







文章目录
项目需求
根据电商日志文件,分析:
- 统计页面浏览量(每行记录就是一次浏览)
- 统计各个省份的浏览量 (需要解析IP)
- 日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
整体架构流程

GetPageId.java ------- 这个类包含一个静态方法getPageId,其目的是从给定的URL中提取页面ID。
IPParser.java ------- 用于解析IP地址并获取其对应的国家、省份和城市信息。
IPSeeker.java ------- 用于解析IP地址并获取其对应的国家和地区信息。
LogParser.java ------- 它负责解析日志条目并提取诸如IP地址、URL、会话ID、时间戳和基于IP地址的地理位置(国家、省份、城市)等信息。该类使用Apache Commons Lang库中的StringUtils类进行字符串操作,并使用SLF4J进行日志记录。
ProviceStatApp.java
- MyMapper类 —— 用于处理包含IP地址的日志数据,并将这些IP地址的地区信息进行统计。
- MyReducer类 —— 用于处理由MyMapper类生成的数据,并进行计数操作,例如统计每个地区出现的次数。
- main方法 —— 它用于启动一个Hadoop MapReduce作业。这个作业的目的是处理HDFS上的日志文件,统计每个省份的记录数量。
数据集
数据集
链接:https://pan.baidu.com/s/1AtFZqf7pfQk_Tlh-HiFX4w?pwd=r5r8
提取码:r5r8

- 日志字段说明:
第二个字段:url
第十四个字段:IP
第十八个字段:time - 字段解析
IP—>国家、省份、城市
url—>页面ID
实验步骤
- 先在虚拟机上创建一个文件夹存放输入数据集文件
创建一个输入数据的文件夹
mkdir input
- 用xtfp将数据集传到虚拟机上



3. 启动Hadoop集群
启动HDFS

启动yarn
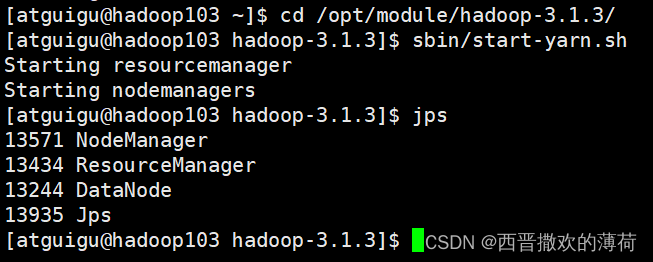
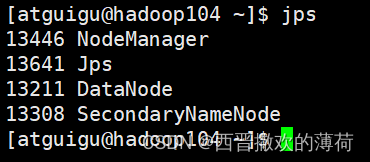
- 将数据传到HDFS上
在HDFS上创建存放的文件夹
hdfs dfs -mkdir -p /IPTest/input


hdfs dfs -put input.txt /trackinfo/input

- 运行代码


- 查看结果
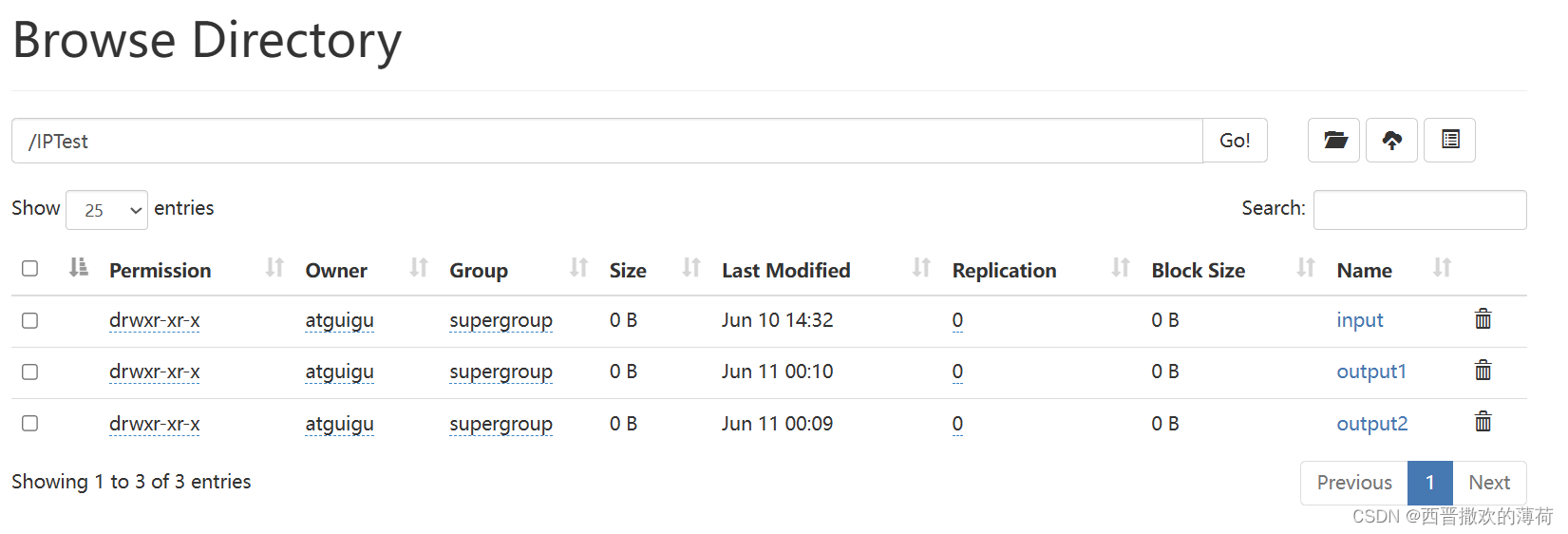
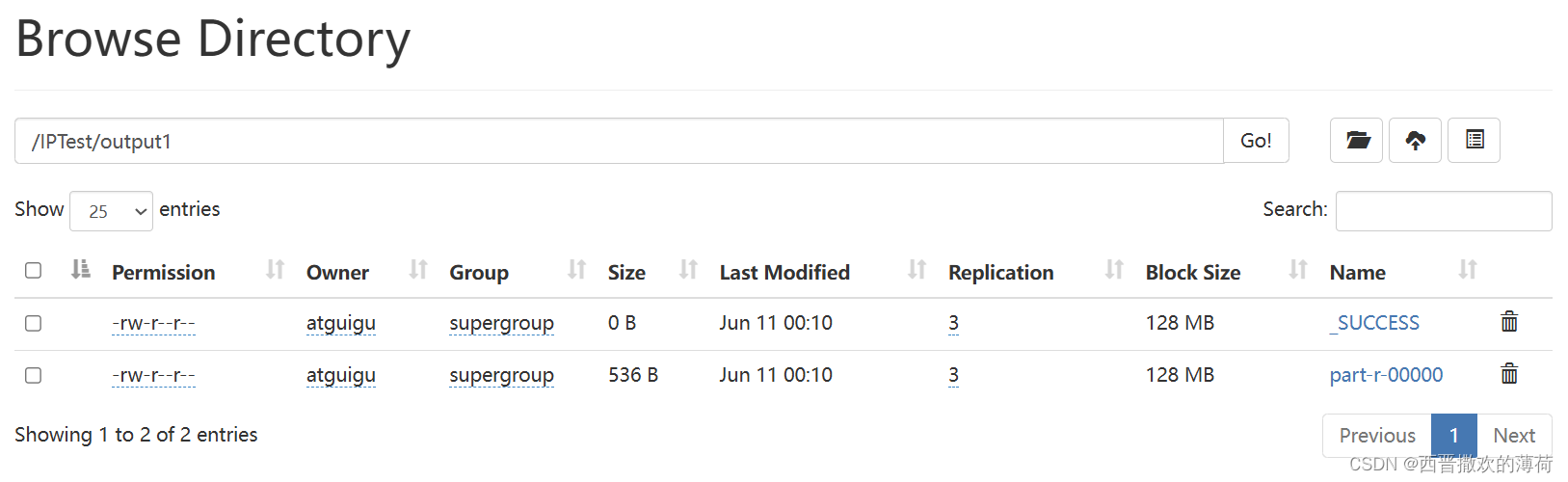

代码
GetPageId.java
package com.IPutils; import org.apache.commons.lang3.StringUtils; import java.util.regex.Matcher; import java.util.regex.Pattern; public class GetPageId { public static String getPageId(String url) { String pageId = ""; if (StringUtils.isBlank(url)) { return pageId; } Pattern pat = Pattern.compile("topicId=[0-9]+"); Matcher matcher = pat.matcher(url); if (matcher.find()) { pageId = matcher.group().split("topicId=")[1]; } return pageId; } }
IPParser.java
package com.IPutils; public class IPParser extends IPSeeker { // 地址 仅仅只是在ecplise环境中使用,部署在服务器上,需要先将qqwry.dat放在集群的各个节点某个有读取权限目录, // 然后在这里指定全路径 //private static final String ipFilePath = "ip/qqwry.dat"; // 部署在服务器上 private static final String ipFilePath = "/opt/module/hadoop-3.1.3/input/qqwry.dat"; private static IPParser obj = new IPParser(ipFilePath); protected IPParser(String ipFilePath) { super(ipFilePath); } public static IPParser getInstance() { return obj; } public RegionInfo analyseIp(String ip) { if (ip == null || "".equals(ip.trim())) { return null; } RegionInfo info = new RegionInfo(); try { String country = super.getCountry(ip); if ("局域网".equals(country) || country == null || country.isEmpty() || country.trim().startsWith("CZ88")) { // 设置默认值 info.setCountry("中国"); info.setProvince("上海市"); } else { int length = country.length(); int index = country.indexOf('省'); if (index > 0) { // 表示是国内的某个省 info.setCountry("中国"); info.setProvince(country.substring(0, Math.min(index + 1, length))); int index2 = country.indexOf('市', index); if (index2 > 0) { // 设置市 info.setCity(country.substring(index + 1, Math.min(index2 + 1, length))); } } else { String flag = country.substring(0, 2); switch (flag) { case "内蒙": info.setCountry("中国"); info.setProvince("内蒙古自治区"); country = country.substring(3); if (country != null && !country.isEmpty()) { index = country.indexOf('市'); if (index > 0) { // 设置市 info.setCity(country.substring(0, Math.min(index + 1, length))); } // TODO:针对其他旗或者盟没有进行处理 } break; case "广西": case "西藏": case "宁夏": case "新疆": info.setCountry("中国"); info.setProvince(flag); country = country.substring(2); if (country != null && !country.isEmpty()) { index = country.indexOf('市'); if (index > 0) { // 设置市 info.setCity(country.substring(0, Math.min(index + 1, length))); } } break; case "上海": case "北京": case "重庆": case "天津": info.setCountry("中国"); info.setProvince(flag + "市"); country = country.substring(3); if (country != null && !country.isEmpty()) { index = country.indexOf('区'); if (index > 0) { // 设置市 char ch = country.charAt(index - 1); if (ch != '小' || ch != '校') { info.setCity(country.substring(0, Math.min(index + 1, length))); } } if ("unknown".equals(info.getCity())) { // 现在city还没有设置,考虑县 index = country.indexOf('县'); if (index > 0) { // 设置市 info.setCity(country.substring(0, Math.min(index + 1, length))); } } } break; case "香港": case "澳门": info.setCountry("中国"); info.setProvince(flag + "特别行政区"); break; default: info.setCountry(country); // 针对其他国外的ip } } } } catch (Exception e) { // nothing } return info; } public static class RegionInfo { private String country ; private String province ; private String city ; public String getCountry() { return country; } public void setCountry(String country) { this.country = country; } public String getProvince() { return province; } public void setProvince(String province) { this.province = province; } public String getCity() { return city; } public void setCity(String city) { this.city = city; } @Override public String toString() { return "RegionInfo [country=" + country + ", province=" + province + ", city=" + city + "]"; } } }
