







遥感代码星球的第005篇代码分享
2025/5/6 ·Tuesday·
今天分享:
基于栅格数据的偏相关分析
01原理
在遥感与生态研究中
我们常常想知道
两个变量之间的“真实关联性”
排除第三个变量的干扰影响
📌 举个例子:
我们想研究 植被生产力(NPP) 与 气温(TEM) 的关系,但又知道降水(PRE)也会影响 NPP。此时,偏相关系数可以告诉我们:在“控制住降水影响”之后,NPP 和气温之间到底还有没有显著关系。

2001—2021年黄河流域植被覆盖变化及其驱动因素[J].干旱区研究,2024,41(08):1373-1384.DOI:10.13866/j.azr.2024.08.11.
清晰一点的公式在这里:
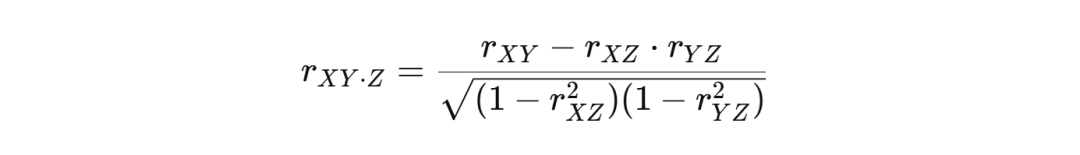
其中:
-
rXY:变量 X 与 Y 的皮尔逊相关系数
-
rXZ:变量 X 与 Z的皮尔逊相关系数
-
rYZ:变量 Y 与 Z 的皮尔逊相关系数
02 核心代码
1.本文使用数据:
MOD17A2H NPP
1km 温度降水数据
数据均预处理到500m
2.时间跨度:
2000-2020年
3.文件夹结构:

