






文章目录
1. 引言:什么是RNN以及它的重要性
循环神经网络(Recurrent Neural Networks,简称RNN)是一种在序列数据处理上具有显著优势的神经网络架构。与传统的神经网络相比,RNN的独特之处在于它能够处理并记忆序列中的前一个元素的信息,这使得它在处理像语音、文本等序列化数据时显得格外重要。
RNN简介
RNN是一种专为处理和预测序列数据而设计的神经网络。它们通过在网络层之间传递状态信息,可以对输入序列中的时间动态进行建模。这种内部状态的更新使得RNN在处理时间序列数据(如股票价格、天气模式)和自然语言处理(如翻译和语音识别)等领域表现出色。
RNN在机器学习中的作用和应用场景
在机器学习领域,RNN主要用于那些输入和输出都是序列数据的任务。例如,在自然语言处理中,RNN可以用于文本生成、机器翻译和语音识别。在其他领域,比如视频处理和音乐生成中,RNN能够识别和生成时间上连续的数据。RNN的这种能力使其在许多实际应用中变得不可或缺,尤其是在需要理解整个数据序列以做出预测或决策的场景中。
在接下来的部分中,我们将更深入地探讨RNN的工作原理、关键特点、变体以及如何在实际项目中应用RNN。
2. RNN的工作原理
在深入理解RNN的工作原理之前,首先需要了解一些神经网络的基础知识。神经网络是由相互连接的节点(或称为神经元)组成的网络,每个节点都会对输入数据进行某种形式的处理。在传统的神经网络中,所有的输入都是独立处理的,这意味着网络无法在处理当前输入时考虑到之前的输入。而RNN的设计就是为了解决这个问题。
神经网络基础
传统的神经网络,如前馈神经网络(Feedforward Neural Networks),数据流只在一个方向上流动:从输入到输出。这些网络在处理与时间或序列无关的问题时表现良好,例如图像识别。然而,对于需要考虑数据的时间序列信息的任务(如语言模型),这种一次性处理模式就显得力不从心。
RNN的结构和运作方式
RNN的核心思想是使用循环,使得网络能够将信息从一个步骤传递到下一个步骤。这种循环结构使得网络能够保留某种状态,即网络在处理当前输入时,同时考虑之前的输入。在RNN中,每个序列元素都会更新网络的隐藏状态。这个隐藏状态是网络记忆之前信息的关键,它可以被视为网络的“记忆”。
为了处理序列中的每个元素,RNN会对每个输入执行相同的任务,但每一步都会有一些小的改变,因为它包含了之前步骤的信息。这种结构使得RNN在处理序列数据时非常有效,例如,在文本中,当前单词的含义可能取决于之前的单词。
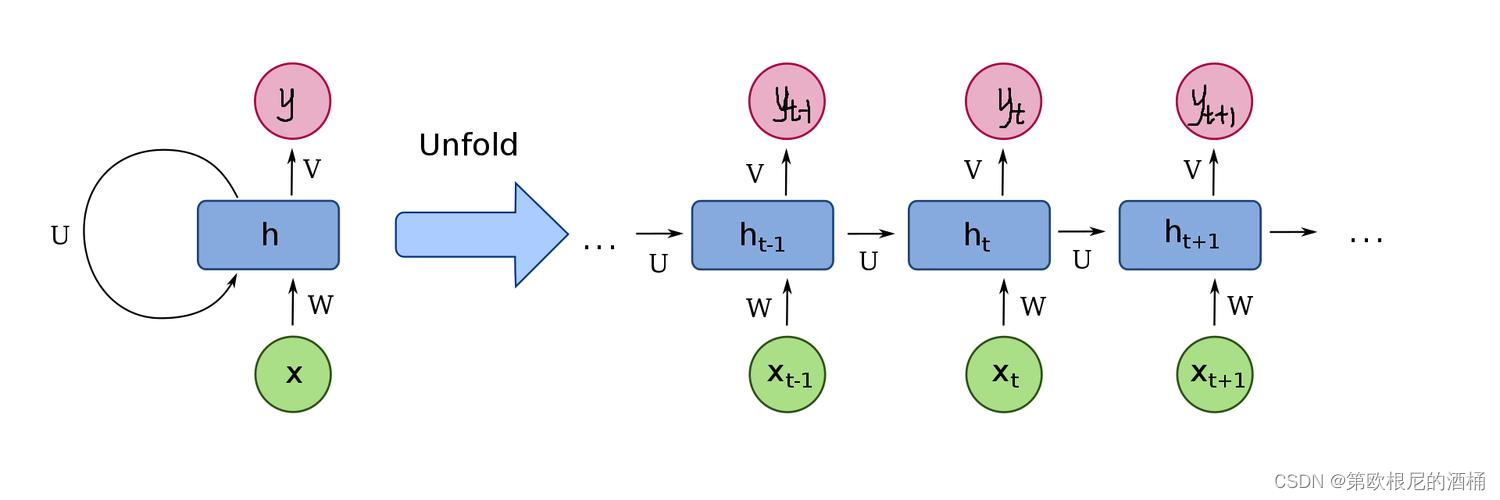
图中的链式结构揭示了 RNN 与序列的内在相关性,是处理时序数据最自然的网络架构。
循环单元的作用
在RNN中,循环单元的作用是关键。这些单元负责在每个时间步更新隐藏状态。在最简单的RNN形式中,这种状态只是前一步隐藏状态的函数,以及当前步骤的输入。这种机制允许网络随时间“记住”信息,并据此处理新输入。但这也带来了一些挑战,尤其是在处理长序列时。
在接下来的部分中,我们将探讨RNN的关键特点和它面临的一些挑战,如长期依赖问题,以及如何通过RNN的不同变体来解决这些问题。
3. RNN的关键特点与挑战
RNN的设计允许它在序列数据处理方面表现出色,但同时也带来了一些独特的挑战。这部分将探讨RNN的几个关键特点,以及它面临的主要挑战,并提供相应的解决策略,包括简单的代码示例。
参数共享
一个显著的特点是RNN在不同时间步之间共享参数。这意味着学习到的权重和偏差在处理每个输入时都是相同的,与传统前馈神经网络不同,后者在每一层使用不同的参数。这种参数共享不仅降低了模型的复杂性和计算需求,也帮助模型在处理任何长度的序列时都保持有效。
长期依赖问题
长期依赖问题是RNN面临的一大挑战。在理想情况下,RNN应能够使用其“记忆”来连接序列中相隔较远的信息。然而,在实际应用中,RNN往往难以学习这些长距离依赖。这主要是因为梯度消失和梯度爆炸问题,即在训练过程中,用于更新网络权重的梯度可能变得非常小(消失)或非常大(爆炸),使得训练变得非常困难。
