









前四篇博文介绍的O(n^2)或O(n*logn)排序算法及堆排序结束,意味着有关排序算法已讲解完毕,此篇博文将对这些排序算法进行比较总结,并且学习另一个经典的堆结构,处于二叉堆优化之上的索引堆,最后拓展了解由堆衍生的一些问题。
此篇涉及的知识点有:
- 排序算法总结
- 索引堆及其优化
- 堆结构衍生的问题
挖掘算法中的数据结构(一):选择、插入、冒泡、希尔排序 及 O(n^2)排序算法思考
挖掘算法中的数据结构(二):O(n*logn)排序算法之 归并排序(自顶向下、自底向上) 及 算法优化
挖掘算法中的数据结构(三):O(n*logn)排序算法之 快速排序(随机化、二路、三路排序) 及衍生算法
一. 排序算法总结
前三篇博文介绍的排序算法及以上讲解完的堆排序完成,意味着有关排序算法已讲解完毕,下面对这些排序算法进行简单总结:
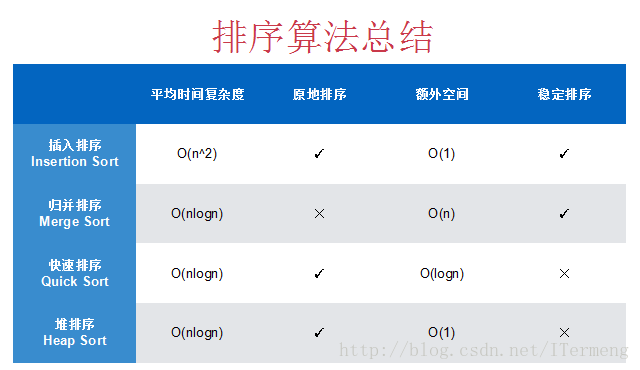
(1)均时间复杂度
注意,表格中强调的是“平均”时间复杂度,比如说快速排序,待排序数组已经是近乎有序,那么其时间复杂度会退化到O(n^2),所以使用了随机算法优化使其概率降低到0。总体而言,快速排序的性能较优,也就是说在O(n*logn)这3种算法而言有常数性的差异,但快速排序较优,所以一般系统级别的排序采用快速排序,而对于含有大量重复元素的数组可采用优化的三路快速排序。
(2)原地排序
插入排序、快速排序和堆排序可以直接在待排序数组上交换元素完成排序过程,而归并排序无法完成,它必须开辟额外的空间来辅助完成。正因如此,若一个系统对空间使用比较敏感,并不会采用归并排序。
(3)额外空间
- 对于插入排序和堆排序而言,使用的额外空间就是数组上交换元素,所以所耗空间为O(1)级别,即常数级别。
- 而归并排序需要O(n)级别空间,即数组同等长度空间来辅助完成归并过程。
- 快速排序所需O(logn)额外空间,因为它采用递归方式来进行排序,递归有logn层,所以需要O(logn)空间来保证每一层的临时变量以供递归返回时继续使用。
(4)稳定排序
稳定排序:对于相等的元素,在排序后,原来靠前的元素依然靠前,即相等元素的相对位置没有发生改变,此算法才是稳定的。

例如上图数组中有3个相同元素3,在排序后,这分开的3个3肯定会排列在一起,但重点依旧按照原来的“红绿蓝”位置排列,这才是稳定排序。
例如实际应用中,学生名单按照名字字典序排列,现在需要按照成绩重新排列,最后几个同分的同学之间依然还是按照字典序排列。
- 稳定排序
- 插入排序:算法中有后面元素与前面元素相比较,若小于则前移,否则不动。所以相同元素之间位置不会发生改变。
- 归并排序:在归并过程中,左右子数组已经有序,需要归并到一起,其核心也是判断当后面元素小于前面元素才前移,否则不动。所以相同元素之间位置不会发生改变。
- 不稳定排序
- 快速排序:算法核心中会随机选择一个标志点来进行大于、小于判断排序,所以很有可能使得后面相等元素到前面来。所以相同元素之间位置会发生改变。
- 堆排序:将整个数组整理成堆的过程中会破坏掉稳定性。所以相同元素之间位置会发生改变。
二. 索引堆(Index Heap)及优化
下面依然将重点放到“堆”这个数据结构,以下将介绍一个相比普通的堆更加高级的数据结构——索引堆。