4.代码可以实现:
✅可视化运行进度
✅自动处理nodata与极端值
✅并行处理,加快运行速度

"""
逐像元偏相关分析(2000–2020),支持并行加速与显著性输出:
- 输出4张栅格图(偏相关 + p值)
"""
import os
import numpy as np
import rasterio
from sklearn.linear_model import LinearRegression
from scipy.stats import pearsonr
from tqdm import tqdm
from multiprocessing import Pool, cpu_count
# ─── 用户路径配置 ─────────────────────────────────────────────
base_path = os.getcwd()
NPP_dir = os.path.join(base_path, 'data', 'NPP')
TEM_dir = os.path.join(base_path, 'data', 'Tem')
PRE_dir = os.path.join(base_path, 'data', 'Pre')
result_dir = os.path.join(base_path, 'results')
os.makedirs(result_dir, exist_ok=True)
# ─── 函数:读取 TIF 文件───────────────────────────────────────
def read_stack(folder):
files = sorted([os.path.join(folder, f) for f in os.listdir(folder) if f.endswith('.tif')])
stack = []
for path in tqdm(files, desc=os.path.basename(folder)):
with rasterio.open(path) as src:
arr = src.read(1).astype(np.float32)
nodata = src.nodata
if nodata is not None:
arr[arr == nodata] = np.nan
stack.append(arr)
stack = np.stack(stack) # (T, H, W)
return stack, src.meta.copy()
# ─── 函数:偏相关计算(单像元) ─────────────────────────────
def partial_corr_with_p(x, y, z):
x, y, z = x.reshape(-1, 1), y.reshape(-1, 1), z.reshape(-1, 1)
valid = np.isfinite(x[:, 0]) & np.isfinite(y[:, 0]) & np.isfinite(z[:, 0])
if valid.sum() < 3:
return np.nan, np.nan
x_res = LinearRegression().fit(z[valid], x[valid]).predict(z[valid])
y_res = LinearRegression().fit(z[valid], y[valid]).predict(z[valid])
r, p = pearsonr((x[valid] - x_res).ravel(), (y[valid] - y_res).ravel())
return float(r), float(p)
# ─── 函数:处理单行像元(用于并行) ─────────────────────────
def process_one_row(args):
i, NPP, TEM, PRE = args
_, _, W = NPP.shape
r_row_TEM = np.full(W, np.nan, dtype=np.float32)
p_row_TEM = np.full(W, np.nan, dtype=np.float32)
r_row_PRE = np.full(W, np.nan, dtype=np.float32)
p_row_PRE = np.full(W, np.nan, dtype=np.float32)
for j in range(W):
x = NPP[:, i, j]
y1 = TEM[:, i, j]
y2 = PRE[:, i, j]
# 🌐 跳过该像元如果任一变量完全为空
if (np.isnan(x).all() or np.isnan(y1).all() or np.isnan(y2).all()):
continue # 默认值为 nan
r1, p1 = partial_corr_with_p(x, y1, y2)
r2, p2 = partial_corr_with_p(x, y2, y1)
r_row_TEM[j] = r1
p_row_TEM[j] = p1
r_row_PRE[j] = r2
p_row_PRE[j] = p2
return i, r_row_TEM, p_row_TEM, r_row_PRE, p_row_PRE