门控机制(例如LSTM和GRU)
为了解决长期依赖问题,研究者引入了门控机制,如长短期记忆网络(LSTM)和门控循环单元(GRU)。这些结构通过精心设计的门控系统来控制信息的流入和流出,这有助于网络保留长期信息,同时避免梯度消失和爆炸。
代码示例:简单RNN实现
以下是使用Python和TensorFlow实现一个简单RNN的例子。这个例子展示了如何创建一个基本的RNN模型来处理序列数据。
import tensorflow as tf
from tensorflow.keras.layers import SimpleRNN, Dense
# 假设我们的输入数据是长度为100的序列,每个时间点的特征维度为10
input_shape = (100, 10)
# 创建一个简单的RNN模型
model = tf.keras.models.Sequential([
SimpleRNN(50, return_sequences=True, input_shape=input_shape),
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer='adam')
print(model.summary())
在这个例子中,我们使用了SimpleRNN层,其中包含50个隐藏单元。return_sequences=True参数确保每个时间点都输出状态,这对于处理序列问题很重要。然后,一个Dense层被用来输出最终的预测。这个模型可以用于时间序列预测或其他类似的序列任务。
接下来,我们将探讨RNN的几种变体,它们在处理特定问题上可能比标准RNN表现更好。
4. RNN的变体
RNN的一些变体被开发出来,用以解决标准RNN在处理特定问题时的不足,尤其是长期依赖问题。下面将介绍三种常见的RNN变体:长短期记忆网络(LSTM)、门控循环单元(GRU)和双向RNN。
LSTM(长短期记忆网络)
LSTM是一种特殊类型的RNN,专门设计来避免标准RNN中的长期依赖问题。LSTM通过引入三种不同的门(遗忘门、输入门和输出门)来控制信息的流动,这有助于模型在需要时保持或丢弃信息。

GRU是LSTM的一个变体,它将LSTM中的遗忘门和输入门合并为一个单一的“更新门”。它还混合了隐藏状态和当前状态的概念,简化了模型的结构。GRU在某些任务上与LSTM有着相似的性能,但通常来说,它的结构更简单,训练速度更快。
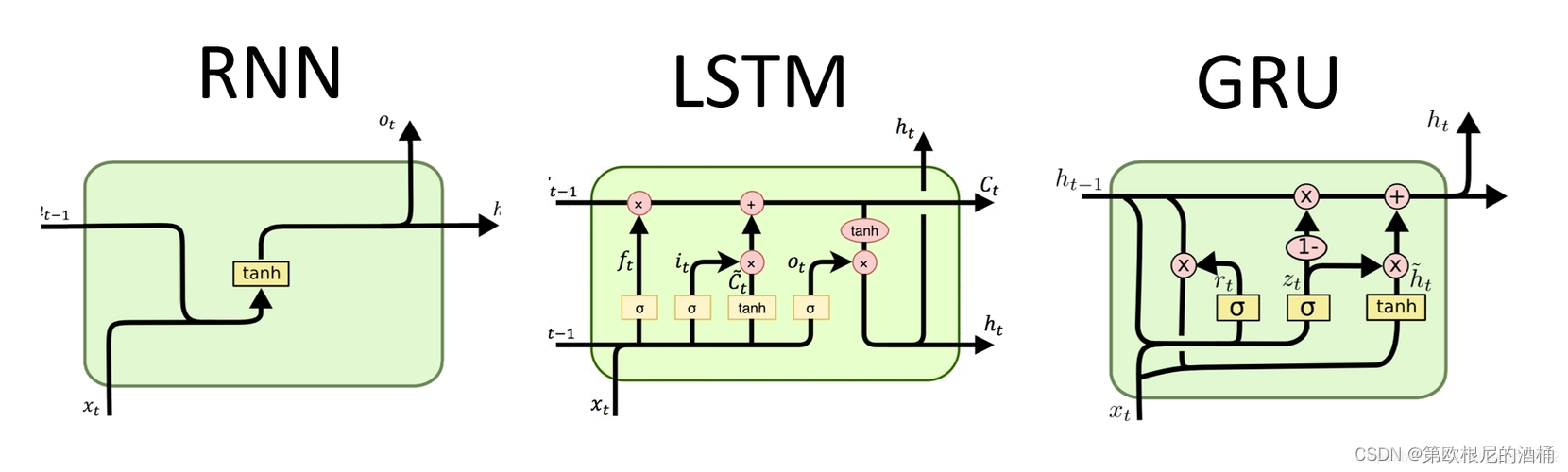
双向RNN
双向RNN(Bi-RNN)是另一种RNN的变体,它包含两个单独的RNN层:一个沿着时间正向传播,另一个沿着时间逆向传播。这种结构使得网络能够同时获得过去和未来的信息,这在许多序列预测任务中非常有用。
代码示例:LSTM网络实现
以下是使用Python和TensorFlow实现一个简单的LSTM网络的例子,用于演示如何使用LSTM处理序列数据。
import tensorflow as tf
from tensorflow.keras.layers import LSTM, Dense
# 假设我们的输入数据是长度为100的序列,每个时间点的特征维度为10
input_shape = (100, 10)
# 创建一个包含LSTM层的模型
model = tf.keras.models.Sequential([
LSTM(50, return_sequences=True, input_shape=input_shape),
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer='adam')
print(model.summary())
在这个例子中,我们使用了LSTM层替换了先前例子中的SimpleRNN层。这里的LSTM层也有50个隐藏单元,并且我们同样使用了return_sequences=True参数,以保证在每个时间点都输出状态。
