







回顾内核栈切换的五步
- 用户程序调用Int 0x80中断 进入内核 通过将5个东西(ss,sp,eflags,cs,ip)压入内核栈(这里是硬件实现),
然后手写push压入当前程序现场(其他有用的寄存器值)
建立起和内核栈的连接
思考
(1)这是一种什么连接?
我把用户栈的地址push在内核栈里,当我要返回用户栈时,我就pop出去,这样子用户地址,就和内核地址关联起来了
(2)存放在内核地址的哪里?即内核栈的栈顶和栈底存在哪里?
使用TSS切换时,存放在TSS里;具体见2.4节的图
内核栈切换模式,存放在PCB里;具体见2.5节的task_struck代码
这是设计时就规定的。 - 进入内核运行,且出现一些需要切换进程的情况,如sys_write,那么需要找到 切换过去执行的下一个进程
找哪一个最好——调度算法,此处不考虑
在代码中的体现是得到一个next,然后调用swich_to(next)完成切换 - 利用next完成内核栈的切换
- 根据切换后的内核栈 手写pop指令恢复之前用push压入的程序执行现场
- 用iret恢复之前被Int压入的寄存器内容

开始实验
0、说明
(1)linux0.11 不支持内核级线程,但是进程和内核级线程非常像,只是没有资源切换。(进程=内核级线程(指令序列)+内存资源)
所以,以下源码分析里都是用PCB,理解成TCB也没问题。
(2)汇编为AT&T格式
(3)要实现基于内核栈的任务切换,主要完成如下三件工作:
(1)重写 switch_to;
(2)将重写的 switch_to 和 schedule() 函数接在一起;
(3)修改现在的 fork()。
1、修改schedule() 函数
将目前的 schedule() 函数(在 kernal/sched.c 中)做稍许修改,即将下面的代码:
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
//.......
switch_to(next);
修改为
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i, pnext = *p;
//.......
switch_to(pnext, LDT(next));
在kernel/sche.c中添加声明
extern long switch_to(struct task_struct *p, unsigned long address);
在个sche.c文件的schedule()函数中添加pnext,如下图:
struct task_struct* pnext = &(init_task.task);

1.1 schedule()函数的作用(为什么要修改schedule()函数?)
schedule()函数的作用是实现进程调度(调度=选一个+切换),
在schedule()中调用switch_to()实现进程切换
1.2 为什么要为switch_to()增加pnext参数?
原linux0.11内核利用TSS完成切换,传给switch_to()函数的内容只有next(作为task[]的index,取出的内容是指向下一个线程的PCB的指针)。
我们的目标是将其修改为用内核栈的切换方式,根据老师上课的分析,在利用switch_to()实现切换时我们会用到当前进程的 PCB、目标进程的 PCB、当前进程的内核栈、目标进程的内核栈等信息。(switch_to后面会修改)
在linux0.11中,进程的内核栈和该进程的 PCB 在同一页内存上(一块 4KB 大小的内存),其中 PCB 位于这页内存的低地址,栈位于这页内存的高地址。见下图。
即,知道PCB,就等于知道PCB+内核栈。

当前进程的PCB是由一个全局变量current指向,
所以只需要目标进程的PCB就行,这里我们传入一个指针参数 pnext 指向下一个PCB。
LDT(next)怎么用的 还不知道,后续添加
2、实现switch_to()函数
2.1 switch_to()函数的作用
前面的schedule()主要是找到了next,并传递进来。
(1)因此,本函数最重要的是实现进程切换(=切换当前PCB指针,切换内核栈,切换用户栈,切换用户态的CS:IP);
(2)现在虽然不使用 TSS 进行任务切换了,但是 Intel 的这种中断处理机制还要保持,所以要完成TSS 中的内核栈指针的重写,
(3)每个进程有自己的LDT,所以还要完成LDT 的切换。不确定是否正确,后续修正
综上,进程切换等价于,依次完成 PCB 的切换、TSS 中的内核栈指针的重写、内核栈的切换、LDT 的切换以及 PC 指针(即 CS:EIP)的切换。
(4)另外,由于是 C 语言调用汇编,所以需要首先在汇编中处理栈帧,即处理 ebp 寄存器;
(5)为了保证程序的健壮性,还需完成额外的比较。下一个进程PCB等于 current,则什么也不用做;如果不等于 current,就开始进程切换,
最后总结一下,switch_to()的代码结构、执行顺序:
在kernel/system_call.s中添加switch_to()
2.2 开始切换前的准备
这是switch_to()最开始的代码
switch_to:
pushl %ebp
movl %esp,%ebp
pushl %ecx
pushl %ebx
pushl %eax
movl 8(%ebp),%ebx
cmpl %ebx,current
je 1f
!…………
ret
(1)为什么要在最初压栈这么多寄存器呢?