# ─── 并行执行偏相关分析 ─────────────────────────────────────
def pixelwise_partial_corr_parallel(NPP, TEM, PRE, workers=None):
T, H, W = NPP.shape
r_TEM = np.full((H, W), np.nan, dtype=np.float32)
p_TEM = np.full((H, W), np.nan, dtype=np.float32)
r_PRE = np.full((H, W), np.nan, dtype=np.float32)
p_PRE = np.full((H, W), np.nan, dtype=np.float32)
args = [(i, NPP, TEM, PRE) for i in range(H)]
with Pool(processes=workers or cpu_count()) as pool:
for result in tqdm(pool.imap_unordered(process_one_row, args), total=H, desc='🔁 Parallel Rows'):
i, r_row_TEM, p_row_TEM, r_row_PRE, p_row_PRE = result
r_TEM[i, :] = r_row_TEM
p_TEM[i, :] = p_row_TEM
r_PRE[i, :] = r_row_PRE
p_PRE[i, :] = p_row_PRE
return (r_TEM, p_TEM), (r_PRE, p_PRE)
# ─── 函数:保存 GeoTIFF ─────────────────────────────────────
def save_raster(data, path, meta):
meta.update(count=1, dtype='float32', nodata=np.nan)
with rasterio.open(path, 'w', **meta) as dst:
dst.write(data, 1)
# ─── 主执行流程 ──────────────────────────────────────────────
if __name__ == '__main__':
print("🔍 正在加载数据...")
NPP, meta = read_stack(NPP_dir)
TEM, _ = read_stack(TEM_dir)
PRE, _ = read_stack(PRE_dir)
print("🧠 开始并行偏相关计算...")
(r_TEM, p_TEM), (r_PRE, p_PRE) = pixelwise_partial_corr_parallel(NPP, TEM, PRE, workers=12)
print("💾 正在保存结果...")
save_raster(r_TEM, os.path.join(result_dir, 'partial_corr_NPP_TEM.tif'), meta)
save_raster(p_TEM, os.path.join(result_dir, 'pvalue_NPP_TEM.tif'), meta)
save_raster(r_PRE, os.path.join(result_dir, 'partial_corr_NPP_PRE.tif'), meta)
save_raster(p_PRE, os.path.join(result_dir, 'pvalue_NPP_PRE.tif'), meta)
print("✅ 分析完成!输出保存在:", result_dir)
04 通用版:逐像元偏相关分析(任意变量数量)
当我们的变量很多时
一个一个的添加变量代码就太过麻烦了
以下代码可以很好地做到:
✅自动跳过 nodata
✅ 多核并行
✅主变量可配置(几个都可以)
✅ 输出偏相关与 p 值栅格图
只需要在代码中修改这2行
variable_names = ['NPP', 'TEM', 'PRE', 'SR','........']target_variable = 'NPP'
关注遥感代码星球
后台回复 C004即可获得完整代码及数据哦~
05 结果展示
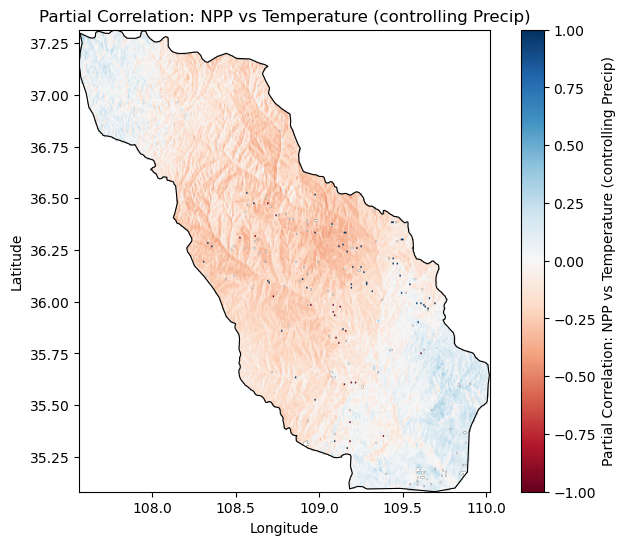
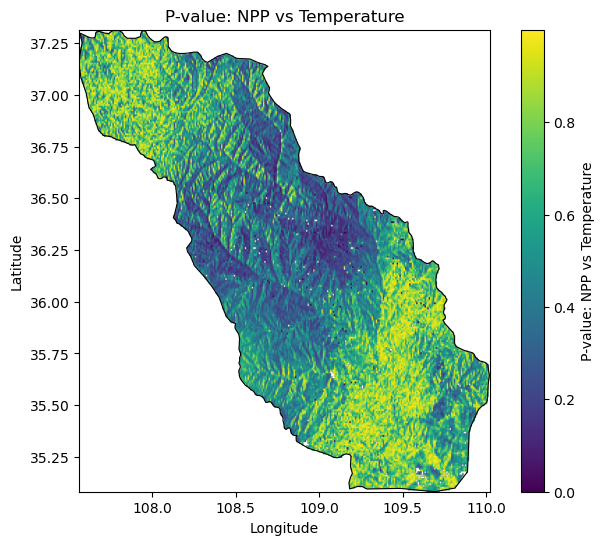
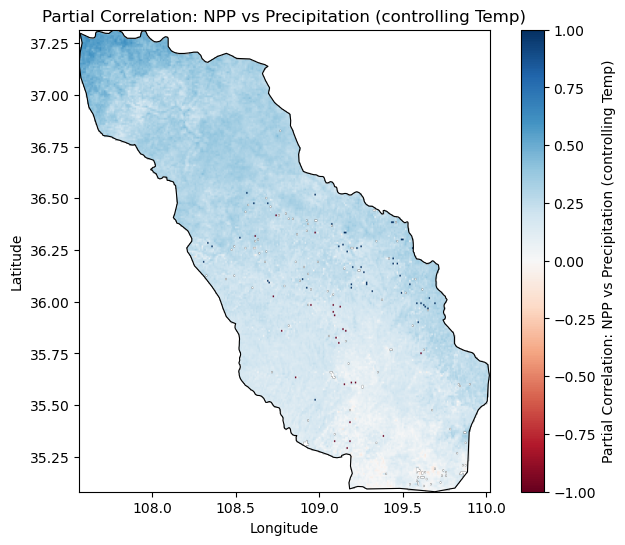
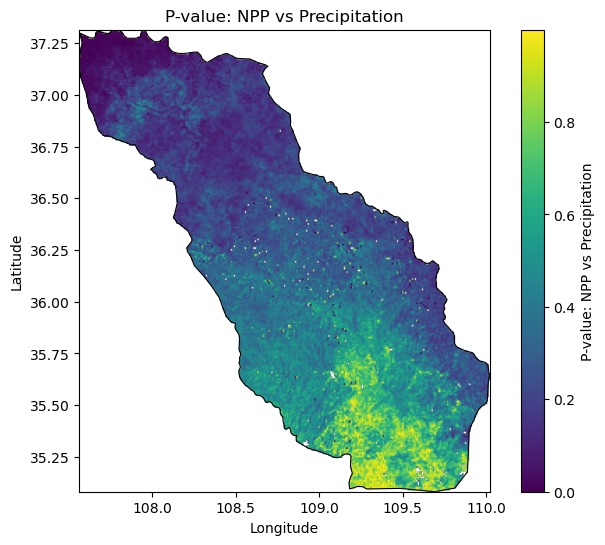
本文可视化部分的代码以 Jupyter Notebook的
.ipynb文件展现
你也可以将其中内容复制到新的.py文件中
本人代码能力有限
努力为大家提供新手小白也能看懂的步骤
欢迎同学们指出错误或优化意见
我们一起成长进步
❤
~后台回复C004获取代码和示例数据链接~
点击关注遥感代码星球

















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









