







文章目录
项目需求
根据电商日志文件,分析:
- 统计页面浏览量(每行记录就是一次浏览)
- 统计各个省份的浏览量 (需要解析IP)
- 日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
整体架构流程
etl.java ------- 用于处理日志数据,提取并汇总关键信息,如IP地址、国家、省份、城市和时间。这是一个专门为日志分析设计的ETL(提取、转换、加载)过程的一部分。
数据集
数据集
链接:https://pan.baidu.com/s/1AtFZqf7pfQk_Tlh-HiFX4w?pwd=r5r8
提取码:r5r8

- 日志字段说明:
第二个字段:url
第十四个字段:IP
第十八个字段:time - 字段解析
IP—>国家、省份、城市
url—>页面ID
实验步骤
- 运行代码


- 查看结果
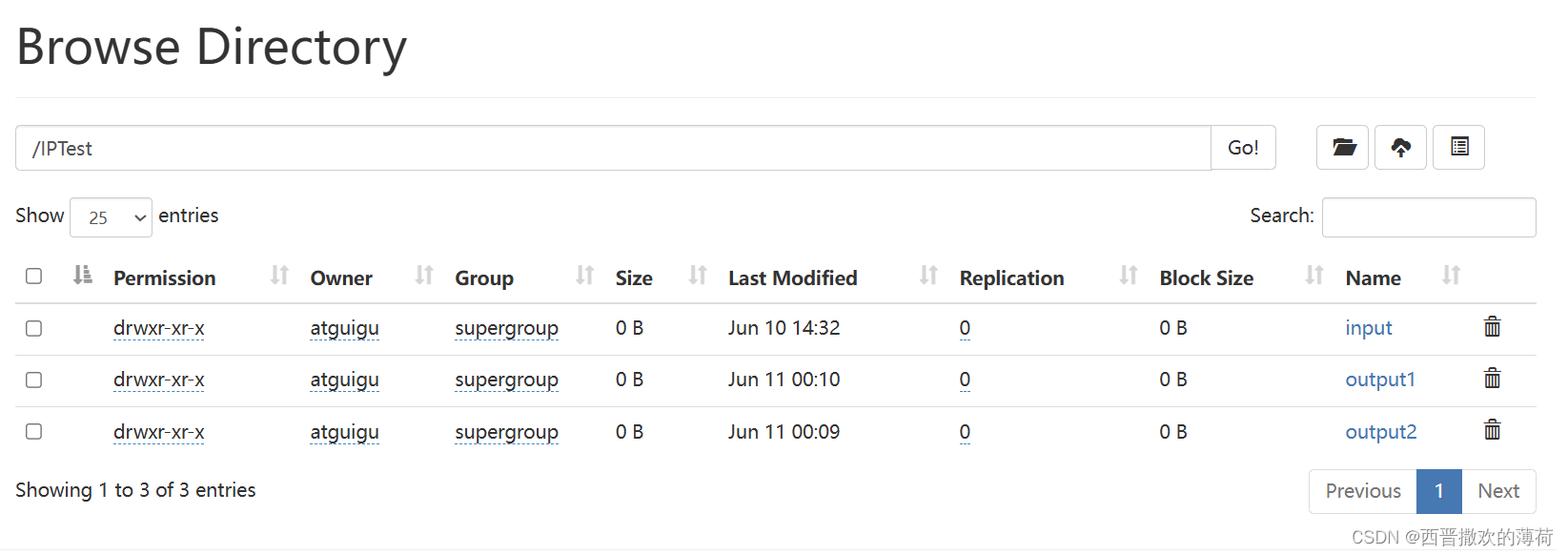
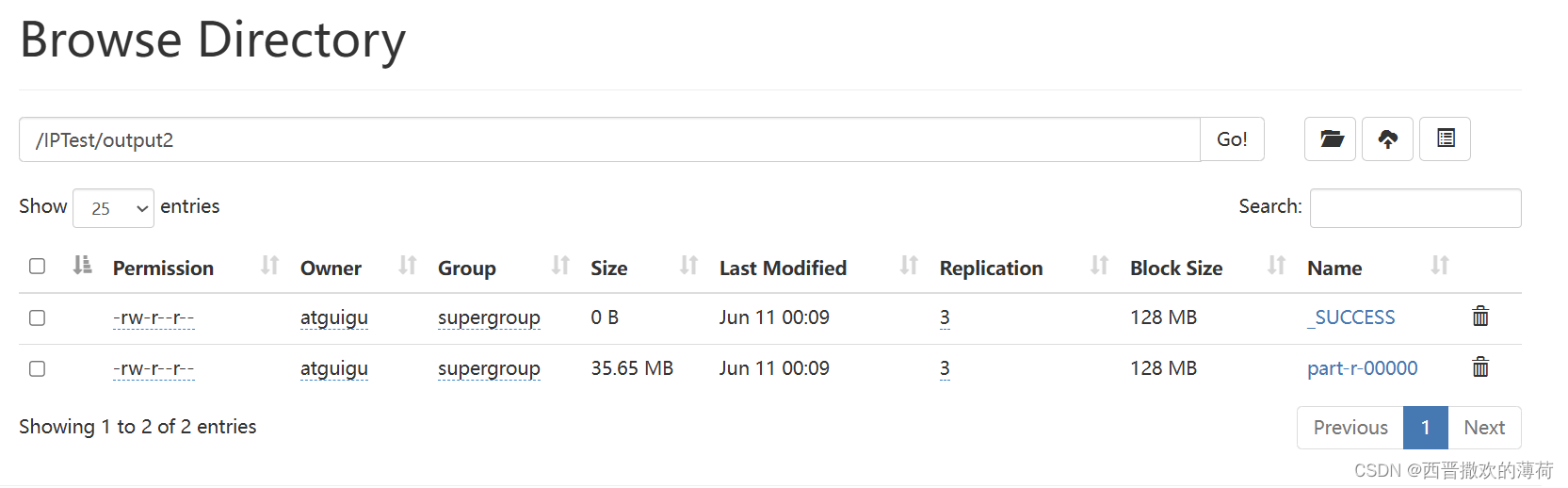