根据汇编知识我们知道,当一个C函数被编译为汇编代码时,会先压栈各种寄存器,
此处是C函数(schedule)调用一个汇编函数(switch_to),汇编函数不会再被展开了,所以需要手动用汇编指令保存现场(就是几个寄存器)。
(2)然后需要判断一下找到的next是否和当前的current是同一进程,
特别注意一下这行代码,作用效果是将ebx赋为switch_to()传递进来的参数pnext:
movl 8(%ebp),%ebx
这里涉及到了C语言函数的汇编调用过程,核心就是函数栈帧的变化,
一般来说,C函数的第一个参数就在ebp+8的位置,
ebp+0一般保存原ebp(如果用主函数和被调用函数来描述函数调用的过程,这里的原ebp就是主函数的ebp),
ebp+4一般保存调用函数指令的下一条指令的地址,就是被调函数返回后,开始执行的第一条指令的地址。
而为什么是+4呢?ebp寄存器是32位的寄存器,同时我们默认是按字节编址,所以需要4个字节来存放这32位的内容。
可以参考这篇文章
挖个坑,有时间的话就写一篇关于函数调用过程中栈的变化
(3)如果相等的话,就不用切换内核栈,就把刚刚压进来的参数pop出去。
cmpl %ebx,current
je 1f
!…………
!…………
1:popl %eax
popl %ebx
popl %ecx
popl %ebp
ret
2.3 完成PCB的切换
实质上就是切换全局变量current
完成 PCB 的切换可以采用下面两条指令,其中 ebx 是从参数中取出来的下一个进程的 PCB 指针,
(就是上一节分析的指令 movl 8(%ebp),%ebx )
movl %ebx,%eax
xchgl %eax,current
经过这两条指令以后,eax 指向现在的当前进程,ebx 指向下一个进程,全局变量 current 也指向下一个进程。
后续会用到这两个寄存器的值,可以特别注意一下。
2.4 TSS中的内核栈指针的重写
做了两件事:保留TTS,使修改其中指向内核栈的指针
虽然我们不用TSS进行切换了,但是 Intel 的这种中断处理机制还要保持,所以仍然需要有一个当前 TSS,这个 TSS 被全局变量init_task.task.tss定义,指向0号进程的tss,所有进程都共用这个 tss,任务切换时不再发生变化。
在使用TSS切换内核栈时,每个进程的内核栈的指针,被保存在栈顶偏移为4的位置,见下图(右)。
栈顶的位置在哪儿呢?
前文说过,每个进程的PCB和它的内核栈共同构成一页4KB的内存,内核栈的栈顶指针esp0指向高地址,所以esp0 = ebx(页基址,2.3节说了ebx 指向下一个进程PCB,就是下图中的p) + 4096(4KB),
因此存放的位置是,tss(0号进程的tss基址) + ESP0(偏移地址,宏定义为4) 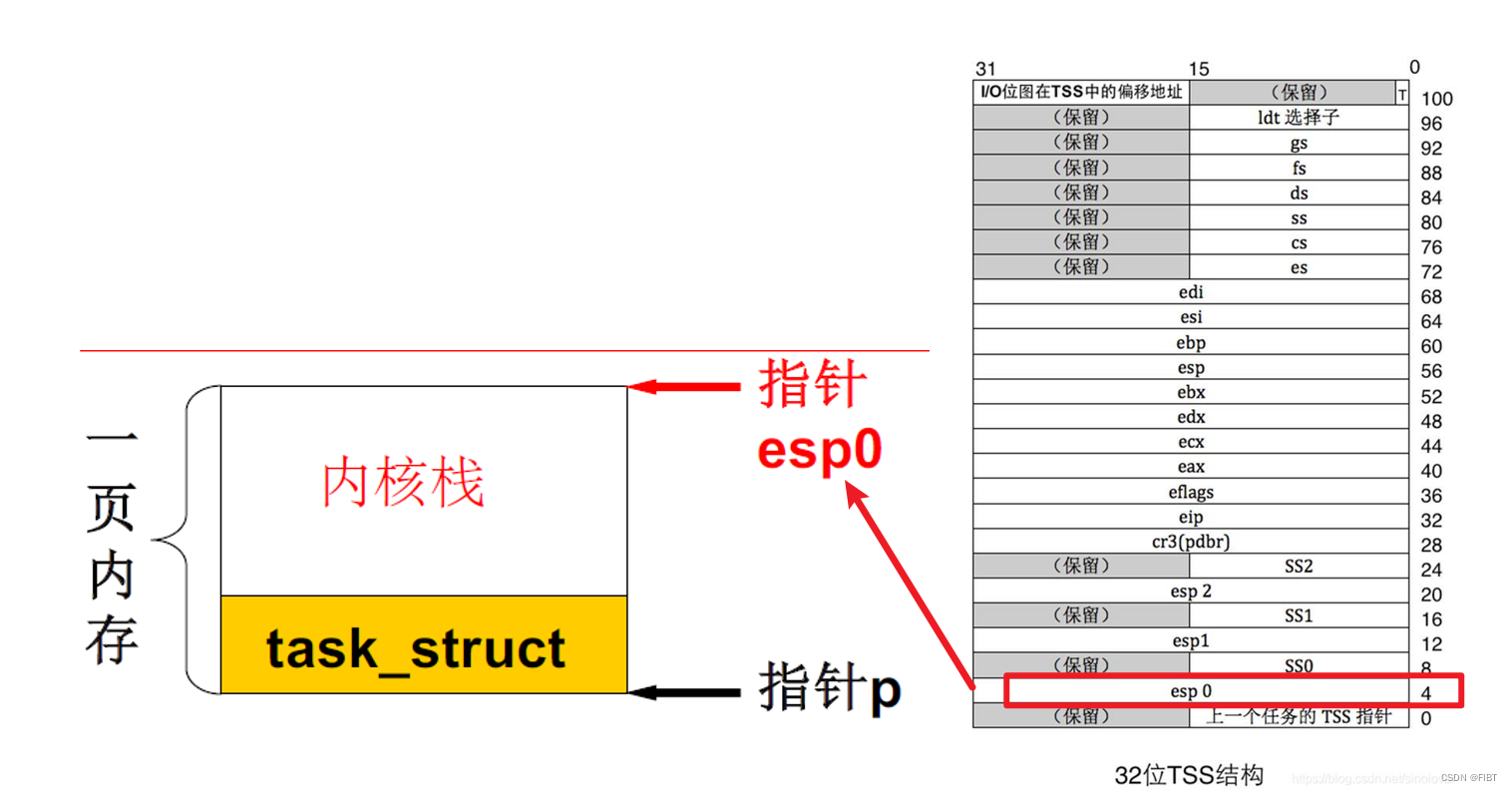
因此这部分代码为
//……
movl tss,%ecx
addl $4096,%ebx
movl %ebx,ESP0(%ecx)
