






引言:从数据采集痛点到AI赋能的突破
作为一名数据工程师,我长期面临两大挑战:高质量训练数据的稀缺性与动态网页反爬机制的限制。传统爬虫工具难以应对使用 JavaScript 方式渲染的页面,同时频繁的 IP 封禁和验证码更是让数据管道频繁中断。直到使用了亮数据(Bright Data)这款抓取神器,了解了其Web Scraping API与Scraping Browser之后,彻底改变了我的工作流程——我通过AI就绪型数据基础设施,实现了全天候实时数据抓取,以及端到端模型训练的无缝衔接。

一、 试用体验:从注册到部署的“零摩擦”体验
1. 极速开通
点击亮数据的官方网址,找到 “开始免费试用” 按钮,进行注册:
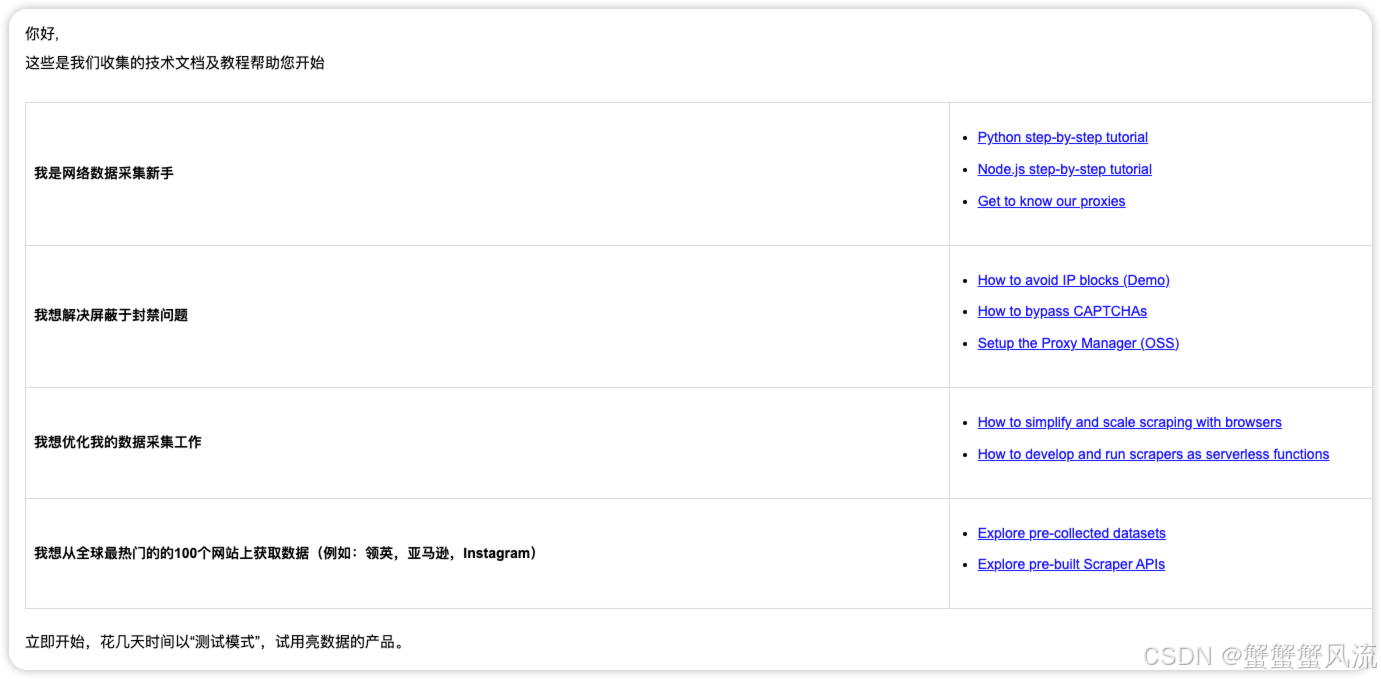
创建账号之后,官方会赠送你免费的额度。同时,技术团队还会给你的注册邮箱发送技术文档及教程。我觉得这一点做的很好,因为如果你是一个小白用户,这对你会是很有帮助。
有了免费额度,我们就可以开始创建抓取任务。
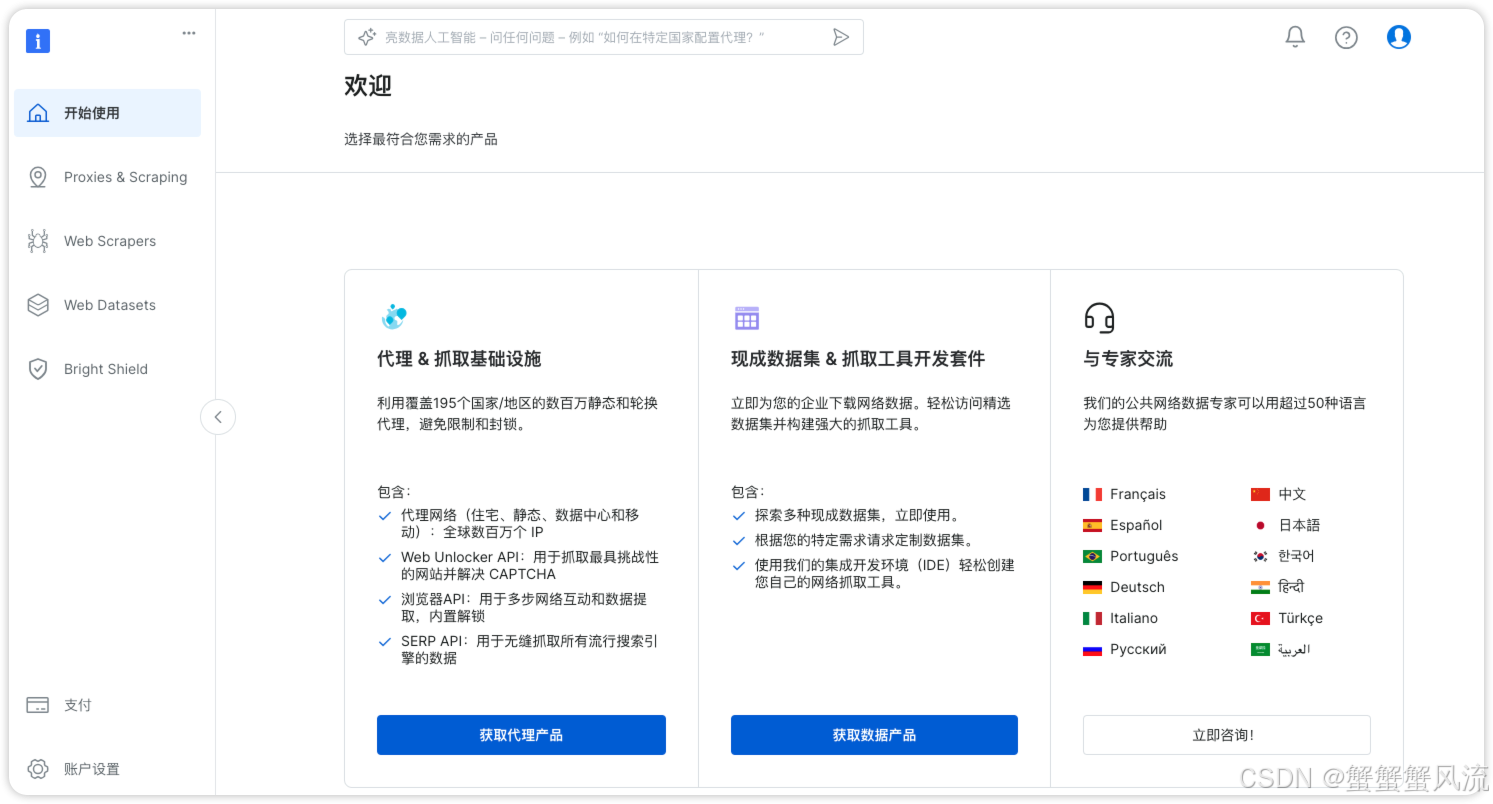
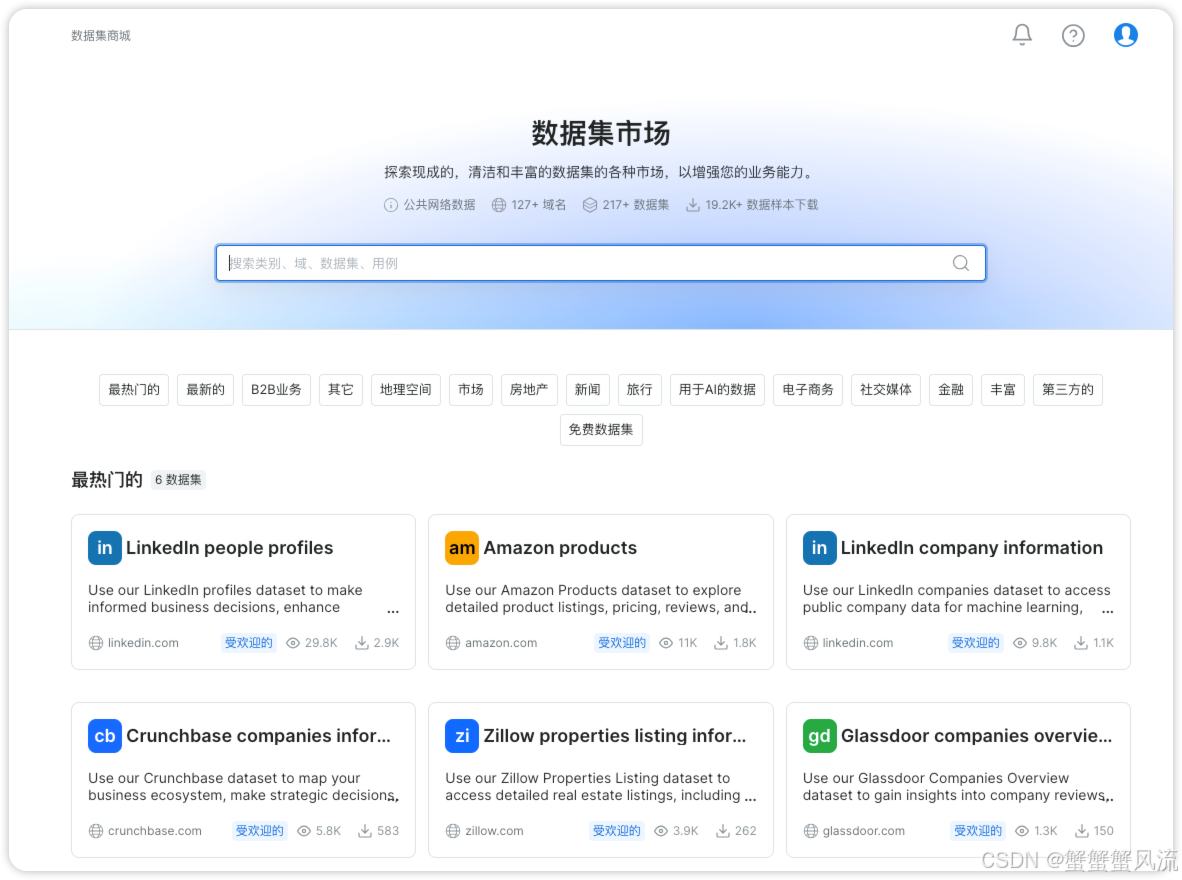