使用LSTM(或GRU)的主要优势在于其能力在处理长序列数据时更有效地学习和保持长期依赖信息。
接下来的部分将介绍RNN在实际应用中的一些案例,这将帮助我们更好地理解如何将这些理论应用到真实世界的问题中。
5. 实际应用案例
RNN及其变体在各种实际应用中表现卓越,尤其是那些涉及到时间序列数据或序列预测的领域。以下是RNN在几个关键领域的应用示例,以及相应的代码示例。
语言模型
在自然语言处理领域,RNN被广泛应用于构建语言模型。语言模型的目标是根据前面的单词来预测序列中的下一个单词。这种模型是许多NLP任务的基础,如机器翻译、语音识别和文本生成。
代码示例:
使用TensorFlow和Keras构建一个简单的文本生成模型:
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.datasets import imdb
# 加载数据集
# 这里我们使用IMDb影评数据集作为示例
# 仅考虑词汇表中最常见的10000个词,并将评论剪裁到最多500个单词
max_features = 10000
maxlen = 500
batch_size = 32
(input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=max_features)
input_train = sequence.pad_sequences(input_train, maxlen=maxlen)
input_test = sequence.pad_sequences(input_test, maxlen=maxlen)
# 建立模型
model = Sequential()
model.add(Embedding(max_features, 128, input_length=maxlen))
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(input_train, y_train, batch_size=batch_size, epochs=15, validation_data=(input_test, y_test))
在这个示例中,我们首先加载并预处理IMDb影评数据集,然后建立一个包含嵌入层、LSTM层和全连接层的模型。最后,我们使用二元交叉熵损失函数来训练模型。
时间序列预测
RNN在金融、气象和其他领域的时间序列分析和预测中也非常有用。例如,它们可以用于预测股票价格或天气变化。
代码示例:
使用RNN进行简单的时间序列预测:
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
# 生成模拟数据
def generate_time_series(batch_size, n_steps):
freq1, freq2, offsets1, offsets2 = np.random.rand(4, batch_size, 1)
time = np.linspace(0, 1, n_steps)
series = 0.5 * np.sin((time - offsets1) * (freq1 * 10 + 10)) # 波形 1
series += 0.2 * np.sin((time - offsets2) * (freq2 * 20 + 20)) # 波形 2
series += 0.1 * (np.random.rand(batch_size, n_steps) - 0.5) # 噪声
return series[..., np.newaxis].astype(np.float32)
n_steps = 50
series = generate_time_series(10000, n_steps + 1)
X_train, y_train = series[:7000, :n_steps], series[:7000, -1]
