









目录
3.IoU指标(Intersection over Union)
非极大值抑制(Non-Maximum Suppression)
双阶段网络与单阶段网络
Two-stage:第一阶段网络用于候选区域提取;第二阶段对候选区域进行分类和精确坐标回归。
-
单阶段网络准确度不如双阶段网络,训练不均衡
- 负例过多,正例过少。
- 大多数负例十分容易区分,网络无法学习到有用的信息。如果训练数据存在大量这样的样本,将导致难以收敛。
-
双阶段网络如何解决训练中的不均衡
- RPN网络中,根据前景置信度的高度选择最有可能的候选区域,从而避免大量容易区分的负例。
- 训练过程中根据交并比进行采样,将正负样本比例设为1:3,防止过多负例出现。
常用数据集介绍及数据交互
-
Pascal Voc 2007,2012
常用于分类(20)和检测(bounding box);
-
COCO2014,2014,2015,2017
目标实例,目标观测点,看图说话;
bbox:[x,y,width,height]中x,y为bounding box左上角的点
评价指标及计算方法介绍
1.基本数据指标
| 真实情况 | 预测情况 | |
| 正例 | 反例 | |
| 正例 | TP(真正) | FN(假反-真正) |
| 反例 | FP(假正-真反) | TN(真反) |
- TP(True positives):实际为正例,且被分类器划分为正例的实例数;
- FP(False positives):实际为负例,但被分类器划分为正例的实例数;
- FN(False negatives):实际为正例,但被分类器划分为负例的实例数;
- TN(True negatives):实际为负例,但被分类器划分为正例的实例数;
- Precision = TP/(TP + FP) / 所有被模型检测为正样本的数据的数量
- Recall = TP/(TP + FN) = TP / 所有真实类别为正样本的数据的数量