ESP宏定义在kernel/system_call.s文件中添加
ESP0 = 4
tss宏定义在kernel/sched.c文件中添加
struct tss_struct *tss = &(init_task.task.tss);
2.5 完成内核栈的切换
核心就是,把原进程的内核栈的sp存到它PCB里,
从新的进程的PCB里拿出它的sp,赋值给cpu寄存器esp
但是,现在会出现什么问题呢?
2.4节说了,在TSS切换模式里,esp被规定为存在tss+4处;
那么,在内核栈切换模式里,esp被存在哪里呢? 很自然的想到,esp被存在PCB里。
2.5.1 在PCB中增加esp的定义
但是,实现内核栈切换模式是我们要完成的任务,原linux0.11的代码没有考虑这个问题,所以源代码中定义PCB的结构体task_struck里,没有存放esp的位置;
因此,我们要自己修改task_struck,加上esp。
注意不要放在task_struct 的第一个位置,原因:
在某些汇编文件中(主要是在 kernal/system_call.s 中)有些关于操作这个结构一些汇编硬编码,所以一旦增加了 kernelstack,这些硬编码需要跟着修改,由于第一个位置,即 long state 出现的汇编硬编码很多,所以 kernelstack 千万不要放置在 task_struct 中的第一个位置
task_struct 在 include/linux/sched.h 中定义
// ……
struct task_struct {
long state;
long counter;
long priority;
long kernelstack; //加上定义的esp
//......
2.5.2 给esp赋值
加上esp的定义后,就可以把ebx的值赋给它了,但请注意:
kernelstack放的位置要 与 KERNEL_STACK定义的常数对应,这里默认long占4个字节,所以KERNEL_STACK=4*3=12
KERNEL_STACK = 12
! 再取一下 ebx,因为前面修改过 ebx 的值
movl 8(%ebp),%ebx
! 2.3节提到,**eax** 指向现在的**当前进程**,**ebx** 指向**下一个进程**
movl %esp,KERNEL_STACK(%eax)
movl KERNEL_STACK(%ebx),%esp
2.5.3 修改PCB初始化过程
由于这里将 PCB 结构体的定义改变了,所以在产生 0 号进程的 PCB 初始化时也要跟着一起变化
在include/linux/sched.h中,将
/* linux/sched.h */
#define INIT_TASK { 0,15,15, 0,{{},},0,...
修改为
/* linux/sched.h */
#define INIT_TASK \
/* state etc */ { 0,15,15,PAGE_SIZE+(long)&init_task,\
/* signals */ 0,{{},},0, \
......