2. 丰富的数据集市场
目前亮数据的数据集市场提供了多种类型、多个行业(如房地产、旅行、电商、金融)等200多种预建的、结构化的、经过验证的数据集。同时,你还可以使用数据集创建平台生成自定义数据集。
3. 强大的抓取方案
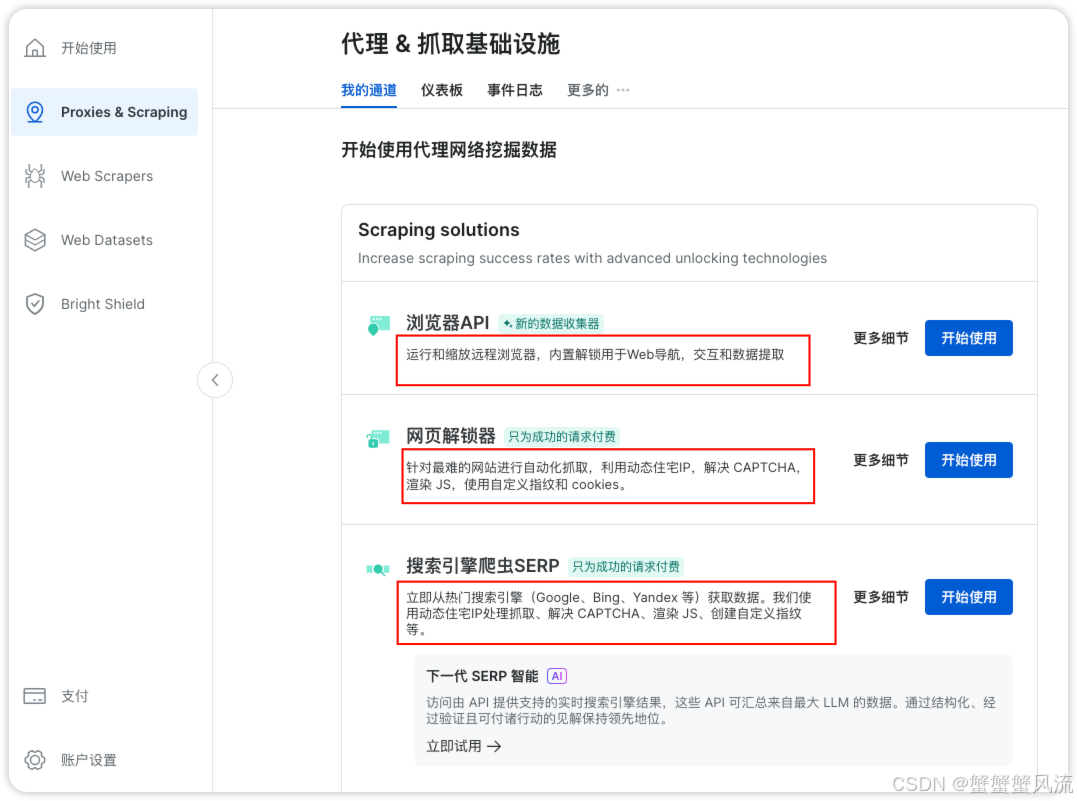
3.1 浏览器 API
亮数据借助浏览器API 能模拟人的操作(如点击、滚动),与浏览器建立交互(包括验证码的输入),并进行数据的提取。
3.2 网页解锁器
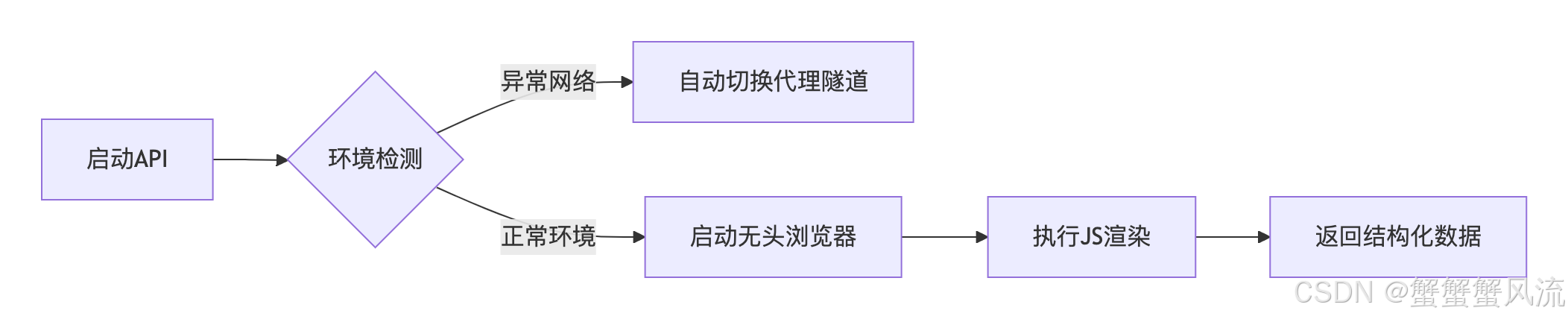
同时,针对有反爬技术的网站(如 JS 动态生成网页),亮数据有一个网页解锁器(Web Unlocker API),它利用动态住宅IP,你无需担忧访问限制、网络封锁或验证码拦截问题。该解锁器采用全真用户行为模拟技术,所有操作均在后台静默执行,支持无限并发请求发送,并确保获得完整响应数据且无拦截风险。
运行模式可以用下图进行理解:
3.3 搜索引擎爬虫 SERP
- 全搜索引擎覆盖
除此之前,它还支持 Google、Bing、Yandex、DuckDuckGo、Baidu 等主流搜索引擎,可抓取搜索结果页(SERP)的 关键字搜索、图片、购物、新闻、酒店、视频 等板块数据。 - 动态反反爬机制