1. 引出问题
首先来分析一下普通的堆有什么问题,才会进而衍生出索引堆:
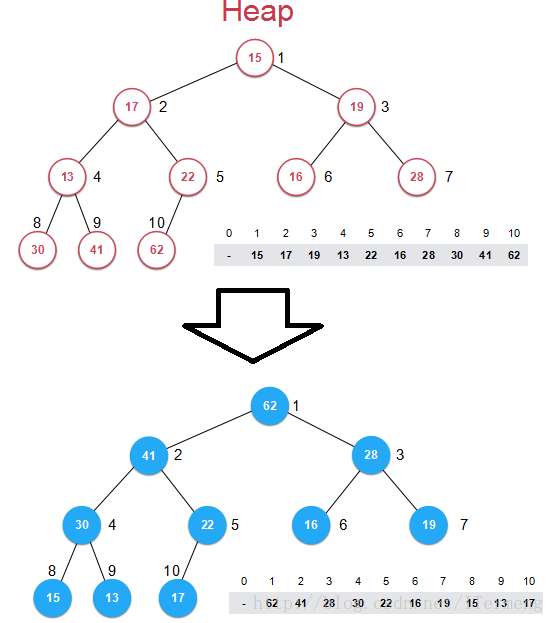
重点查看以上举例证明一个数组实现堆后元素的变换,可是在构建堆的过程中有局限性:
- 如果元素是非常复杂的结构,例如字符串(一篇十万字的文章)等等,这样交换的代价是十分大的。不过这可以通过一些基本手段解决,
- 更加致命的是元素在数组中的位置发生改变,使得在堆中很难索引到它!例如元素下标是任务ID,元素值是优先级别。当将数组构建成堆后,下标发生改变,则意味着两者无法产生联系!在原来数组中寻找任务只需O(1),但是构建成堆后元素位置发生改变后需要遍历数组!所以才会引入“索引堆”这个概念。
2. 结构思想
当将此数组构建成堆之前:对于索引堆来说将数据和索引两部分内容分开存储,而真正表示堆的数组是由索引构建成的,如下图,每一个节点旁标记的是索引1,2,3……
当将此数组构建成堆之后:****data部分并未发生改变,真正改变的是索引index,index数组发生改变形成堆。index为10,即真正元素值去找索引10代表的data值62,这样去对应。
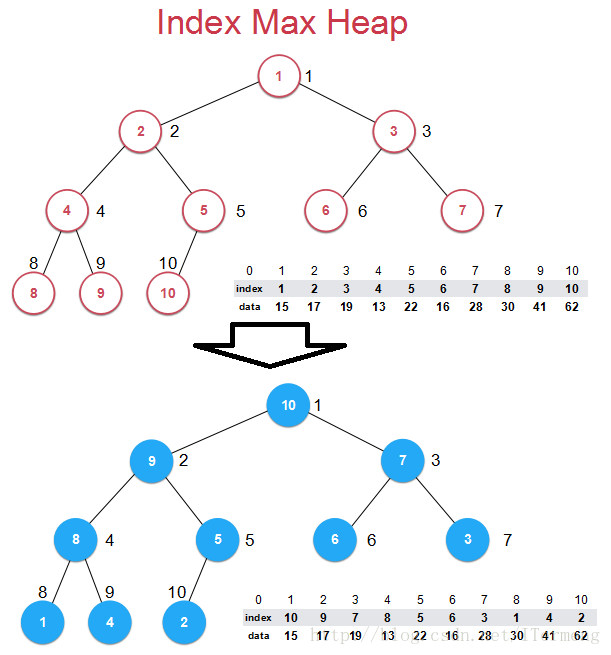
使用“索引堆”有以下两个好处:
- 将数组构建成堆之后,只是索引index值发生改变,int型数字之间的交换而不会涉及到data数据类型,提供交换效率。
- 重要的一点,如果想对堆中数据进行操作,例如对index为7的数据进行修改,找到对应数据值为28更改,在修改之后需要继续维护“堆”的性质,这时只需对data数组进行维护即可。
其实“索引堆”和之前堆的思路类似,只是在做元素值比较时是比较data数组,而做元素交换时修改的是索引值。
3. 代码实现
(1)基本更改
在原先MaxHeap基础上修改即可,首先改名为IndexMaxHeap(完整代码请查看github上源码,这里只提供重点部分):
- 在成员变量中需要添加一个数组来存储索引值
- 在构造函数中需要开辟索引数组空间
- 在析构桉树中也要相信释放掉该空间
(2)插入和删除函数
重点需要修改插入和删除函数:
- 插入函数:在调用插入函数时不仅要传数据还要传递索引值。注意:这里获取data数组的索引值是根据index数组来确定的!在
shiftUp函数中交换的是index索引值,并非是data数组。
// 索引堆中, 数据之间的比较根据data的大小进行比较, 但实际操作的是索引
void shiftUp( int k ){
while( k > 1 && data[indexes[k/2]] < data[indexes[k]] ){
swap( indexes[k/2] , indexes[k] );
k /= 2;
}
}
// 向最大索引堆中插入一个新的元素, 新元素的索引为i, 元素为item
// 传入的i对用户而言,是从0索引的
void insert(int i, Item item){
assert( count + 1 <= capacity );
assert( i + 1 >= 1 && i + 1 <= capacity );
i += 1;
data[i] = item;