IPSeeker.java
package com.IPutils; import java.io.FileNotFoundException; import java.io.IOException; import java.io.RandomAccessFile; import java.io.UnsupportedEncodingException; import java.nio.ByteOrder; import java.nio.MappedByteBuffer; import java.nio.channels.FileChannel; import java.util.ArrayList; import java.util.Hashtable; import java.util.List; public class IPSeeker { public static final String ERROR_RESULT = "错误的IP数据库文件"; // 一些固定常量,比如记录长度等等 private static final int IP_RECORD_LENGTH = 7; private static final byte AREA_FOLLOWED = 0x01; private static final byte NO_AREA = 0x2; // 用来做为cache,查询一个ip时首先查看cache,以减少不必要的重复查找 private Hashtable ipCache; // 随机文件访问类 private RandomAccessFile ipFile; // 内存映射文件 private MappedByteBuffer mbb; // 单一模式实例 private static IPSeeker instance = null; // 起始地区的开始和结束的绝对偏移 private long ipBegin, ipEnd; // 为提高效率而采用的临时变量 private IPLocation loc; private byte[] buf; private byte[] b4; private byte[] b3; /** */ /** * 私有构造函数 */ protected IPSeeker(String ipFilePath) { ipCache = new Hashtable(); loc = new IPLocation(); buf = new byte[100]; b4 = new byte[4]; b3 = new byte[3]; try { ipFile = new RandomAccessFile(ipFilePath, "r"); } catch (FileNotFoundException e) { System.out.println("IP地址信息文件没有找到,IP显示功能将无法使用"); ipFile = null; } // 如果打开文件成功,读取文件头信息 if (ipFile != null) { try { ipBegin = readLong4(0); ipEnd = readLong4(4); if (ipBegin == -1 || ipEnd == -1) { ipFile.close(); ipFile = null; } } catch (IOException e) { System.out.println("IP地址信息文件格式有错误,IP显示功能将无法使用"); ipFile = null; } } } /** */ /** * @return 单一实例 */ public static IPSeeker getInstance(String ipFilePath) { if (instance == null) { instance = new IPSeeker(ipFilePath); } return instance; } /** */ /** * 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录 * * @param s * 地点子串 * @return 包含IPEntry类型的List */ public List getIPEntriesDebug(String s) { List ret = new ArrayList(); long endOffset = ipEnd + 4; for (long offset = ipBegin + 4; offset <= endOffset; offset += IP_RECORD_LENGTH) { // 读取结束IP偏移 long temp = readLong3(offset); // 如果temp不等于-1,读取IP的地点信息 if (temp != -1) { IPLocation loc = getIPLocation(temp); // 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续 if (loc.country.indexOf(s) != -1 || loc.area.indexOf(s) != -1) { IPEntry entry = new IPEntry(); entry.country = loc.country; entry.area = loc.area; // 得到起始IP readIP(offset - 4, b4); entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4); // 得到结束IP readIP(temp, b4); entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4); // 添加该记录 ret.add(entry); } } } return ret; } /** */ /** * 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录 * * @param s * 地点子串 * @return 包含IPEntry类型的List */ public List getIPEntries(String s) { List ret = new ArrayList(); try { // 映射IP信息文件到内存中 if (mbb == null) { FileChannel fc = ipFile.getChannel(); mbb = fc.map(FileChannel.MapMode.READ_ONLY, 0, ipFile.length()); mbb.order(ByteOrder.LITTLE_ENDIAN); } int endOffset = (int) ipEnd; for (int offset = (int) ipBegin + 4; offset <= endOffset; offset += IP_RECORD_LENGTH) { int temp = readInt3(offset); if (temp != -1) { IPLocation loc = getIPLocation(temp); // 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续 if (loc.country.indexOf(s) != -1 || loc.area.indexOf(s) != -1) { IPEntry entry = new IPEntry(); entry.country = loc.country; entry.area = loc.area; // 得到起始IP readIP(offset - 4, b4); entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4); // 得到结束IP readIP(temp, b4); entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4); // 添加该记录 ret.add(entry); } } } } catch (IOException e) { System.out.println(e.getMessage()); } return ret; } /** */ /** * 从内存映射文件的offset位置开始的3个字节读取一个int * * @param offset * @return */ private int readInt3(int offset) { mbb.position(offset); return mbb.getInt() & 0x00FFFFFF; } /** */ /** * 从内存映射文件的当前位置开始的3个字节读取一个int * * @return */ private int readInt3() { return mbb.getInt() & 0x00FFFFFF; } /** */ /** * 根据IP得到国家名 * * @param ip * ip的字节数组形式 * @return 国家名字符串 */ public String getCountry(byte[] ip) { // 检查ip地址文件是否正常 if (ipFile == null) return ERROR_RESULT; // 保存ip,转换ip字节数组为字符串形式 String ipStr = IPSeekerUtils.getIpStringFromBytes(ip); // 先检查cache中是否已经包含有这个ip的结果,没有再搜索文件 if (ipCache.containsKey(ipStr)) { IPLocation loc = (IPLocation) ipCache.get(ipStr); return loc.country; } else { IPLocation loc = getIPLocation(ip); ipCache.put(ipStr, loc.getCopy()); return loc.country; } } /** */ /** * 根据IP得到国家名 * * @param ip * IP的字符串形式 * @return 国家名字符串 */ public String getCountry(String ip) { return getCountry(IPSeekerUtils.getIpByteArrayFromString(ip)); } /** */ /** * 根据IP得到地区名 * * @param ip * ip的字节数组形式 * @return 地区名字符串 */ public String getArea(byte[] ip) { // 检查ip地址文件是否正常 if (ipFile == null) return ERROR_RESULT; // 保存ip,转换ip字节数组为字符串形式 String ipStr = IPSeekerUtils.getIpStringFromBytes(ip); // 先检查cache中是否已经包含有这个ip的结果,没有再搜索文件 if (ipCache.containsKey(ipStr)) { IPLocation loc = (IPLocation) ipCache.get(ipStr); return loc.area; } else { IPLocation loc = getIPLocation(ip); ipCache.put(ipStr, loc.getCopy()); return loc.area; } } /** * 根据IP得到地区名 * * @param ip * IP的字符串形式 * @return 地区名字符串 */ public String getArea(String ip) { return getArea(IPSeekerUtils.getIpByteArrayFromString(ip)); } /** */ /** * 根据ip搜索ip信息文件,得到IPLocation结构,所搜索的ip参数从类成员ip中得到 * * @param ip * 要查询的IP * @return IPLocation结构 */ public IPLocation getIPLocation(byte[] ip) { IPLocation info = null; long offset = locateIP(ip); if (offset != -1) info = getIPLocation(offset); if (info == null) { info = new IPLocation(); info.country = "未知国家"; info.area = "未知地区"; } return info; } /** * 从offset位置读取4个字节为一个long,因为java为big-endian格式,所以没办法 用了这么一个函数来做转换 * * @param offset * @return 读取的long值,返回-1表示读取文件失败 */ private long readLong4(long offset) { long ret = 0; try { ipFile.seek(offset); ret |= (ipFile.readByte() & 0xFF); ret |= ((ipFile.readByte() << 8) & 0xFF00); ret |= ((ipFile.readByte() << 16) & 0xFF0000); ret |= ((ipFile.readByte() << 24) & 0xFF000000); return ret; } catch (IOException e) { return -1; } } /** * 从offset位置读取3个字节为一个long,因为java为big-endian格式,所以没办法 用了这么一个函数来做转换 * * @param offset * @return 读取的long值,返回-1表示读取文件失败 */ private long readLong3(long offset) { long ret = 0; try { ipFile.seek(offset); ipFile.readFully(b3); ret |= (b3[0] & 0xFF); ret |= ((b3[1] << 8) & 0xFF00); ret |= ((b3[2] << 16) & 0xFF0000); return ret; } catch (IOException e) { return -1; } } /** * 从当前位置读取3个字节转换成long * * @return */ private long readLong3() { long ret = 0; try { ipFile.readFully(b3); ret |= (b3[0] & 0xFF); ret |= ((b3[1] << 8) & 0xFF00); ret |= ((b3[2] << 16) & 0xFF0000); return ret; } catch (IOException e) { return -1; } } /** * 从offset位置读取四个字节的ip地址放入ip数组中,读取后的ip为big-endian格式,但是 * 文件中是little-endian形式,将会进行转换 * * @param offset * @param ip */ private void readIP(long offset, byte[] ip) { try { ipFile.seek(offset); ipFile.readFully(ip); byte temp = ip[0]; ip[0] = ip[3]; ip[3] = temp; temp = ip[1]; ip[1] = ip[2]; ip[2] = temp; } catch (IOException e) { System.out.println(e.getMessage()); } } /** * 从offset位置读取四个字节的ip地址放入ip数组中,读取后的ip为big-endian格式,但是 * 文件中是little-endian形式,将会进行转换 * * @param offset * @param ip */ private void readIP(int offset, byte[] ip) { mbb.position(offset); mbb.get(ip); byte temp = ip[0]; ip[0] = ip[3]; ip[3] = temp; temp = ip[1]; ip[1] = ip[2]; ip[2] = temp; } /** * 把类成员ip和beginIp比较,注意这个beginIp是big-endian的 * * @param ip * 要查询的IP * @param beginIp * 和被查询IP相比较的IP * @return 相等返回0,ip大于beginIp则返回1,小于返回-1。 */ private int compareIP(byte[] ip, byte[] beginIp) { for (int i = 0; i < 4; i++) { int r = compareByte(ip[i], beginIp[i]); if (r != 0) return r; } return 0; } /** * 把两个byte当作无符号数进行比较 * * @param b1 * @param b2 * @return 若b1大于b2则返回1,相等返回0,小于返回-1 */ private int compareByte(byte b1, byte b2) { if ((b1 & 0xFF) > (b2 & 0xFF)) // 比较是否大于 return 1; else if ((b1 ^ b2) == 0)// 判断是否相等 return 0; else return -1; } /** * 这个方法将根据ip的内容,定位到包含这个ip国家地区的记录处,返回一个绝对偏移 方法使用二分法查找。 * * @param ip * 要查询的IP * @return 如果找到了,返回结束IP的偏移,如果没有找到,返回-1 */ private long locateIP(byte[] ip) { long m = 0; int r; // 比较第一个ip项 readIP(ipBegin, b4); r = compareIP(ip, b4); if (r == 0) return ipBegin; else if (r < 0) return -1; // 开始二分搜索 for (long i = ipBegin, j = ipEnd; i < j;) { m = getMiddleOffset(i, j); readIP(m, b4); r = compareIP(ip, b4); // log.debug(Utils.getIpStringFromBytes(b)); if (r > 0) i = m; else if (r < 0) { if (m == j) { j -= IP_RECORD_LENGTH; m = j; } else j = m; } else return readLong3(m + 4); } // 如果循环结束了,那么i和j必定是相等的,这个记录为最可能的记录,但是并非 // 肯定就是,还要检查一下,如果是,就返回结束地址区的绝对偏移 m = readLong3(m + 4); readIP(m, b4); r = compareIP(ip, b4); if (r <= 0) return m; else return -1; } /** * 得到begin偏移和end偏移中间位置记录的偏移 * * @param begin * @param end * @return */ private long getMiddleOffset(long begin, long end) { long records = (end - begin) / IP_RECORD_LENGTH; records >>= 1; if (records == 0) records = 1; return begin + records * IP_RECORD_LENGTH; } /** * 给定一个ip国家地区记录的偏移,返回一个IPLocation结构 * * @param offset * @return */ private IPLocation getIPLocation(long offset) { try { // 跳过4字节ip ipFile.seek(offset + 4); // 读取第一个字节判断是否标志字节 byte b = ipFile.readByte(); if (b == AREA_FOLLOWED) { // 读取国家偏移 long countryOffset = readLong3(); // 跳转至偏移处 ipFile.seek(countryOffset); // 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向 b = ipFile.readByte(); if (b == NO_AREA) { loc.country = readString(readLong3()); ipFile.seek(countryOffset + 4); } else loc.country = readString(countryOffset); // 读取地区标志 loc.area = readArea(ipFile.getFilePointer()); } else if (b == NO_AREA) { loc.country = readString(readLong3()); loc.area = readArea(offset + 8); } else { loc.country = readString(ipFile.getFilePointer() - 1); loc.area = readArea(ipFile.getFilePointer()); } return loc; } catch (IOException e) { return null; } } /** * @param offset * @return */ private IPLocation getIPLocation(int offset) { // 跳过4字节ip mbb.position(offset + 4); // 读取第一个字节判断是否标志字节 byte b = mbb.get(); if (b == AREA_FOLLOWED) { // 读取国家偏移 int countryOffset = readInt3(); // 跳转至偏移处 mbb.position(countryOffset); // 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向 b = mbb.get(); if (b == NO_AREA) { loc.country = readString(readInt3()); mbb.position(countryOffset + 4); } else loc.country = readString(countryOffset); // 读取地区标志 loc.area = readArea(mbb.position()); } else if (b == NO_AREA) { loc.country = readString(readInt3()); loc.area = readArea(offset + 8); } else { loc.country = readString(mbb.position() - 1); loc.area = readArea(mbb.position()); } return loc; } /** * 从offset偏移开始解析后面的字节,读出一个地区名 * * @param offset * @return 地区名字符串 * @throws IOException */ private String readArea(long offset) throws IOException { ipFile.seek(offset); byte b = ipFile.readByte(); if (b == 0x01 || b == 0x02) { long areaOffset = readLong3(offset + 1); if (areaOffset == 0) return "未知地区"; else return readString(areaOffset); } else return readString(offset); } /** * @param offset * @return */ private String readArea(int offset) { mbb.position(offset); byte b = mbb.get(); if (b == 0x01 || b == 0x02) { int areaOffset = readInt3(); if (areaOffset == 0) return "未知地区"; else return readString(areaOffset); } else return readString(offset); } /** * 从offset偏移处读取一个以0结束的字符串 * * @param offset * @return 读取的字符串,出错返回空字符串 */ private String readString(long offset) { try { ipFile.seek(offset); int i; for (i = 0, buf[i] = ipFile.readByte(); buf[i] != 0; buf[++i] = ipFile.readByte()) ; if (i != 0) return IPSeekerUtils.getString(buf, 0, i, "GBK"); } catch (IOException e) { System.out.println(e.getMessage()); } return ""; } /** * 从内存映射文件的offset位置得到一个0结尾字符串 * * @param offset * @return */ private String readString(int offset) { try { mbb.position(offset); int i; for (i = 0, buf[i] = mbb.get(); buf[i] != 0; buf[++i] = mbb.get()) ; if (i != 0) return IPSeekerUtils.getString(buf, 0, i, "GBK"); } catch (IllegalArgumentException e) { System.out.println(e.getMessage()); } return ""; } public String getAddress(String ip) { String country = getCountry(ip).equals(" CZ88.NET") ? "" : getCountry(ip); String area = getArea(ip).equals(" CZ88.NET") ? "" : getArea(ip); String address = country + " " + area; return