• 智能代理管理:集成全球超 7200 万动态住宅 IP 池,自动切换 IP 以规避封禁风险。
• 浏览器指纹伪装:模拟真实用户设备参数(如 User-Agent、分辨率、时区)及行为轨迹(随机点击延迟、鼠标移动路径。
• 验证码自动解决:内置 AI 打码引擎,实时处理 reCAPTCHA、hCaptcha 等验证挑战。 - 结构化数据输出
返回 HTML/JSON 格式数据,支持直接解析或二次开发。例如:
// 示例:Google 购物搜索结果解析
{
"title": "Pizza Hut 限时优惠",
"price": "$12.99",
"rating": "4.8/5",
"url": "https://www.pizzahut.com/deals"
}
- 更具性价比
与传统的爬虫方案对比,在开发成本、稳定性、数据质量上都更胜一筹:

4. 无代码抓取
亮数据提供的爬虫库可以依托无代码抓取器,无需你调用 API,无需你写一行代码,就可以自动进行抓取。
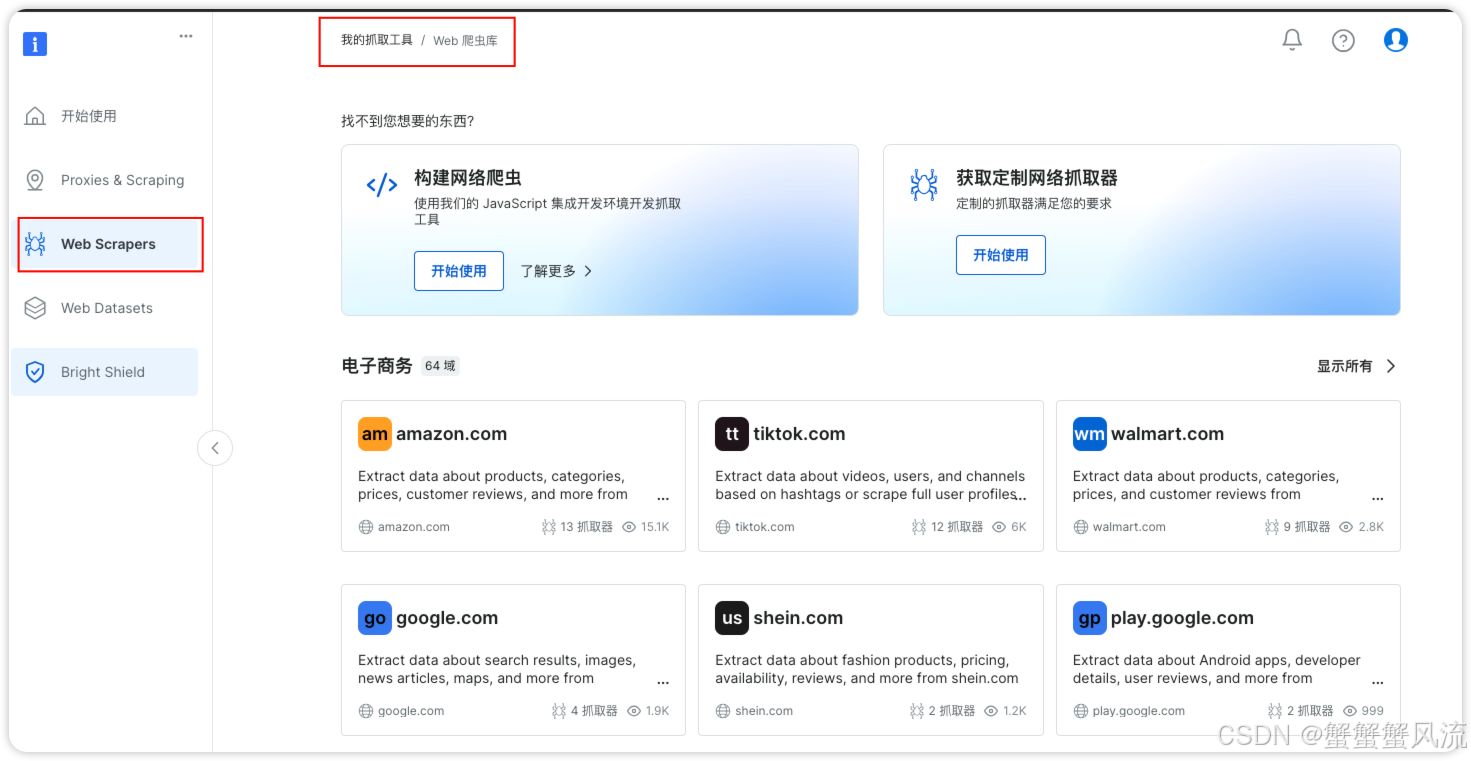