2.PR曲线:结果P,R越高越好,但某些情况下互相矛盾。
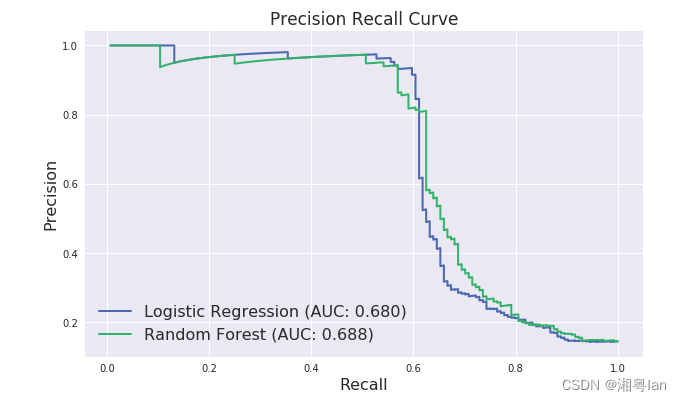
- PR曲线下方的面积AUC(Area under Curve)去判断模型的好坏,越大越好。
3.IoU指标(Intersection over Union)
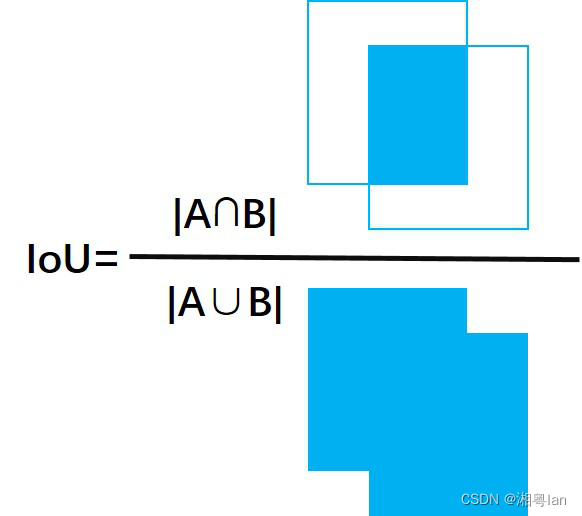
- 将原始图片送入训练好的模型之后,经过置信度阈值筛选之后(只考虑置信度高于某个阈值的预测结果),目标检测算法给出带有边界框的预测结果。
- IoU是预测框与ground truth的交集和并集的比值。
4.目标检测中的PR
- TP :IoU > 0.5的检测框数量(同一Ground Truth只计算一次)
- FP:IoU
- FN:没有检测到的GT(Ground Truth)的数量
- **Pascal Voc数据集中标注为difficult的数据不计入计算**
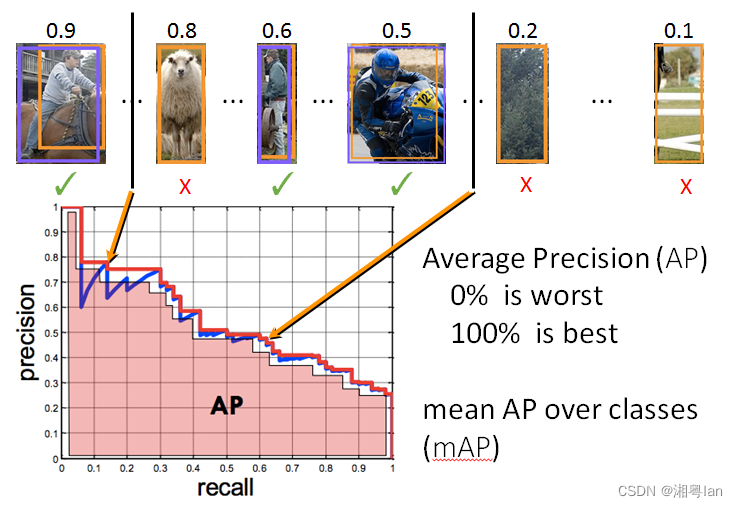
5.mAP的计算
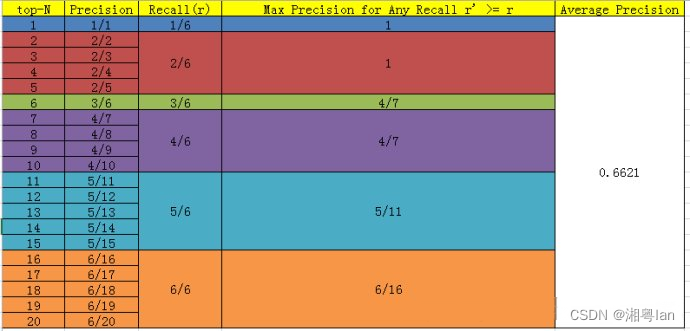
- AP值(2010年前:PASCAL VOC竞赛定义):recall的值从0到1划分为11份(0,0.1,……,0.9,1.0),每个recall区间(0-0.1,0.1-0.2……,0.9-1.0)上计算准确率的最大值,然后再计算这些准确率最大值的综合并平均。
- AP值(2010年后):11份recall换成了PR曲线中的所有recall数据点。对于某个recall值r,precision值取所有recall > = r中的最大值(这样保证了p - r曲线是单调递减的,避免了曲线出现摇摆)这种方法叫做all - points - interpolation。这个AP值也就是PR曲线下的面积值。
- 代码如下:
def voc_ap(rec, prec, use_07_metric=False):
""" ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
print(mpre)
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
print(mpre)
return ap6.COCO中mAP的计算方法
- 采用的是IoU(用于决定是否为TP)在【0.5:0.05:0.95】计算10次AP,然后求平均值的方法计算AP。
数据增强及预处理方法
1.图像归一化
- 一般为灰度归一化,即减去均值;保持纵横比,将图像的短边缩放至同一大小
2.图像增强:翻转、裁剪、饱和度亮度变换、噪声
- 图像裁剪:覆盖尽可能多的bbox,同时考虑区域差异化。
3.图像的纵横比处理
- 选定图像纵横比的上下限,分别为0.5和2,纵横比超过此范围的需要进行截取操作。
非极大值抑制(Non-Maximum Suppression)
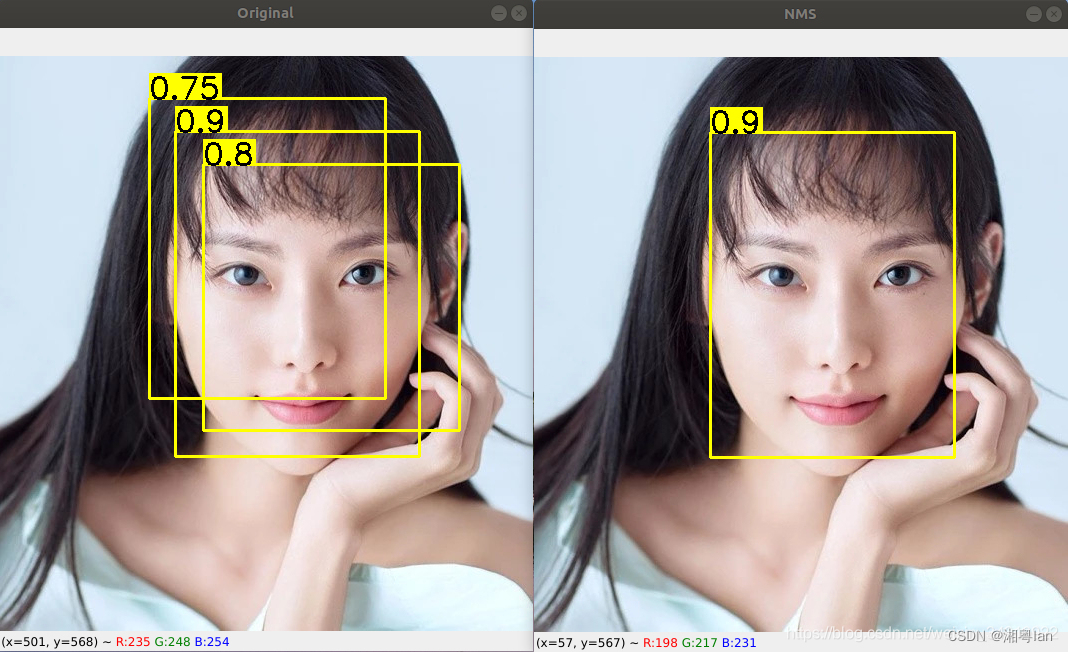
一般是为了去除模型预测后的多余框,其一般设有一个nms_threshold = 0.5,具体实现思路如下:
- 选取这类box中的scores最大的哪一个,记为box_best,并保留它。
- 计算box_best与其余的box的IoU。
- 如果其IoU>0.5了,那么就舍弃这个box(由于可能两个box表示统一目标,所以保留分数高的那一个)。
- 从最后剩余的boxes中,再找到最大scores的哪一个,如此循环往复
















 4370
4370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