address.trim(); } /** * * 用来封装ip相关信息,目前只有两个字段,ip所在的国家和地区 * * * @author swallow */ public class IPLocation { public String country; public String area; public IPLocation() { country = area = ""; } public IPLocation getCopy() { IPLocation ret = new IPLocation(); ret.country = country; ret.area = area; return ret; } } /** * 一条IP范围记录,不仅包括国家和区域,也包括起始IP和结束IP * * * * @author gerry liu */ public class IPEntry { public String beginIp; public String endIp; public String country; public String area; public IPEntry() { beginIp = endIp = country = area = ""; } public String toString() { return this.area + " " + this.country + "IP Χ:" + this.beginIp + "-" + this.endIp; } } /** * 操作工具类 * * @author gerryliu * */ public static class IPSeekerUtils { /** * 从ip的字符串形式得到字节数组形式 * * @param ip * 字符串形式的ip * @return 字节数组形式的ip */ public static byte[] getIpByteArrayFromString(String ip) { byte[] ret = new byte[4]; java.util.StringTokenizer st = new java.util.StringTokenizer(ip, "."); try { ret[0] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF); ret[1] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF); ret[2] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF); ret[3] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF); } catch (Exception e) { System.out.println(e.getMessage()); } return ret; } /** * 对原始字符串进行编码转换,如果失败,返回原始的字符串 * * @param s * 原始字符串 * @param srcEncoding * 源编码方式 * @param destEncoding * 目标编码方式 * @return 转换编码后的字符串,失败返回原始字符串 */ public static String getString(String s, String srcEncoding, String destEncoding) { try { return new String(s.getBytes(srcEncoding), destEncoding); } catch (UnsupportedEncodingException e) { return s; } } /** * 根据某种编码方式将字节数组转换成字符串 * * @param b * 字节数组 * @param encoding * 编码方式 * @return 如果encoding不支持,返回一个缺省编码的字符串 */ public static String getString(byte[] b, String encoding) { try { return new String(b, encoding); } catch (UnsupportedEncodingException e) { return new String(b); } } /** * 根据某种编码方式将字节数组转换成字符串 * * @param b * 字节数组 * @param offset * 要转换的起始位置 * @param len * 要转换的长度 * @param encoding * 编码方式 * @return 如果encoding不支持,返回一个缺省编码的字符串 */ public static String getString(byte[] b, int offset, int len, String encoding) { try { return new String(b, offset, len, encoding); } catch (UnsupportedEncodingException e) { return new String(b, offset, len); } } /** * @param ip * ip的字节数组形式 * @return 字符串形式的ip */ public static String getIpStringFromBytes(byte[] ip) { StringBuffer sb = new StringBuffer(); sb.append(ip[0] & 0xFF); sb.append('.'); sb.append(ip[1] & 0xFF); sb.append('.'); sb.append(ip[2] & 0xFF); sb.append('.'); sb.append(ip[3] & 0xFF); return sb.toString(); } } /** * 获取全部ip地址集合列表 * * @return */ public List<String> getAllIp() { List<String> list = new ArrayList<String>(); byte[] buf = new byte[4]; for (long i = ipBegin; i < ipEnd; i += IP_RECORD_LENGTH) { try { this.readIP(this.readLong3(i + 4), buf); // 读取ip,最终ip放到buf中 String ip = IPSeekerUtils.getIpStringFromBytes(buf); list.add(ip); } catch (Exception e) { // nothing } } return list; } }
LogParser.java
package com.IPutils; import org.apache.commons.lang3.StringUtils; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.HashMap; import java.util.Map; public class LogParser { private Logger logger = LoggerFactory.getLogger(LogParser.class); public Map<String, String> parse2(String log) { Map<String, String> logInfo = new HashMap<String,String>(); IPParser ipParse = IPParser.getInstance(); if(StringUtils.isNotBlank(log)) { String[] splits = log.split("\t"); String ip = splits[0]; String url = splits[1]; String sessionId = splits[2]; String time = splits[3]; String country = splits[4]; String province = splits[5]; String city = splits[6]; logInfo.put("ip",ip); logInfo.put("url",url); logInfo.put("sessionId",sessionId); logInfo.put("time",time); logInfo.put("country",country); logInfo.put("province",province); logInfo.put("city",city); } else{ logger.error("日志记录的格式不正确:" + log); } return logInfo; } public Map<String, String> parse(String log) { Map<String, String> logInfo = new HashMap<String,String>(); IPParser ipParse = IPParser.getInstance(); if(StringUtils.isNotBlank(log)) { String[] splits = log.split("\001"); String ip = splits[13]; String url = splits[1]; String sessionId = splits[10]; String time = splits[17]; logInfo.put("ip",ip); logInfo.put("url",url); logInfo.put("sessionId",sessionId); logInfo.put("time",time); IPParser.RegionInfo regionInfo = ipParse.analyseIp(ip); logInfo.put("country",regionInfo.getCountry()); logInfo.put("province",regionInfo.getProvince()); logInfo.put("city",regionInfo.getCity()); } else{ logger.error("日志记录的格式不正确:" + log); } return logInfo; } }