indexes[count+1] = i;
count++;
shiftUp(count);
}- 删除函数:
// 索引堆中, 数据之间的比较根据data的大小进行比较, 但实际操作的是索引
void shiftDown( int k ){
while( 2*k <= count ){
int j = 2*k;
if( j + 1 <= count && data[indexes[j+1]] > data[indexes[j]] )
j += 1;
if( data[indexes[k]] >= data[indexes[j]] )
break;
swap( indexes[k] , indexes[j] );
k = j;
}
}
// 从最大索引堆中取出堆顶元素, 即索引堆中所存储的最大数据
Item extractMax(){
assert( count > 0 );
//注意:这里获取data数组的索引值是根据index数组来确定的
Item ret = data[indexes[1]];
swap( indexes[1] , indexes[count] );
count--;
shiftDown(1);
return ret;
}(3)更改函数
在第一点“引出问题”中提到一个问题,就是二叉堆中的某个节点的元素值可能会被改变,(实际应用中:OS中任务的优先级会动态改变)所以提供一个方法仅供修改元素值。
注意:修改元素值后必然还要维护索引堆的特性,所以该元素的值位置可能会有所改变,具体操作也简单,只需分别调用shiftUp、shiftDown方法即可找到合适位置。
// 将最大索引堆中索引为i的元素修改为newItem
void change( int i , Item newItem ){
i += 1;
data[i] = newItem;
// 找到indexes[j] = i, j表示data[i]在堆中的位置
// 之后shiftUp(j), 再shiftDown(j)
for( int j = 1 ; j <= count ; j ++ )
if( indexes[j] == i ){
shiftUp(j);
shiftDown(j);
return;
}
}4. 反向查找优化 —— 更改元素值
(1)引出问题
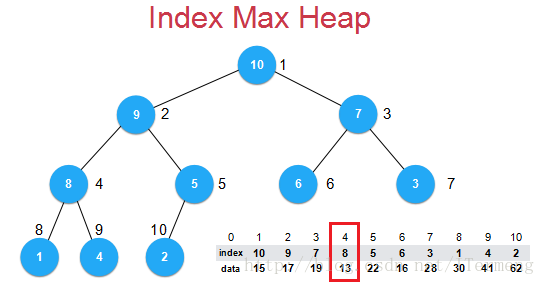
举个例子,如上图,若用户要更改下标4所指向元素的数据,将此数据更爱以后需要维护index数组,此数组本质上是一个堆,其中存储的元素对应着上一层索引。
所以需要做的是在index数组中找到4的位置,在下标9指向的位置,上一点的实现方法是顺序遍历查找下标9的位置,4指向的data是13,然后调用shiftUp、shiftDown方法维护二叉堆特征,这样过程的时间复杂度为O(n)级别。
(2)思想
其实对于以上更改元素值思想还有可以优化的地方,此种思想非常经典,被称为“反向查找”,查看下图:
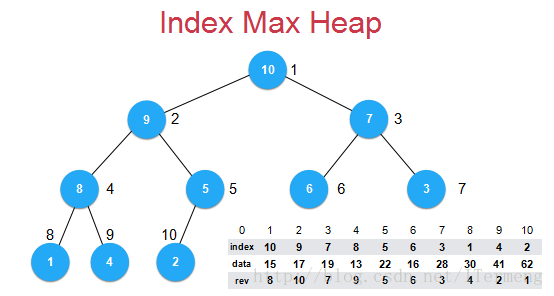
可以看到,多了一行数组rev,rev[i]代表i这个索引在堆中的位置。举个例子,将下标4的data13修改了,接着需要维护索引4在堆中的位置,即维护index数组,怎么找到下标4在堆中的位置?