}
2.6 LDT 的切换
指令movl 12(%ebp),%ecx 负责取出对应 LDT(next)的那个参数,(参见2.2节开始切换前压入的参数)
指令lldt %cx负责修改 LDTR 寄存器,
一旦完成了修改,下一个进程在执行用户态程序时使用的映射表就是自己的 LDT 表了,地址空间实现了分离。
最后两句代码一定要写,且仅能写在此处,2.8节解释
! 切换LDT
mov 12(%ebp), %ecx
lldt %cx ! 覆盖
movl $0x17,%ecx
mov %cx,%fs
2.7 用户态 PC 的切换
通过switch_to的最后一句指令 ret 实现。
但是具体的返回过程很复杂:
(1)schedule() 函数的最后调用了这个 switch_to 函数,所以这句指令 ret 就返回到下一个进程(目标进程)的 schedule() 函数的末尾,遇到的是};
最初调用schedule() 的肯定是原进程,当返回的时候,执行现场就是目标进程了,它横跨了两个进程,是这样吗???
(2)'}'被编译为ret,继续 ret 回到调用的 schedule() 地方,是在中断处理中调用的,所以回到了中断处理中,就到了中断返回的地址;
(3)再调用 iret 将之前Int中断存入的5个重要寄存器的值pop到CPU当前的CS:IP,SS:SP中,就实现了跳转到目标进程的用户态程序去执行。
核心:抓住函数返回,就是回到之前调用它的代码 的下一行去执行
2.8 重置段寄存器fs的值
switch_to 代码中在切换完 LDT 后的两句很特殊、很重要,即:
! 切换 LDT 之后
movl $0x17,%ecx
mov %cx,%fs
(1)fs的作用——通过 fs 访问进程的用户态内存(在实验2添加系统调用时用过),LDT 切换完成就意味着切换了分配给进程的用户态内存地址空间,
所以前一个 fs 指向的是上一个进程的用户态内存,而现在需要执行下一个进程的用户态内存,所以就需要用这两条指令来重取 fs。
(2)不过,再深入一点我们会发现:fs 是一个选择子,
即 fs 是一个指向描述符表项的指针,这个描述符才是指向实际的用户态内存的指针,所以上一个进程和下一个进程的 fs 实际上都是 0x17,
所以,真正找到不同的用户态内存是因为两个进程查的 LDT 表不一样;
但是在2.6节,我们已经完成了 LDT 表的切换,它们查的LDT表就应该不一样了,为什么还要重置fs,且只能在这里重置呢?
(3)首先我们要明确以下两点:
i. LDT表是在内存中, 访问内存对CPU来说是比较慢的动作, 效率不高。
ii. 段描述符的格式很奇怪, 一个数据要分三个地方存, 所以CPU 要把这些七零八落的数拼合成一个完整数据也是要花时间的。
所以,为了提高获取段信息的效率,设计者对GDT(LDT)率先使用缓存技术, 将段信息用一个寄存器缓存,这就是段描述符缓冲寄存器。
(很好理解,就是增加一级cache提高访问速度,类比L1-cache、L2-cache、TLB)
对程序员而言这个寄存器是不可见、不可编程控制的。CPU每次将混乱存放的段选择符信息整理成直接可用的形式后, 会将其存入段描述符缓冲寄存器,以后每次访问相同的段时, 就直接读取该段寄存器对应的段描述符缓冲寄存器。
既然是缓存, 就一定要有个失效时间。很巧的是,这个缓存还真没有准确的失效时间,(不知道会不会被替换出去);
但是有一点可以肯定,只要往段寄存器中赋值, CPU 就会更新段描述符缓冲寄存器。例如,在保护模式下加载选择子(即使新选择子的值和之前段寄存器中老的选择子相同), CPU 就会重新访问全局描述符表, 再将获取的段信息重新放回段描述符缓冲寄存器。
因此,即使重置前后fs的值不变,我们也要重置一下,以更新缓存。
本节参考资料《操作系统真象还原》
3、修改fork()
为什么要修改fork()?
fork()是根据父进程创建一个子进程,然后调度执行。
而进程的创建可以理解为,初始化一些东西,实现PC切过去就能开始正常执行。
而切过去,又发生了什么呢?
PCB、内核栈都发生了变化。PCB的初始化,已经由系统定义好了,内核栈的位置由PCB指出,这再2.5节也解决了,所以现在,我们要完成的是初始化内核栈里的东西,内核栈和用户栈的关连。
那么内核栈里有什么呢?我们重走内核栈切换5步,看一下内核栈都发生了什么。
3.1
参考这篇博客第二部分fork()相关、内核栈视角下的五段论讲得很清楚
《哈工大操作系统实验四——基于内核栈切换的进程切换(极其详细)》
参考链接
实验指导书——蓝桥云课
强烈推荐~《哈工大操作系统实验四——基于内核栈切换的进程切换(极其详细)》
《操作系统原理、实现与实践 (李治军,刘宏伟)》















 1683
1683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









