








遥感代码星球的第004篇代码分享
2025/5/5 ·Monday·
今天分享
基于栅格数据的Pearson相关性分析
在遥感分析中,我们经常拥有多个年份的栅格数据(如年平均植被指数 NDVI 或净初级生产力 NPP)以及相应的气象变量(如年平均温度、降水等)。为了探究这两类变量之间的关联关系,Pearson 相关系数 是最常用的方法之一。
其数学定义如下:
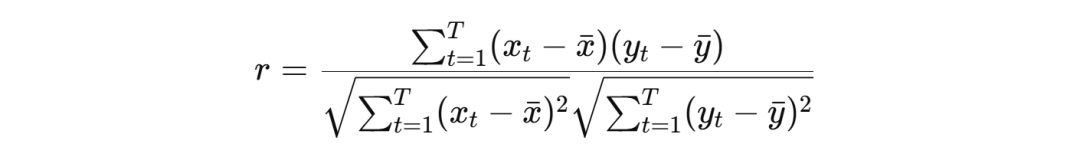
02 核心代码
本文使用数据:
黄河流域MOD17A2H NPP(500m)
黄河流域1km温度,降水数据
数据已经预处理,统一分辨率
时间跨度:
2000-2020年
文件夹结构:

代码可以实现:
✅可视化运行进度
✅自动处理 nodata 与极端值
✅忽略不合法像元(如恒定值)
✅输出 r, p, 显著掩膜, 显著性过滤后的 r_map 四类标准结果
✅动态命名,适配不同变量(如 NPP vs Tem)