X_valid, y_valid = series[7000:9000, :n_steps], series[7000:9000, -1]
X_test, y_test = series[9000:, :n_steps], series[9000:, -1]
# 建立RNN模型
model = Sequential([
SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
SimpleRNN(20),
Dense(1)
])
model.compile(loss="mean_squared_error", optimizer="adam")
model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
在这个例子中,我们首先生成一个模拟的时间序列数据集,然后使用一个包含两个SimpleRNN层和一个全连接层的模型来进行预测。
序列生成(如文本生成)
除了语言模型外,RNN也可以用于生成新的文本序列。这种类型的模型可以基于已有的文本样本来生成全新的文本,例如编写诗歌或音乐。
接下来,我们将讨论如何开始使用RNN,包括建立基本的RNN模型,选择合适的框架和库,以及提供简单的示例代码。
6. 开始使用RNN
要开始使用RNN,你需要了解基本的模型搭建步骤、选择合适的框架和库,以及掌握一些基础的代码实现。这部分将提供一个简单的RNN模型构建的指南,并给出一个基础的代码示例。
基本的RNN模型搭建步骤
-
数据预处理
将你的数据转换为适合RNN模型的格式。对于时间序列数据,这通常意味着将数据转换为一个三维数组,即[samples, time_steps, features]。 -
构建模型
选择适合你的问题的RNN架构,例如SimpleRNN、LSTM或GRU。你还可以根据需要添加额外的层,如Dense层或Dropout层以防过拟合。 -
编译模型
选择适当的损失函数和优化器,并使用compile方法进行配置。 -
训练模型
使用你的数据训练模型,可以通过调整epochs和batch_size来优化训练过程。 -
评估和预测
评估模型的性能,并在新的数据上进行预测。
流行的RNN框架和库
- TensorFlow和Keras:提供了广泛的API和工具,适用于快速实验和构建复杂的RNN模型。
- PyTorch:在研究领域非常受欢迎,因其动态计算图和Python式的编程风格而备受青睐。
- 其他库:如Theano、Caffe等,也可以用于RNN的实现,但通常不如TensorFlow和PyTorch流行。
简单示例代码:股票价格预测RNN
下面是一个使用TensorFlow和Keras创建一个简单的RNN模型来预测股票价格的示例。
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
# 假设data是一个包含股票价格的NumPy数组
# 这里仅作为示例,你需要替换为真实数据
data = np.random.rand(1000, 1)
# 数据预处理
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(data)
# 创建时间序列数据
def create_dataset(dataset, look_back=1):
X, Y = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
X.append(a)
Y.append(dataset[i + look_back, 0])
return np.array(X), np.array(Y)
look_back = 5
X, Y = create_dataset(scaled_data, look_back)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
