







文章目录
Spark SQL:大数据处理的新境界
在大数据时代,高效处理和分析海量数据的能力变得至关重要。Spark SQL,作为Apache Spark生态系统中的一部分,为我们提供了一种强大且灵活的方式来处理结构化数据。在这篇博客中,我们将深入探讨Spark SQL的特点、基本概念,并通过实际案例来展示其使用方法。
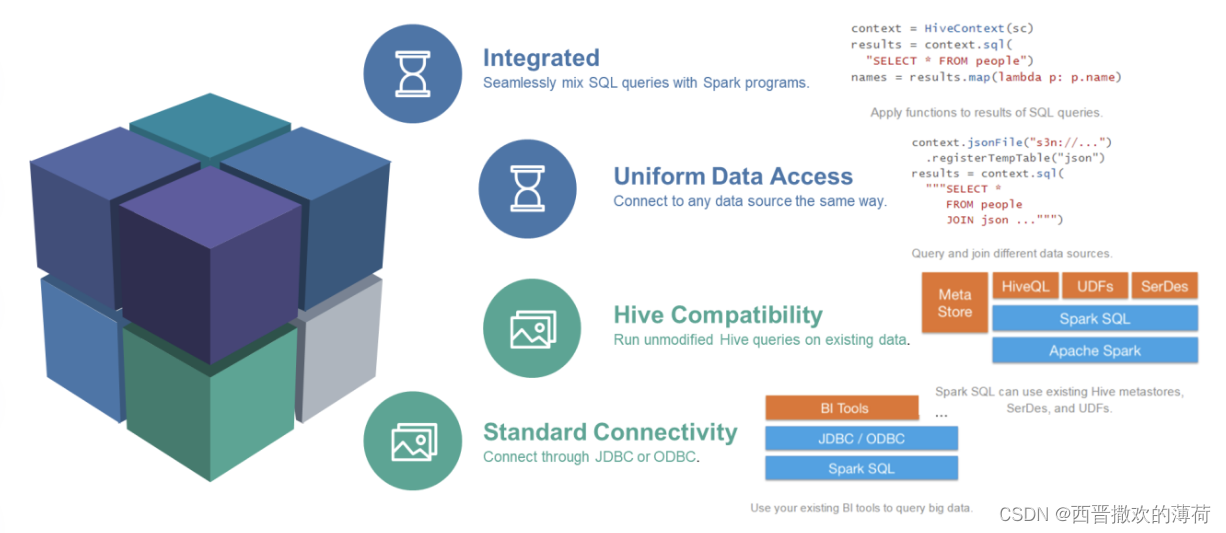
什么是Spark SQL?
Spark SQL是一个用于处理结构化数据的Spark组件。它允许我们使用SQL或熟悉的API在Spark程序中查询结构化数据。与传统的MapReduce不同,Spark SQL底层使用的是Spark RDD,这使得它在处理大数据时更加高效。
主要特点
- SQL查询与Spark应用程序的无缝结合:Spark SQL允许在Spark程序中使用SQL查询结构化数据,极大地简化了数据处理过程。
- 连接多种数据源:它提供了访问各种数据源的通用方法,包括Hive、Avro、Parquet、ORC、JSON、JDBC等。
- 兼容Hive:支持HiveQL语法以及Hive SerDes和UDF,允许访问现有的Hive仓库。
DataFrame和DataSet
在Spark SQL中,DataFrame和DataSet是两个核心概念。
- DataFrame:是Spark SQL中的一个编程抽象,类似于关系型数据库中的表。它是一个分布式数据集合,其中的数据都被组织到有名字的列中。
- DataSet:是Spark 1.6中添加的一个新的API,提供了强类型支持。相比于RDD,DataSet在每行数据上加了类型约束。
Spark SQL的基本使用
Spark SQL的使用非常直观。首先,我们可以通过SparkSession来加载数据,然后将其转换为DataFrame或Dataset。之后,就可以使用SQL语句来操作这些数据。
使用案例
假设我们有一个名为person.txt的文件,包含ID、姓名和年龄的数据。我们的目标是使用Spark SQL按照年龄降序排列这些数据。
- 加载数据为Dataset:
使用spark.read.textFile()方法加载文件,并将每一行作为Dataset的一个元素。 - 给Dataset添加元数据信息:
定义一个样例类Person来存放数据描述信息,然后使用map()算子将每个元素拆分并存入Person类中。 - 将Dataset转为DataFrame:
调用toDF()方法,将存有元数据的Dataset转为DataFrame。 - 执行SQL查询:
在DataFrame上创建一个临时视图,并使用spark.sql()执行SQL查询。
通过这些步骤,我们能够轻松地实现对大数据集的复杂查询和分析。
Spark SQL函数
Spark SQL内置了大量的函数,包括数学、字符串、日期等。这些函数可以在编程方式或SQL语句中使用。
自定义函数
当内置函数无法满足需求时,我们可以编写自定义函数(UDF)。例如,为了保护用户隐私,我们可以编写一个UDF来隐藏手机号的中间4位数字。
窗口函数
窗口函数是Spark SQL中一个强大的特性,它允许我们在不减少原表行数的情况下,对数据进行分组和排序。这对于实现如分组求TopN等复杂查询非常有用。
结论
Spark SQL以其高效的处理能力、灵活的API和强大的函数库,成为了大数据处理领域的一颗璀璨明星。无论是数据科学家、数据工程师还是分析师,都可以通过Spark SQL来轻松地处理和分析大数据集。随着技术的不断进步,Spark SQL将继续在大数据处理领域发挥重要作用。
















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