查看rev数组,rev数组中对应的是9,所以在index数组中第9个位置存储的索引4。
rev数组相关性质
这样一来只需维护rev数组,在进行元素更新时所耗时间复杂度为O(1),来了解rev数组相关性质:

(3)代码实现
如此一来引入了rev数组,就需要在insert、shiftUp、extractMax、shiftDown函数中进行维护,代码如下:
(具体代码见github源码,以下只粘贴重点部分)
int *reverse; // 最大索引堆中的反向索引, reverse[i] = x 表示索引i在x的位置
// 索引堆中, 数据之间的比较根据data的大小进行比较, 但实际操作的是索引
void shiftUp( int k ){
while( k > 1 && data[indexes[k/2]] < data[indexes[k]] ){
swap( indexes[k/2] , indexes[k] );
reverse[indexes[k/2]] = k/2;
reverse[indexes[k]] = k;
k /= 2;
}
}
// 索引堆中, 数据之间的比较根据data的大小进行比较, 但实际操作的是索引
void shiftDown( int k ){
while( 2*k <= count ){
int j = 2*k;
if( j + 1 <= count && data[indexes[j+1]] > data[indexes[j]] )
j += 1;
if( data[indexes[k]] >= data[indexes[j]] )
break;
swap( indexes[k] , indexes[j] );
reverse[indexes[k]] = k;
reverse[indexes[j]] = j;
k = j;
}
}
// 向最大索引堆中插入一个新的元素, 新元素的索引为i, 元素为item
// 传入的i对用户而言,是从0索引的
void insert(int i, Item item){
assert( count + 1 <= capacity );
assert( i + 1 >= 1 && i + 1 <= capacity );
// 再插入一个新元素前,还需要保证索引i所在的位置是没有元素的。
assert( !contain(i) );
i += 1;
data[i] = item;
indexes[count+1] = i;
reverse[i] = count+1;
count++;
shiftUp(count);
}
// 从最大索引堆中取出堆顶元素, 即索引堆中所存储的最大数据
Item extractMax(){
assert( count > 0 );
Item ret = data[indexes[1]];
swap( indexes[1] , indexes[count] );
reverse[indexes[count]] = 0;
reverse[indexes[1]] = 1;
count--;
shiftDown(1);
return ret;
}
// 将最大索引堆中索引为i的元素修改为newItem
void change( int i , Item newItem ){
assert( contain(i) );
i += 1;
data[i] = newItem;
// 有了 reverse 之后,
// 我们可以非常简单的通过reverse直接定位索引i在indexes中的位置