# 重塑输入数据的形状
X_train = np.reshape(X_train, (X_train.shape[0], 1, X_train.shape[1]))
X_test = np.reshape(X_test, (X_test.shape[0], 1, X_test.shape[1]))
# 创建并训练LSTM网络
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(1, look_back)))
model.add(LSTM(50))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(X_train, Y_train, epochs=100, batch_size=1, verbose=2)
# 预测和评估
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# 逆转预测值的缩放
train_predict = scaler.inverse_transform(train_predict)
Y_train = scaler.inverse_transform([Y_train])
test_predict = scaler.inverse_transform(test_predict)
Y_test = scaler.inverse_transform([Y_test])
# 计算和打印模型性能
# 这里可以使用各种性能指标,例如均方误差等
在这个例子中,我们首先对股票价格数据进行了归一化处理,然后创建了时间序列数据集。接着,我们构建了一个包含两个LSTM层和一个Dense层的模型,并对其进行了训练和评估。
7. 总结与未来展望
RNN及其变体在处理序列数据方面取得了显著的成果,特别是在自然语言处理和时间序列分析领域。然而,这个领域仍在不断发展,未来可能会出现新的技术和方法。
RNN的局限性
虽然RNN在某些方面表现出色,但它们也有一些局限性。例如,标准的RNN在处理长序列时容易受到梯度消失或爆炸的影响,尽管LSTM和GRU等变体在一定程度上缓解了这个问题。此外,RNN在计算上通常比其他类型的神经网络更为复杂,特别是当涉及到长序列和大型网络时。
发展趋势
- Transformer模型:最近,Transformer模型在处理序列数据方面显示出了巨大的潜力,特别是在自然语言处理任务中。它们通过使用自注意力机制克服了RNN处理长序列时的一些限制。
- 更高效的架构:研究者们一直在寻找更高效的网络架构,以处理更长的序列并减少训练和推理时间。
其他相关技术
- 一次性模型(One-shot learning)和元学习(Meta-learning):这些技术正变得越来越重要,尤其是在需要模型快速适应新任务的场景中。
- 强化学习与RNN的结合:在某些序列决策问题中,将RNN与强化学习相结合正在成为一个有趣的研究领域。
学习资源
要进一步了解RNN及其相关技术,以下是一些有用的资源链接:
- TensorFlow官方文档 - TensorFlow RNN Tutorial
- PyTorch官方文档 - PyTorch RNN Tutorial
- Stanford University’s CS224n - Natural Language Processing with Deep Learning
- Coursera的深度学习专项课程 - Deep Learning Specialization by Andrew Ng
- 《深度学习》书籍 - Deep Learning by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
以上资源为你提供了从基础到高级的RNN知识,同时也覆盖了最新的研究和技术动态。不断学习和实践将帮助你更深入地理解这一复杂而充满潜力的领域。















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