import os
import numpy as np
import rasterio
from scipy.stats import pearsonr
from tqdm import tqdm
def read_stack(files, max_valid=1e5):
"""读取 tif 文件栈并进行 nodata 与异常值清理"""
stack = []
for f in tqdm(files, desc=f'Reading {os.path.basename(os.path.dirname(files[0]))}'):
with rasterio.open(f) as src:
data = src.read(1).astype(np.float32)
nodata = src.nodata
if nodata is not None:
data[data == nodata] = np.nan
data[data > max_valid] = np.nan
stack.append(data)
return np.array(stack), src.meta.copy()
def pearson_pixelwise(stack1, stack2, alpha=0.05):
"""逐像元 Pearson 相关性分析"""
T, H, W = stack1.shape
r_map = np.full((H, W), np.nan, dtype=np.float32)
p_map = np.full((H, W), np.nan, dtype=np.float32)
sig_mask = np.zeros((H, W), dtype=np.uint8)
for i in tqdm(range(H), desc='Processing Rows'):
for j in range(W):
x = stack1[:, i, j]
y = stack2[:, i, j]
valid = np.isfinite(x) & np.isfinite(y)
if np.sum(valid) >= 4:
x_valid, y_valid = x[valid], y[valid]
if np.std(x_valid) > 0 and np.std(y_valid) > 0:
r, p = pearsonr(x_valid, y_valid)
r_map[i, j] = r
p_map[i, j] = p
if p < alpha:
sig_mask[i, j] = 1
return r_map, p_map, sig_mask
def save_raster(array, meta, out_path, dtype='float32'):
"""保存 tif 文件,自动处理 nodata 问题"""
meta = meta.copy()
meta.update(dtype=dtype, count=1)
if dtype == 'uint8':
meta.pop('nodata', None)
with rasterio.open(out_path, 'w', **meta) as dst:
dst.write(array, 1)
def main():
base_path = os.getcwd()
NPP_dir = os.path.join(base_path, 'data', 'NPP') # 修改变量路径
TEM_dir = os.path.join(base_path, 'data', 'tem')
result_dir = os.path.join(base_path, 'results')
os.makedirs(result_dir, exist_ok=True)
# 设置变量名组合用于文件名生成
var1_name = os.path.basename(os.path.normpath(NPP_dir))
var2_name = os.path.basename(os.path.normpath(TEM_dir))
var_name = f"{var1_name}_{var2_name}"
NPP_files = sorted([os.path.join(NPP_dir, f) for f in os.listdir(NPP_dir) if f.endswith('.tif')])
TEM_files = sorted([os.path.join(TEM_dir, f) for f in os.listdir(TEM_dir) if f.endswith('.tif')])
assert len(NPP_files) == len(TEM_files), "NPP 和 TEM 文件数量不一致!"
npp_stack, ref_meta = read_stack(NPP_files)
tem_stack, _ = read_stack(TEM_files)
r_map, p_map, sig_mask = pearson_pixelwise(npp_stack, tem_stack, alpha=0.05)
save_raster(r_map, ref_meta, os.path.join(result_dir, f'{var_name}_r.tif'), dtype='float32')
save_raster(p_map, ref_meta, os.path.join(result_dir, f'{var_name}_p.tif'), dtype='float32')
save_raster(sig_mask, ref_meta, os.path.join(result_dir, f'{var_name}_significant_mask.tif'), dtype='uint8')
r_sig_only = np.where(sig_mask == 1, r_map, np.nan)
save_raster(r_sig_only, ref_meta, os.path.join(result_dir, f'{var_name}_r_significant_only.tif'), dtype='float32')
if __name__ == '__main__':
main()
03 常见报错
❌ 报错解释:
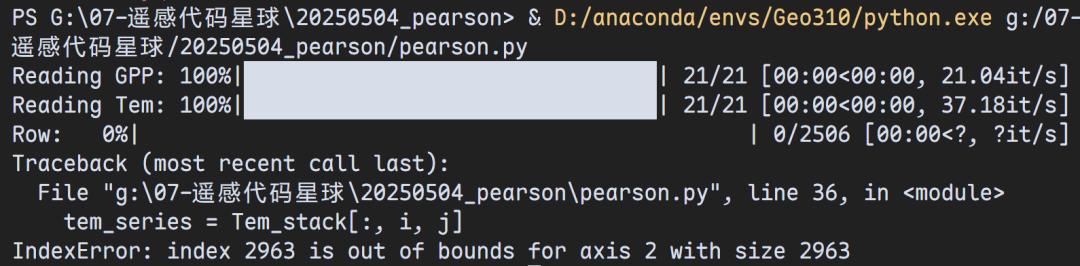
说明 GPP_stack.shape[2] != Tem_stack.shape[2],可能是:
GPP 是 (21, 2506, 2963)(21年,2506行,2963列)
Tem 是 (21, 2506, 2964) 或其他 → 列数不匹配!
这个时候就要检查你的数据的行列号是否一致!
😱
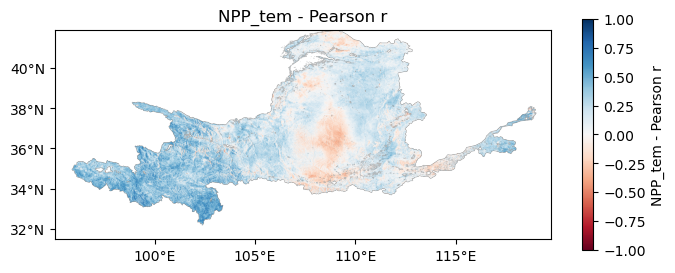
04 结果展示
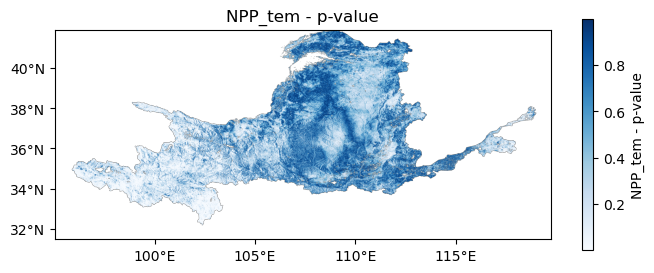

原始数据
附测试数据(含降水 Pre)供自由尝试!
本文可视化部分的代码以 Jupyter Notebook的
.ipynb文件展现
你也可以将其中内容复制到新的.py文件中
本人代码能力有限
欢迎同学们指出错误或优化意见
我们一起成长进步
❤
~后台回复C003获取代码+练习数据链接~
点击关注遥感代码星球


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









