确的定位,并为不透明度预测提供了具有更好上下文的低层特征。本文创建了一个可重复的金字塔层,称为DensePN,它具有并行的多分辨率流,并丰富了其他多分辨率特性。

- 每个流都是一个DenseBlock,后面是融合层,融合层使所有流的都达到相同的分辨率,并执行1×1卷积。重复卷积和融合块允许在每个分辨率级别丰富的多尺度特征。最后,所有的流在最终的prediction head之前被合并以预测alpha matte;并且本文使用ResNet34 作为编码器。
- 融合抠图网络仅在由内在trimap建议的不确定区域中产生具有精细值的alpha matte ,抠图网络仅被训练来细化低级细节
- 融合
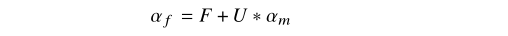
- 抠图网络仅在由intrinsic trimap建议的不确定区域中产生具有精确值的alpha matte,所以利用上述公式将STN和抠图模型的输出进行融合 ,F、B和U表示STN和预测的前景、背景和未知区域概率图,α m表示抠图网络输出。
Loss Functions
-
STN Loss
- 使用每个像素上的标准交叉熵损耗
-
Matting Loss
- 应用alpha预测损失和合成损失的组合,还应用拉普拉斯损失来进一步提高网络的性能:
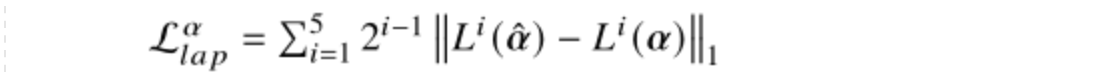
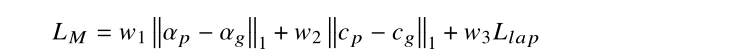
- 应用alpha预测损失和合成损失的组合,还应用拉普拉斯损失来进一步提高网络的性能:
-
Joint Loss
- 其中Fs是groundtruth foreground map,而1^是指示函数。这种软L1约束允许联合网络针对两个模型之间微妙的低层次和高层次特征融合进行优化,并且还防止STN忘记其语义丰富的特征
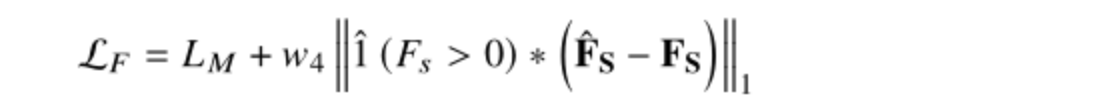
- 其中Fs是groundtruth foreground map,而1^是指示函数。这种软L1约束允许联合网络针对两个模型之间微妙的低层次和高层次特征融合进行优化,并且还防止STN忘记其语义丰富的特征
Results
与基于trimap方法的比较

与自动抠图方法的比较

Conclusion
本文提出了一种自动的、端到端的显著图像抠图模型。所提出的模型不需要任何额外的用户输入,并为包括人、动物等在内的各种对象产生高质量的alpha mattes ,实现了最先进的自动端到端抠图效果,并获得了与其他最先进的交互方法相当的效果,这些交互方法需要外部提供的trimaps以及输入图像。这可以归因于两个主要子网络——有效提取图像中显著对象的高级语义细节的STN和学习精细低级特征的多尺度融合抠图网络。















 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