代码
etl.java
package com.etl; import com.IPutils.ProvinceStatApp; import com.IPutils.GetPageId; import com.IPutils.LogParser; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException; import java.net.URI; import java.util.Map; /** * etl提取关键信息 */ public class etl { public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); FileSystem hdfs = FileSystem.get(new URI("hdfs://hadoop102:8020"),new Configuration()); Path outputPath = new Path("hdfs://hadoop102:8020/IPTest/output2"); if (hdfs.exists(outputPath)) { hdfs.delete(outputPath, true); } Job job = Job.getInstance(configuration); job.setJarByClass(ProvinceStatApp.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); TextInputFormat.setInputPaths(job, new Path("hdfs://hadoop102:8020/trackinfo/input/trackinfo.txt")); TextOutputFormat.setOutputPath(job, new Path("hdfs://hadoop102:8020/IPTest/output2")); job.waitForCompletion(true); } static class MyMapper extends Mapper<LongWritable, Text, Text, Text> private LongWritable ONE = new LongWritable(1); private LogParser logParser; @Override protected void setup(Context context) throws IOException, InterruptedException { logParser = new LogParser(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String log = value.toString(); GetPageId getPageId = new GetPageId(); Map<String, String> info = logParser.parse(log); String ip = info.get("ip"); String url = info.get("url"); String pageId = GetPageId.getPageId(url); String country = info.get("country"); String province = info.get("province"); String city = info.get("city"); String time = info.get("time"); String out = "," + pageId + "," + ip + "," + country + "," + province + "," + city + "," + time; context.write(new Text(url) , new Text(out)); } } static class MyReduce extends Reducer<Text, Text, Text, Text> { @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text value : values) { context.write(key,value); } } } }
代码细节
etl.java详细解释
package com.etl; import com.IPutils.ProvinceStatApp; import com.IPutils.GetPageId; import com.IPutils.LogParser; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException; import java.net.URI; import java.util.Map; /** * etl提取关键信息 */ public class etl { public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); FileSystem hdfs = FileSystem.get(new URI("hdfs://hadoop102:8020"),new Configuration()); Path outputPath = new Path("hdfs://hadoop102:8020/IPTest/output2"); if (hdfs.exists(outputPath)) { hdfs.delete(outputPath, true); } Job job = Job.getInstance(configuration); job.setJarByClass(ProvinceStatApp.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); TextInputFormat.setInputPaths(job, new Path("hdfs://hadoop102:8020/trackinfo/input/trackinfo.txt")); TextOutputFormat.setOutputPath(job, new Path("hdfs://hadoop102:8020/IPTest/output2")); job.waitForCompletion(true); } static class MyMapper extends Mapper<LongWritable, Text, Text, Text> private LongWritable ONE = new LongWritable(1); private LogParser logParser; @Override protected void setup(Context context) throws IOException, InterruptedException { logParser = new LogParser(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String log = value.toString(); GetPageId getPageId = new GetPageId(); Map<String, String> info = logParser.parse(log); String ip = info.get("ip"); String url = info.get("url"); String pageId = GetPageId.getPageId(url); String country = info.get("country"); String province = info.get("province"); String city = info.get("city"); String time = info.get("time"); String out = "," + pageId + "," + ip + "," + country + "," + province + "," + city + "," + time; context.write(new Text(url) , new Text(out)); } } static class MyReduce extends Reducer<Text, Text, Text, Text> { @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text value : values) { context.write(key,value); } } } }用于处理日志数据,提取并汇总关键信息,如IP地址、国家、省份、城市和时间。这似乎是一个专门为日志分析设计的ETL(提取、转换、加载)过程的一部分。
以下是代码的详细解释:
- 主方法:这是程序的入口点。它设置Hadoop作业配置,指定输入和输出路径,并定义
Mapper和Reducer类。MyMapper类:这是作业的Mapper类。它扩展了Hadoop提供的Mapper类。map方法处理每个日志条目,使用LogParser类提取相关信息,并发出一个键值对,其中键是URL,值是页面ID、IP、国家、省份、城市和时间的连接。MyReduce类:这是作业的Reducer类。它扩展了Hadoop提供的Reducer类。reduce方法接收给定键(URL)的所有值,并简单地按原样发出它们,这表明意图是对每个URL的日志条目进行汇总。LogParser类:这是一个实用程序类(代码中未显示),用于解析日志条目并提取信息。GetPageId类:另一个实用程序类(代码中未显示),似乎从URL派生页面ID。作业配置:作业配置为从指定输入路径读取并写入输出路径。输入预期为文本格式,输出也将是文本格式。输入和输出:输入来自HDFS(Hadoop分布式文件系统)路径,输出也写入另一个HDFS路径。如果输出路径已存在,则在作业开始前将其删除。依赖类:代码依赖于外部类(ProvinceStatApp、LogParser、GetPageId),这些类在提供的代码中未定义。这些类可能负责解析日志并提取特定信息。
代码已上传至Gitee
https://gitee.com/lijiarui-1/test/tree/master/Test_project2

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