shiftUp( reverse[i] );
shiftDown( reverse[i] );
}五. 堆衍生的问题
1. 使用堆实现优先队列
(1)OS系统执行任务
可以使用堆来作为优先队列,对于OS而言,每次使用堆可找到优先级最高的任务执行,就算此时有新的任务添加进行,插入堆中即可,动态修改任务的优先级也可满足。实现一个堆后,以上需求易简单。
(2)在N个元素中选出前M个元素
例如在1,000,000个元素中选出前100名,也就是“在N个元素中选出前M个元素”。
按照之前学习的一些排序算法,性能最优可达到O(n*logn )但是使用了优先队列,可将时间复杂度从O(n*logn )降低为O(n *logM)!(若N是百万级别数字,其实这优化的不少)使用一个最小堆,使长度维护在100,将前100个元素放入最小堆之后再插入新的元素,此时只会将堆中最小元素移出去,堆的长度不变,将这1,000,000个元素遍历完后,最小堆中存放的100个元素就是前100名,因为比其小的元素全都请了出去。
2. 多路归并排序
可以使用堆来完成多路归并排序,首先思考归并排序思想,是将数组一分为二,两个子数组分别排序后进行归并,每次归并的过程只有两个子数组元素比较,如下图:
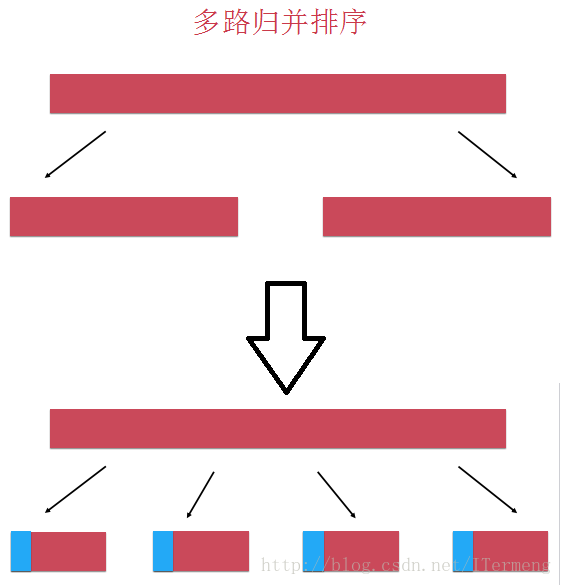
其实在归并排序过程中可以一次分成多个(大于2,这里是4)子数组,再进行归并,每次比较4个元素的大小关系,理所当然想到逐个元素比较,但是可以将这4个元素放入堆中,再逐个取出来,取出来的元素属于哪个子数组,再添加这个子数组的下一个元素进入堆中,来维护这个堆。
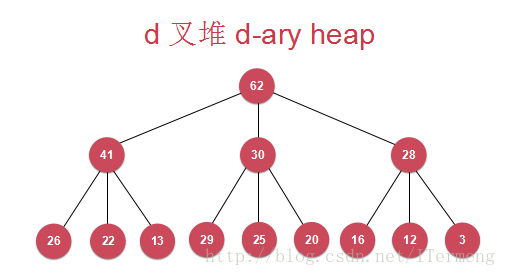
3. d叉堆
此部分主要讲解的是二叉堆,即每个节点最多有两个孩子,其实还有一种思想——d叉堆,下图是三叉堆,依然满足堆的特征。其中d越大,层数越少,同样在Shift Up、Shift Down时比较的次数增多,所以对于这个d的数量,也是性能之间的衡量。(二叉堆是最经典的)
4. 堆的实现细节优化
这里这位读者提供对细节优化的思路,切身去体会算法的“优化”,堆的实现细节优化还有:
- ShiftUp 和 ShiftDown 中使用赋值操作替换swap操作
- 表示堆的数组从0开始索引
- 没有capacity的限制,动态的调整堆中数组的大小
5. 其它
此篇博文主要讲解的是最大堆 和 最大索引堆,与之相对应的还有最小堆、 最小索引堆,可自行查看源码实现。这其实也对应着最大、最小优先队列,这样的优先队列可轻易找到队列中最大或最小元素,那么是否可以设计一个“最大最小类”,能同时找到最大和最小数据?
这里仅提供思路,其实可以在这个类中同时放一个最大堆和最小堆,两者维护同一组数据。
最后此篇文章重点讲解二叉堆和索引堆,但其实有关于堆还衍生出了二项堆和斐波那契堆,有兴趣可自行研究。
所有以上解决算法详细代码请查看liuyubo老师的github:
https://github.com/liuyubobobo/Play-with-Algorithms
以上就是有关于堆的所有内容,堆其实就是一棵“数”,包括之前学习的有关O(n*logn)排序算法,虽然是在数组上进行排序,但是通过其算法使用的递归可画出“树”结构,可见“树”的重要性,下一篇将开始讲解
若有错误,虚心指教~















 6535
6535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