例如,这里选择通过 URL 爬取 Amazon 上的商品数据。然后,选择无代码抓取器。
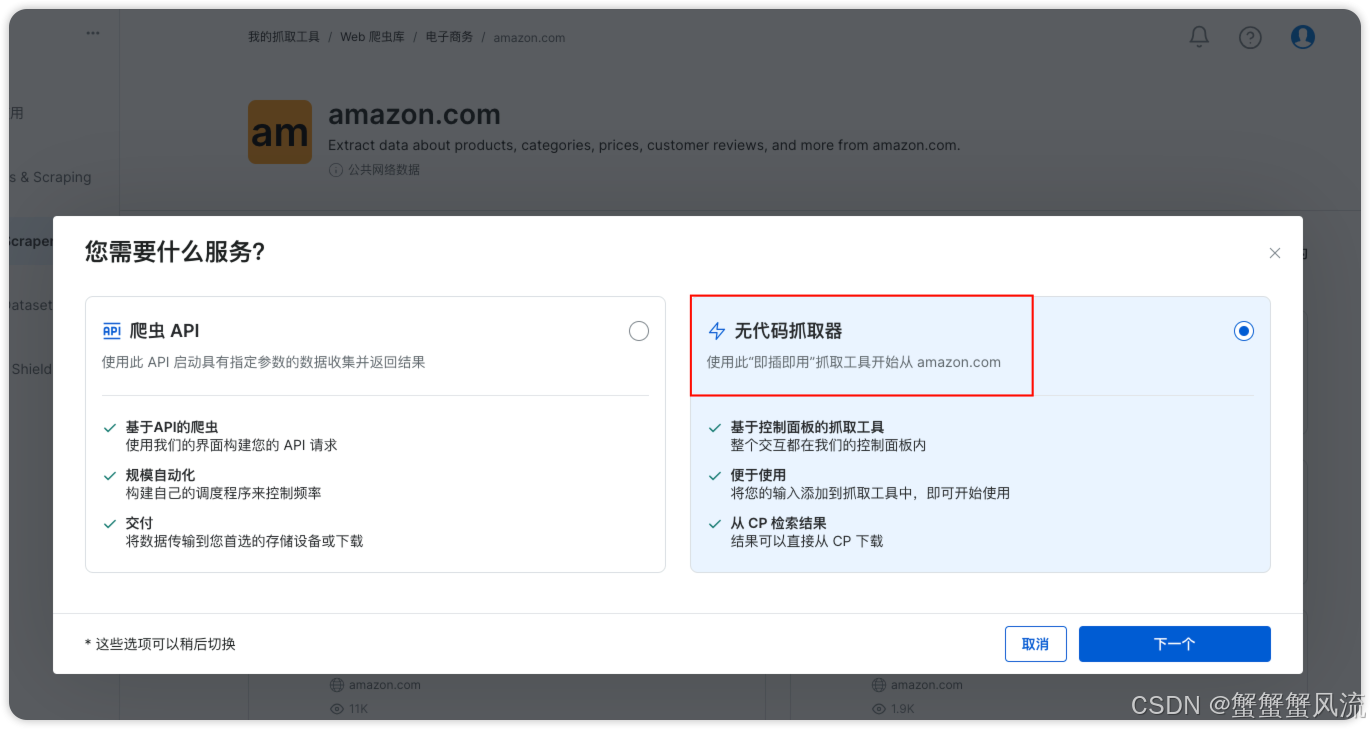
点击 Start Collecting 按钮就会开始抓取数据:
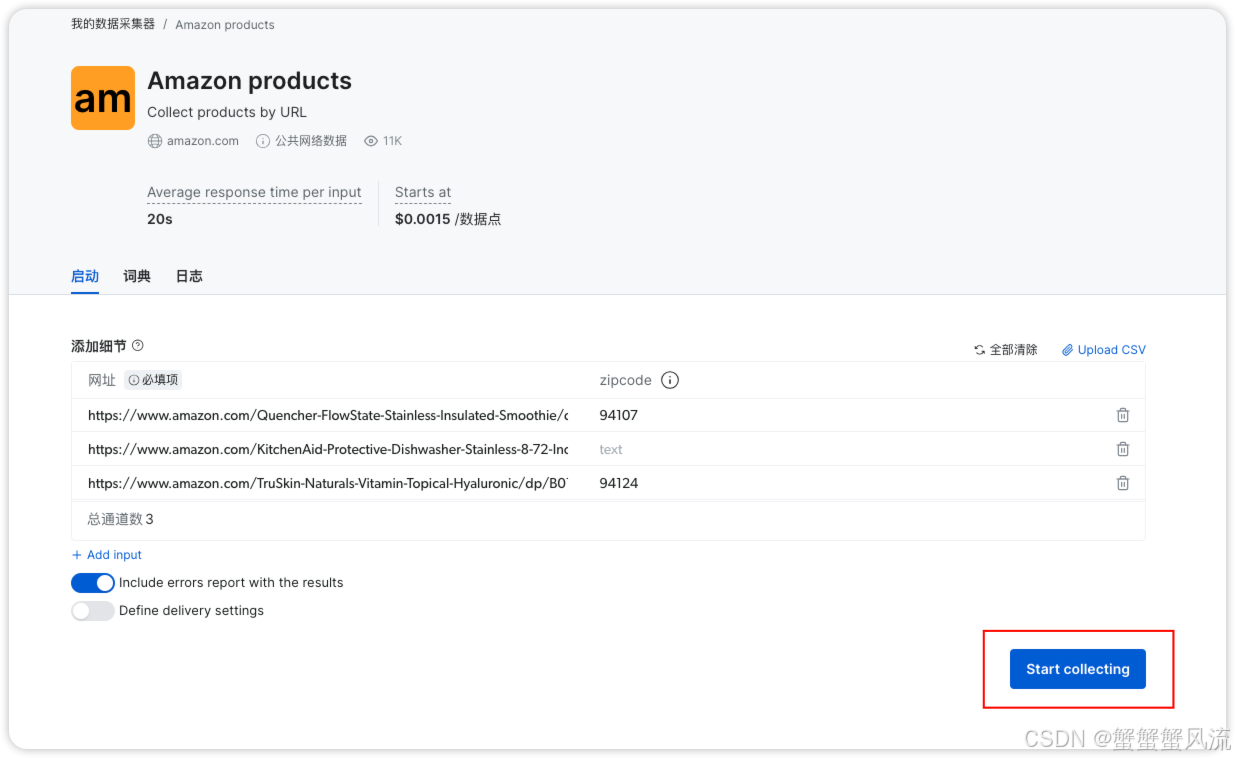
当在列表中显示 Ready, 说明爬取数据已经完成。你可以在日志中下载抓取的数据。
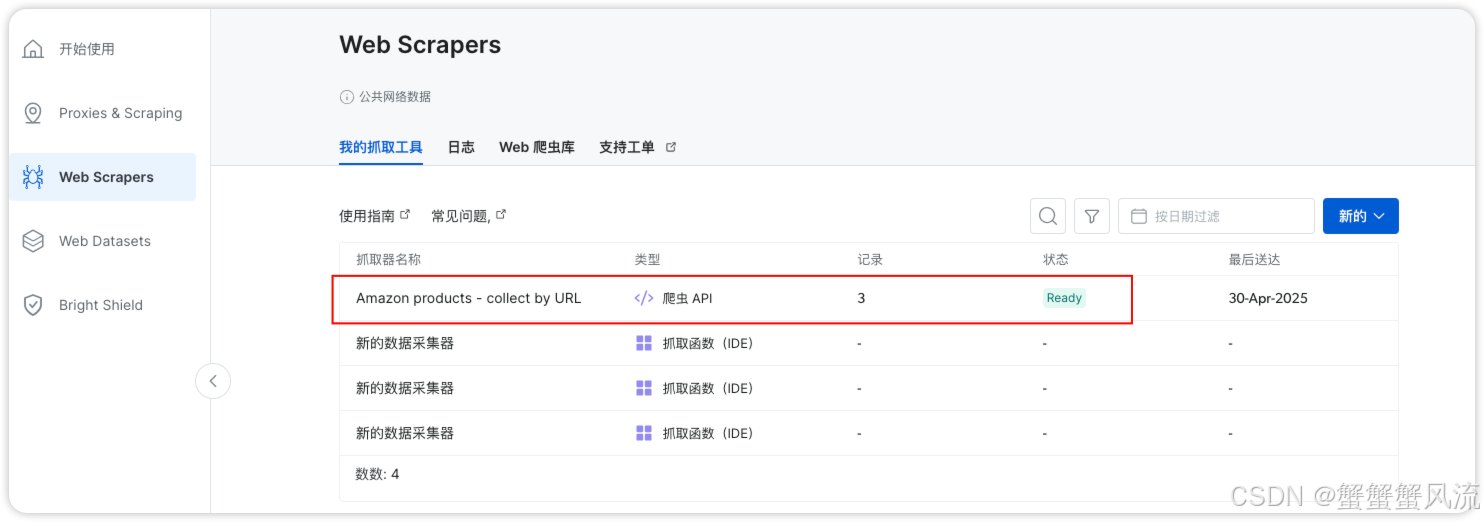
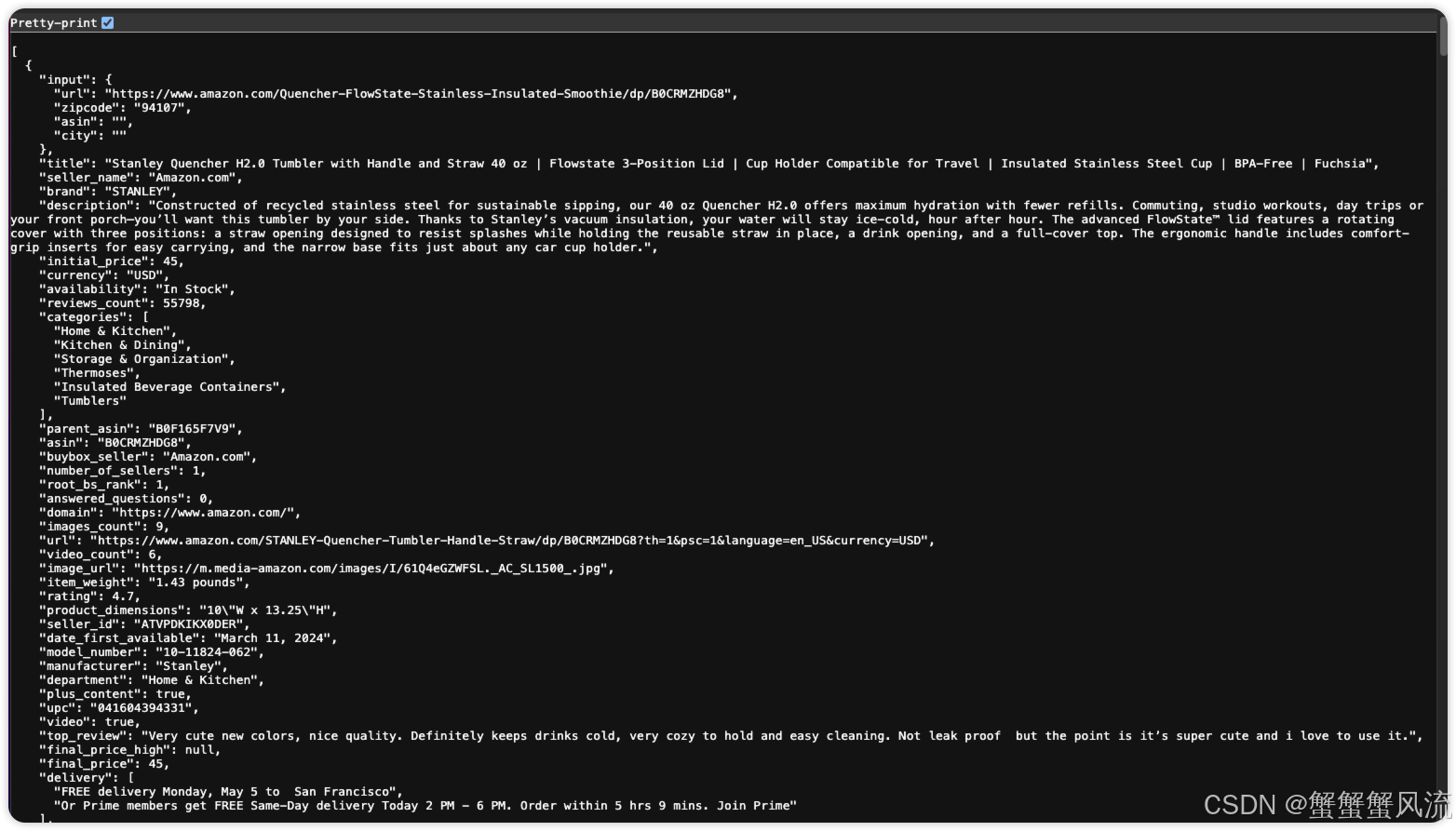
获取的数据如下:
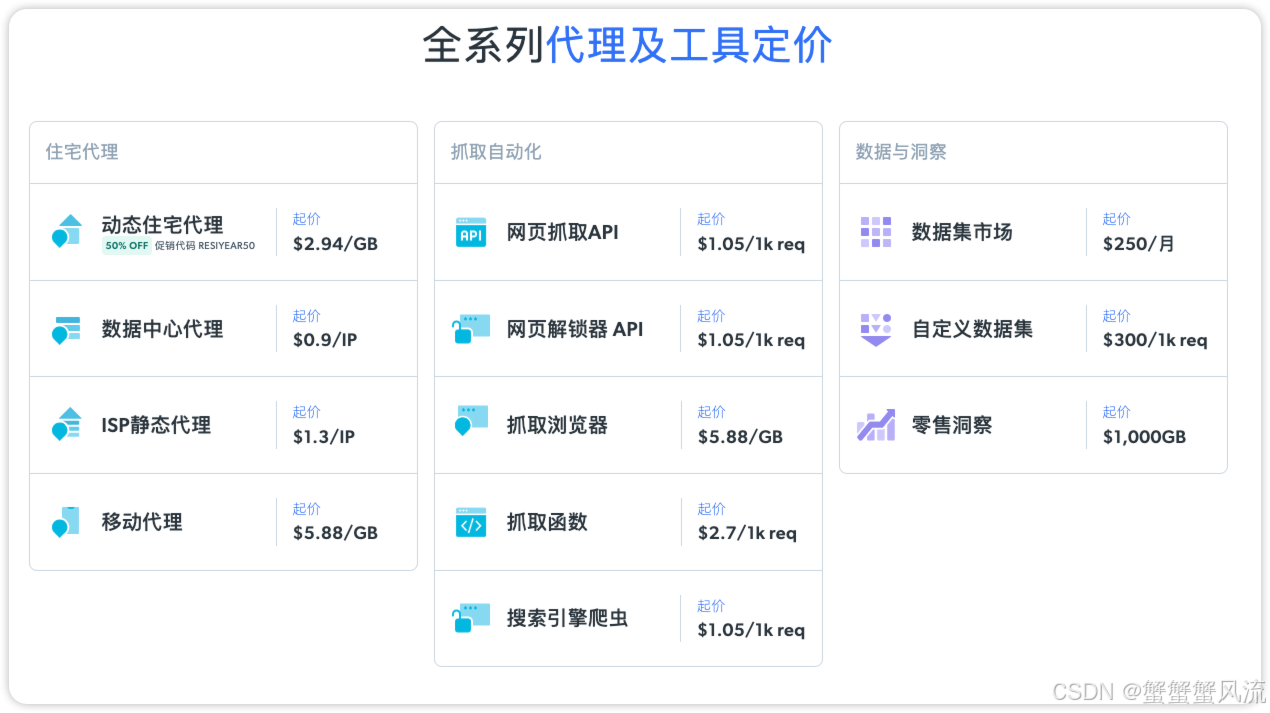
5 .弹性成本控制
按需选择数据量级套餐,避免了自建服务器集群的高昂运维成本。
二、实战案例:构建AI驱动的电商价格情报系统
1. 场景需求
为某跨境电商平台训练价格预测模型,需实时抓取亚马逊、沃尔玛等50+ 网站的动态定价数据。但现在面临如下技术挑战:
• 动态渲染页面: 目标网站使用 JavaScript 异步加载价格数据,传统requests 库无法获取完整 DOM。
• IP封禁风险: 高频请求导致IP日均封禁率达15%。
