







 本文探讨了文本相似度计算的三种方法:基于向量空间模型(VSM)的统计学方法,利用词频和TF-IDF权重;语义理解方法,依赖层次词典如WordNet;以及深度学习的DSSM、CNN和RNN模型。着重讲解了VSM的权重计算和余弦相似度等度量,以及深度模型在捕捉上下文和序列信息的优势。
本文探讨了文本相似度计算的三种方法:基于向量空间模型(VSM)的统计学方法,利用词频和TF-IDF权重;语义理解方法,依赖层次词典如WordNet;以及深度学习的DSSM、CNN和RNN模型。着重讲解了VSM的权重计算和余弦相似度等度量,以及深度模型在捕捉上下文和序列信息的优势。
概述
总文本相似度的计算方法主要分为三大类:一类是基于统计学的计算方法,此种方法在计算时没有考虑文本的句子结构信息和语义信息,计算的结果有时会与人对自然语言的理解不相符合;另一类是基于语义理解的计算方法,这种方法依赖于具有层次结构关系的语义词典,计算结果相对准确,与人对自然语言的理解较为符合;第三种类是基于深度学习的计算方法。
1、基于向量空间模型的计算方法
向量空间模型简称 VSM,是 Vector Space Model 的缩写,是应用较为广泛的一种信息检索模型。在此模型中,文本被看作是由一系列相互独立的词语组成的,若文档 D 中包含词语 t1,t2,…,tN,则文档表示为D(t1,t2,…,tN)。由于文档中各个词语对文档的重要程度不同,并且各个词语的重要程度对文本相似度的计算有很大的影响,因而可对文档中的每个词语赋以一个权值 w,以表示该词的权重,其表示如下:D(t1,w1;t2,w2;…,tN,wN),可简记为 D(w1,w2,…,wN),此时的 wk 即为词语 tk 的权重,1≤k≤N。这样,就把文本表示成了向量的形式,同时两文本的相似度问题也就可以通过两向量之间的夹角大小来计算了,夹角越大,两文本的相似度就越低。
基于向量空间模型的计算方法假设文本中的词语是相互独立的,因而可以用向量的形式来表示,这种表示方法简化了文本中词语之间的复杂关系,也使得文本的相似程度变得可以计算了。向量表示方法中词语的权值应该能够显示出该词语对整个文本的重要程度,一般用经过统计得到的词频来表示;向量的所有分量组合在一起,应该能够将此文本与其他文本区分开。
大量统计结果表明,文本中出现次数最多的词语往往是反映句子语法结构的虚词以及文本作者想要阐述某个问题时所用的核心词,如果是围绕同一核心问题的文本,其核心词汇应该是类似的,所以这两类词对文本相似度的计算都是没有用的。因此,最高频词和低频词都不适宜做文本的特征词,只有词频介于最高频和低频之间的这部分词汇才适合做特征词。
在文本中出现频率较高的词语应该具有较高的权值,因此,在计算词语对文本的权重时,应考虑词语在文本中的出现频率,记为 tf。仅考虑这一项是不够的,如果某一词语不仅在一个文本中出现,而是在文本集中的很多个文本中都有出现,例如“的”字在中文文本中的出现频率应该是相当高的,但它对于我们区分各个文本是没有帮助的,也就是说,这样的词语是不具备鉴别能力的。因而,在计算词语权重时还应考虑词语的文档频率(df),即含有该词的文档数量。由于词语的权重与文档频率成反比,又引出与文档频率成反比关系的倒置文档频率(idf),其计算公式为idf=logN/n(其中 N 为文档集中全部文档的数量,n 为包含某词语的文档数)。由此得出特征词 t 在文档 D 中的权重 weight(t,D) = tf(t,D) * idf(t)。用 tf * idf 公式计算特征项的权重,既注重了词语在文本中的重要性,又注重了词的鉴别能力。因此,有较高的 tf*idf 值的词在文档中一定是重要的, 同时它一定在其它文档中出现很少。因此我们可以通过这种方法来选择把那些词语作为文本向量的特征词。
特征词选择出来之后,就能确定文本的向量表示了,有了文本向量,我们就可以通过此向量计算文本的相似度了。
(1)欧几里得距离
欧氏距离是最常用的距离计算公式,衡量的是多维空间中各个点之间的绝对距离,当数据很稠密并且连续时,这是一种很好的计算方式。
因为计算是基于各维度特征的绝对数值,所以欧氏度量需要保证各维度指标在相同的刻度级别,比如对身高(cm)和体重(kg)两个单位不同的指标使用欧式距离可能使结果失效。

(2)余弦相似度(Cosine Similarity)
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。

(3)曼哈顿距离(Manhattan Distance)
向量各坐标的绝对值做差后求和:d(i,j)=|X1-X2|+|Y1-Y2|。
(4)明可夫斯基距离(Minkowski distance)
明氏距离是欧氏距离的推广,是对多个距离度量公式的概括性的表述:

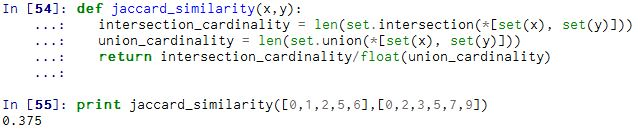
(5)Jaccard 相似系数(Jaccard Coefficient)
Jaccard 系数主要用于计算符号度量或布尔值度量的个体间的相似度,因为个体的特征属性都是由符号度量或者布尔值标识,因此无法衡量差异具体值的大小,只能获得“是否相同”这个结果,所以 Jaccard 系数只关心个体间共同具有的特征是否一致这个问题。
对于上面两个对象A和B,我们用Jaccard计算它的相似性,公式如下:
首先计算出A和B的交(A ∩ B),以及A和B的并 (A ∪ B):
然后利用公式进行计算:
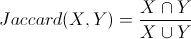

(6)斯皮尔曼(等级)相关系数(SRC :Spearman Rank Correlation)
(7)BM25算法
BM25算法,通常用来作搜索相关性平分:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:

2、基于语义理解的计算方法
基于语义理解的文本相似度计算方法与基于统计学的计算方法不同,此方法不需要大规模的语料库,也不需要长时间和大量的训练,一般需要一个具有层次结构关系的语义词典,依据概念之间的上下位关系或同义关系进行计算。文本的相似性计算大多是依赖于组成此文本的词语,基于语义理解的相似度计算方法也不例外,一般都是通过计算语义结构树中两词语之间的距离来计算词语的相似度。因此,一般会用到一些具有层次结构关系的语义词典,如WordNet、HowNet、同义词词林等。基于语义词典的文本相似度计算方法很多,有的通过计算词语在 WordNet 中由上下位关系所构成的最短路径来计算词语的相似度;也有的根据两词语在词典中的公共祖先结点所具有的最大信息量来计算词语的相关度;国内也有通过知网或同义词词林来计算词语的语义相似度的方法。
3、基于深度学习的计算方法
(1) 基于 DNN 的模型——DSSM模型
DSSM模型全称是deep struct semantic model,是微软在2013年提出来的深度匹配模型,后续一举成为表示学习的框架鼻祖。同年百度NLP团队也提出了神经网络语义匹配模型simnet,本质上两者在模型框架上是一致的,如图3.3所示,都是典型的双塔模型,通过搜索引擎里query和doc的海量用户曝光点击日志,用DNN把query和doc通过表示层,表示为低维的embedding向量,然后通过匹配层来计算query和doc的embedding向量距离,最终得到匹配分数。
整个DSSM可以分为3层,输入层、表示层和输出层
(1) 输入层输入层做的事情是把原始的句子(query或者doc)映射到一个向量空间并进入表示层。这里由于中文和英文本身的构造不同,在处理方式上也有所不同。
(2)表示层
在DSSM中表示层采用的是词袋模型(bag of words),也就是说不区分word的输入顺序,整个句子的所有单词都是无序输入的。 在embedding层之后,对每个sentence使用的是MLP网络,经典的隐层参数是300->300>128,也就是说最后,每个句子都将表示成一个128维度的向量。
(3) 匹配层
在原始的DSSM模型使用的是cosine作为两个向量的匹配分数
(2)基于 CNN 的模型
以DSSM为代表的基于DNN的表示学习匹配模型如3.2分析,无论是bow的表示还是DNN全连接网络结构的特点,都无法捕捉到原始词序和上下文的信息。因此,这里可以联想到图像里具有很强的local relation的CNN网络结构,典型代表有ARC-I模型,CNN-DSSM模型,以及CNTK模型。
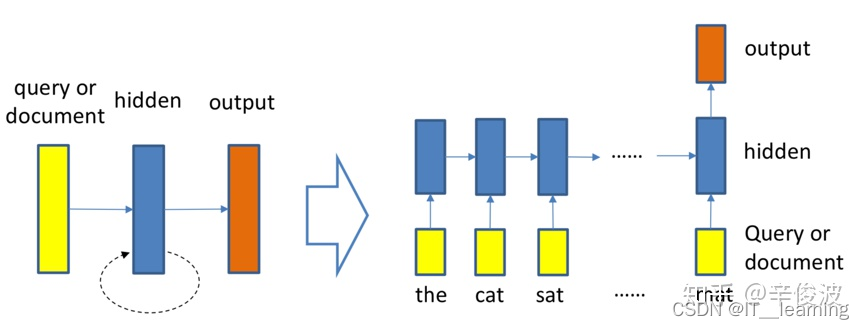
(3)基于 RNN 的模型
作为空间关系代表的CNN网络结构能够捕捉到query和doc的局部关系,RNN作为时间序列相关的网络结构,则能够捕捉到query和doc中前后词的依赖关系。因此,基于RNN的表示学习框架如图所示,query或者doc用黄色部分表示,通过RNN网络结构作为隐层来建模序列关系,最后一个word作为输出,从而学习得到query和doc的表示。对于RNN结构,可以使用业内经典的LSTM或者GRU网络结构,如图3.14所示。

















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