• 数据清洗复杂度高: 价格信息嵌套在多层<div>标签中,且存在货币符号/千位分隔符干扰。
2. 解决方案
- 动态页面抓取(Python + Scraping Browser)
通过Scraping Browser调用Headless Chrome,直接执行 JavaScript,完整加载动态内容。
from brightdata import ScrapingBrowser, Selector
# 初始化浏览器实例(自动轮换IP)
browser = ScrapingBrowser(
browser_type="CHROME",
proxy_config="ROTATING_PROXY", # 内置全球代理池
headless=True
)
# 处理JavaScript渲染
url = "https://www.amazon.com/dp/B09QZ8R5VH"
page = browser.get(url)
# 使用CSS选择器定位价格元素(动态生成内容)
price_selector = Selector(
type="css",
value="#corePriceDisplay_desktop_feature_div .a-price-whole"
)
price = page.query(price_selector).text()
# 处理货币符号(数据清洗)
import re
clean_price = re.sub(r'[^\d.]', '', price)
print(f"抓取价格: ${float(clean_price):.2f}")
- 反爬对抗策略:
• 智能请求间隔: 基于指数退避算法动态调整请求频率
from time import sleep
import random
def smart_delay(last_response_time):
base_delay = max(1, 2 ** (-(last_response_time - 2000)/1000))
jitter = random.uniform(0, 0.5)
sleep(base_delay * 1000 + jitter)
- 验证码自动处理: 集成2Captcha服务
from brightdata.captcha_solver import solve_captcha
def handle_captcha(page):
captcha_img = page.query("img[alt='captcha']").get_attribute("src")
solution = solve_captcha(api_key="YOUR_2CAPTCHA_KEY", image=captcha_img)
page.type("#captcha-input", solution)
3. 数据管道集成(AWS SageMaker)
import boto3
import pandas as pd
from sklearn.model_selection import train_test_split
# 从S3加载历史数据
s3 = boto3.client('s3')
df = pd.read_csv('s3://price-data-bucket/2025Q1.csv')
# 数据预处理(特征工程)
df['price_change'] = df['price'].pct_change(periods=24)
df = df.dropna()
# 模型训练
X_train, X_test, y_train, y_test = train_test_split(
df[['price', 'volume', 'competitor_count']],
df['sales_rank'],
test_size=0.2
)
model = xgb.XGBRegressor().fit(X_train, y_train)
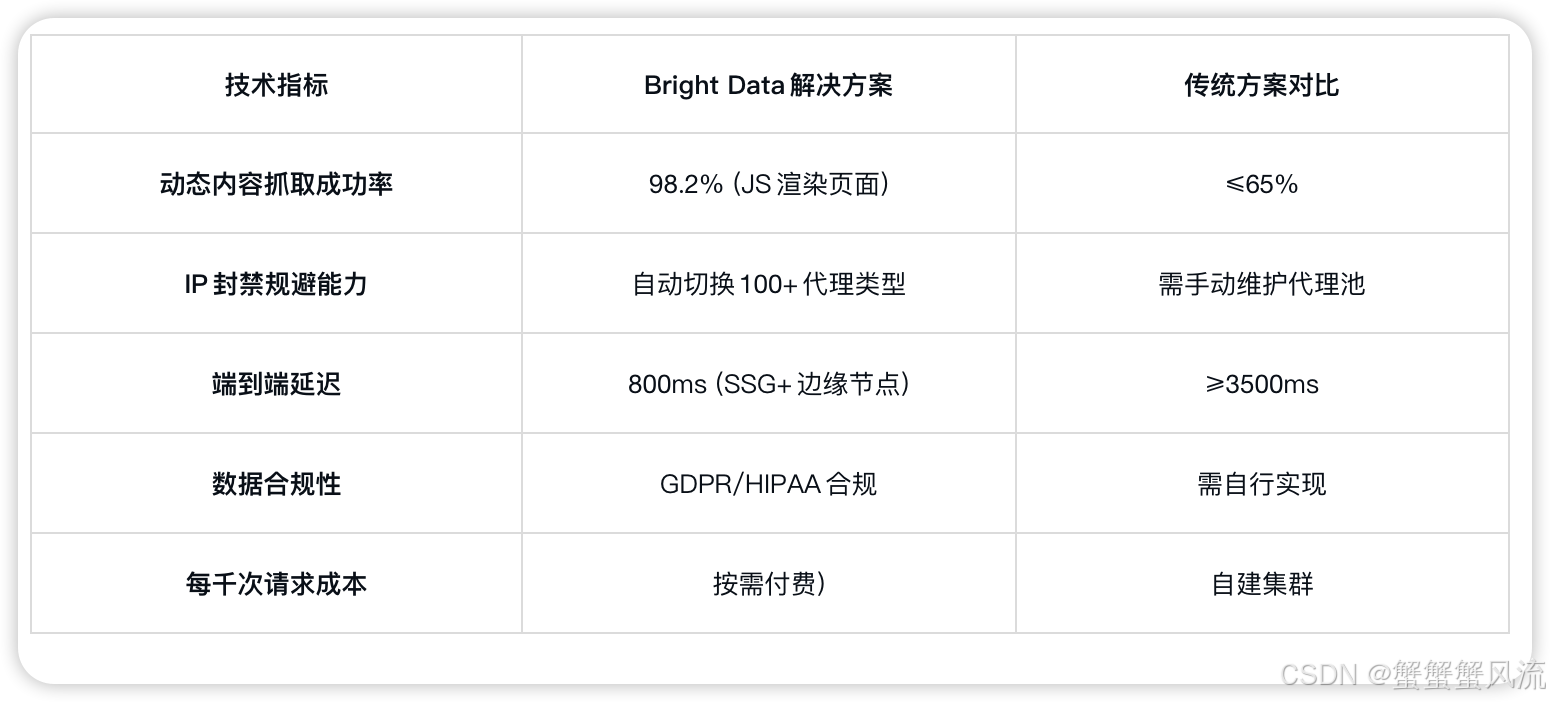
三、与传统方案对比
四、开启AI数据引擎
无论你是构建AI聊天机器人、训练大模型,还是优化自动化决策系统,Bright Data的AI就绪型数据解决方案都能帮助你:
✅ 突破反爬壁垒:应对全球85%的主流反爬机制
✅ 实时数据交付:支持Kafka/MQTT等协议直连AI平台
✅ 合规安全:GDPR/CCPA合规数据采集,规避法律风险
👉 点击试用链接,体验AI与数据采集的协同之力!
结语
在AI模型迭代速度以周计算的今天,数据已成为核心竞争力。Bright Data不仅解决了“数据从哪来”的难题,更通过无缝对接AI训练流程,让数据价值真正转化为商业洞察。其提供的解决方案不仅提升了数据获取的效率与质量,更是使得在 AI 时代背景下,让探索数据的价值有了无限可能!


















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