ProviceStatApp.java
package com.IPutils; >import org.apache.commons.lang3.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException; import java.net.URI; import java.util.Map; /** * 省份浏览量统计 */ public class ProvinceStatApp { public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); FileSystem hdfs = FileSystem.get(new URI("hdfs://hadoop102:8020"),new Configuration()); Path outputPath = new Path("hdfs://hadoop102:8020/IPTest/output1"); if (hdfs.exists(outputPath)) { hdfs.delete(outputPath, true); } Job job = Job.getInstance(configuration); job.setJarByClass(ProvinceStatApp.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); TextInputFormat.setInputPaths(job, new >Path("hdfs://hadoop102:8020/trackinfo/input/trackinfo.txt")); TextOutputFormat.setOutputPath(job, new Path("hdfs://hadoop102:8020/IPTest/output1")); job.waitForCompletion(true); } static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { private LongWritable ONE = new LongWritable(1); private LogParser logParser; @Override protected void setup(Context context) throws IOException, InterruptedException { logParser = new LogParser(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String log = value.toString(); Map<String, String> info = logParser.parse(log); String ip = info.get("ip"); if (StringUtils.isNotBlank(ip)) { IPParser.RegionInfo regionInfo = IPParser.getInstance().analyseIp(ip); if (regionInfo != null) { String provine = regionInfo.getProvince(); if (StringUtils.isNotBlank(provine)) { context.write(new Text(provine), ONE); } else { context.write(new Text("-"), ONE); } } else { context.write(new Text("-"), ONE); } } else { context.write(new Text("-"), ONE); } } } static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long count = 0; System.out.println(context); for (LongWritable value : values) { count++; } context.write(key, new LongWritable(count)); } } }
代码细节
GetPageId.java详细解释
package com.IPutils; import org.apache.commons.lang3.StringUtils; import java.util.regex.Matcher; import java.util.regex.Pattern; public class GetPageId { public static String getPageId(String url) { String pageId = ""; if (StringUtils.isBlank(url)) { return pageId; } Pattern pat = Pattern.compile("topicId=[0-9]+"); Matcher matcher = pat.matcher(url); if (matcher.find()) { pageId = matcher.group().split("topicId=")[1]; } return pageId; } }这个类包含一个静态方法
getPageId,其目的是从给定的URL中提取页面ID。
这里是代码的详细解释:
getPageId方法:这个方法接受一个字符串参数url,并返回一个字符串pageId。如果没有从URL中提取到页面ID,pageId将是一个空字符串。
- 首先,方法检查传入的url是否为空或只包含空白字符。如果是,则直接返回空字符串
pageId。- 然后,方法使用Pattern和Matcher类来搜索URL中的模式
"topicId=[0-9]+"。这个正则表达式匹配所有以"topicId="开头,后跟一个或多个数字的字符串。
如果找到了匹配项,matcher.find()方法将返回true,并且matcher.group()将返回第一个匹配的字符串。然后,代码使用split("topicId=")[1]来分割这个字符串并获取"topicId="后面的数字部分,这就是页面ID。- 最后,页面ID被返回。
IPParser.java详细解释
package com.IPutils; public class IPParser extends IPSeeker { // 地址 仅仅只是在ecplise环境中使用,部署在服务器上,需要先将qqwry.dat放在集群的各个节点某个有读取权限目录, // 然后在这里指定全路径 //private static final String ipFilePath = "ip/qqwry.dat"; // 部署在服务器上 private static final String ipFilePath = "/opt/module/hadoop-3.1.3/input/qqwry.dat"; private static IPParser obj = new IPParser(ipFilePath); protected IPParser(String ipFilePath) { super(ipFilePath); } public static IPParser getInstance() { return obj; } public RegionInfo analyseIp(String ip) { if (ip == null || "".equals(ip.trim())) { return null; } RegionInfo info = new RegionInfo(); try { String country = super.getCountry(ip); if ("局域网".equals(country) || country == null || country.isEmpty() || country.trim().startsWith("CZ88")) { // 设置默认值 info.setCountry("中国"); info.setProvince("上海市"); } else { int length = country.length(); int index = country.indexOf('省'); if (index > 0) { // 表示是国内的某个省 info.setCountry("中国"); info.setProvince(country.substring(0, Math.min(index + 1, length))); int index2 = country.indexOf('市', index); if (index2 > 0) { // 设置市 info.setCity(country.substring(index + 1, Math.min(index2 + 1, length))); } } else { String flag = country.substring(0, 2); switch (flag) { case "内蒙": info.setCountry("中国"); info.setProvince("内蒙古自治区"); country = country.substring(3); if (country != null && !country.isEmpty()) { index = country.indexOf('市'); if (index > 0) { // 设置市 info.setCity(country.substring(0, Math.min(index + 1, length))); } // TODO:针对其他旗或者盟没有进行处理 } break; case "广西": case "西藏": case "宁夏": case "新疆": info.setCountry("中国"); info.setProvince(flag); country = country.substring(2); if (country != null && !country.isEmpty()) { index = country.indexOf('市'); if (index > 0) { // 设置市 info.setCity(country.substring(0, Math.min(index + 1, length))); } } break; case "上海": case "北京": case "重庆": case "天津": info.setCountry("中国"); info.setProvince(flag + "市"); country = country.substring(3); if (country != null && !country.isEmpty()) { index = country.indexOf('区'); if (index > 0) { // 设置市 char ch = country.charAt(index - 1); if (ch != '小' || ch != '校') { info.setCity(country.substring(0, Math.min(index + 1, length))); } } if ("unknown".equals(info.getCity())) { // 现在city还没有设置,考虑县 index = country.indexOf('县'); if (index > 0) { // 设置市 info.setCity(country.substring(0, Math.min(index + 1, length))); } } } break; case "香港": case "澳门": info.setCountry("中国"); info.setProvince(flag + "特别行政区"); break; default: info.setCountry(country); // 针对其他国外的ip } } } } catch (Exception e) { // nothing } return info; } public static class RegionInfo { private String country ; private String province ; private String city ; public String getCountry() { return country; } public void setCountry(String country) { this.country = country; } public String getProvince() { return province; } public void setProvince(String province) { this.province = province; } public String getCity() { return city; } public void setCity(String city) { this.city = city; } @Override public String toString() { return "RegionInfo [country=" + country + ", province=" + province + ", city=" + city + "]"; } } }这个方法可以用来从包含特定格式的URL中提取页面ID
它扩展了一个名为IPSeeker的类,用于解析IP地址并获取其对应的国家、省份和城市信息。这个类是基于QQWry.dat数据库来查询IP地址信息的。这里是代码的详细解释:
IPParser类包含一个静态实例obj,它使用指定的ipFilePath(QQWry.dat数据库文件的位置)来初始化。这个文件路径在服务器上应该是可读的。
IPParser类有一个受保护的构造函数,它接受一个字符串参数ipFilePath并调用父类的构造函数。
getInstance方法是一个静态方法,用于获取IPParser类的唯一实例。
analyseIp方法接受一个字符串参数ip,并返回一个RegionInfo对象,该对象包含IP地址的国家、省份和城市信息。在
analyseIp方法中,首先检查传入的IP地址是否为空或只包含空白字符。如果是,则返回null。
然后,方法使用父类IPSeeker的方法getCountry来获取IP地址对应的国家信息。
根据获取到的国家信息,代码会进行一系列的逻辑判断,以确定省份和城市信息。例如,如果国家信息包含"省"字,则认为IP地址位于中国的一个省份,并提取省份和城市信息。
对于一些特殊情况,如内蒙古、广西、西藏、宁夏和新疆等自治区,以及香港和澳门特别行政区,代码会进行特殊处理。如果IP地址对应的国家不是中国,则直接将国家信息设置为获取到的国家信息。
RegionInfo类是一个内部静态类,用于存储IP地址的国家、省份和城市信息。它提供了相应的getter和setter方法,以及一个覆盖的toString方法,用于方便地打印信息。这个类可以用来解析IP地址,并获取其对应的国家、省份和城市信息。这对于需要根据IP地址定位用户地理位置的应用程序非常有用。
IPSeeker.java详细解释
package com.IPutils; import java.io.FileNotFoundException; import java.io.IOException; import java.io.RandomAccessFile; import java.io.UnsupportedEncodingException; import java.nio.ByteOrder; import java.nio.MappedByteBuffer; import java.nio.channels.FileChannel; import java.util.ArrayList; import java.util.Hashtable; import java.util.List; public class IPSeeker { public static final String ERROR_RESULT = "错误的IP数据库文件"; // 一些固定常量,比如记录长度等等 private static final int IP_RECORD_LENGTH = 7; private static final byte AREA_FOLLOWED = 0x01; private static final byte NO_AREA = 0x2; // 用来做为cache,查询一个ip时首先查看cache,以减少不必要的重复查找 private Hashtable ipCache; // 随机文件访问类 private RandomAccessFile ipFile; // 内存映射文件 private MappedByteBuffer mbb; // 单一模式实例 private static IPSeeker instance = null; // 起始地区的开始和结束的绝对偏移 private long ipBegin, ipEnd; // 为提高效率而采用的临时变量 private IPLocation loc; private byte[] buf; private byte[] b4; private byte[] b3; /** */ /** * 私有构造函数 */ protected IPSeeker(String ipFilePath) { ipCache = new Hashtable(); loc = new IPLocation(); buf = new byte[100]; b4 = new byte[4]; b3 = new byte[3]; try { ipFile = new RandomAccessFile(ipFilePath, "r"); } catch (FileNotFoundException e) { System.out.println("IP地址信息文件没有找到,IP显示功能将无法使用"); ipFile = null; } // 如果打开文件成功,读取文件头信息 if (ipFile != null) { try { ipBegin = readLong4(0); ipEnd = readLong4(4); if (ipBegin == -1 || ipEnd == -1) { ipFile.close(); ipFile = null; } } catch (IOException e) { System.out.println("IP地址信息文件格式有错误,IP显示功能将无法使用"); ipFile = null; } } } /** */ /** * @return 单一实例 */ public static IPSeeker getInstance(String ipFilePath) { if (instance == null) { instance = new IPSeeker(ipFilePath); } return instance; } /** */ /** * 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录 * * @param s * 地点子串 * @return 包含IPEntry类型的List */ public List getIPEntriesDebug(String s) { List ret = new ArrayList(); long endOffset = ipEnd + 4; for (long offset = ipBegin + 4; offset <= endOffset; offset += IP_RECORD_LENGTH) { // 读取结束IP偏移 long temp = readLong3(offset); // 如果temp不等于-1,读取IP的地点信息 if (temp != -1) { IPLocation loc = getIPLocation(temp); // 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续 if (loc.country.indexOf(s) != -1 || loc.area.indexOf(s) != -1) { IPEntry entry = new IPEntry(); entry.country = loc.country; entry.area = loc.area; // 得到起始IP readIP(offset - 4, b4); entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4); // 得到结束IP readIP(temp, b4); entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4); // 添加该记录 ret.add(entry); } } } return ret; } /** */ /** * 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录 * * @param s * 地点子串 * @return 包含IPEntry类型的List */ public List getIPEntries(String s) { List ret = new ArrayList(); try { // 映射IP信息文件到内存中 if (mbb == null) { FileChannel fc = ipFile.getChannel(); mbb = fc.map(FileChannel.MapMode.READ_ONLY, 0, ipFile.length()); mbb.order(ByteOrder.LITTLE_ENDIAN); } int endOffset = (int) ipEnd; for (int offset = (int) ipBegin + 4; offset <= endOffset; offset += IP_RECORD_LENGTH) { int temp = readInt3(offset); if (temp != -1) { IPLocation loc = getIPLocation(temp); // 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续 if (loc.country.indexOf(s) != -1 || loc.area.indexOf(s) != -1) { IPEntry entry = new IPEntry(); entry.country = loc.country; entry.area = loc.area; // 得到起始IP readIP(offset - 4, b4); entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4); // 得到结束IP readIP(temp, b4); entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4); // 添加该记录 ret.add(entry); } } } } catch (IOException e) { System.out.println(e.getMessage()); } return ret; } /** */ /** * 从内存映射文件的offset位置开始的3个字节读取一个int * * @param offset * @return */ private int readInt3(int offset) { mbb.position(offset); return mbb.getInt() & 0x00FFFFFF; } /** */ /** * 从内存映射文件的当前位置开始的3个字节读取一个int * * @return */ private int readInt3() { return mbb.getInt() & 0x00FFFFFF; } /** */ /** * 根据IP得到国家名 * * @param ip * ip的字节数组形式 * @return 国家名字符串 */ public String getCountry(byte[] ip) { // 检查ip地址文件是否正常 if (ipFile == null) return ERROR_RESULT; // 保存ip,转换ip字节数组为字符串形式 String ipStr = IPSeekerUtils.getIpStringFromBytes(ip); // 先检查cache中是否已经包含有这个ip的结果,没有再搜索文件 if (ipCache.containsKey(ipStr)) { IPLocation loc = (IPLocation) ipCache.get(ipStr); return loc.country; } else { IPLocation loc = getIPLocation(ip); ipCache.put(ipStr, loc.getCopy()); return loc.country; } } /** */ /** * 根据IP得到国家名 * * @param ip * IP的字符串形式 * @return 国家名字符串 */ public String getCountry(String ip) { return getCountry(IPSeekerUtils.getIpByteArrayFromString(ip)); } /** */ /** * 根据IP得到地区名 * * @param ip * ip的字节数组形式 * @return 地区名字符串 */ public String getArea(byte[] ip) { // 检查ip地址文件是否正常 if (ipFile == null) return ERROR_RESULT; // 保存ip,转换ip字节数组为字符串形式 String ipStr = IPSeekerUtils.getIpStringFromBytes(ip); // 先检查cache中是否已经包含有这个ip的结果,没有再搜索文件 if (ipCache.containsKey(ipStr)) { IPLocation loc = (IPLocation) ipCache.get(ipStr); return loc.area; } else { IPLocation loc = getIPLocation(ip); ipCache.put(ipStr, loc.getCopy()); return loc.area; } } /** * 根据IP得到地区名 * * @param ip * IP的字符串形式 * @return 地区名字符串 */ public String getArea(String ip) { return getArea(IPSeekerUtils.getIpByteArrayFromString(ip)); } /** */ /** * 根据ip搜索ip信息文件,得到IPLocation结构,所搜索的ip参数从类成员ip中得到 * * @param ip * 要查询的IP * @return IPLocation结构 */ public IPLocation getIPLocation(byte[] ip) { IPLocation info = null; long offset = locateIP(ip); if (offset != -1) info = getIPLocation(offset); if (info == null) { info = new IPLocation(); info.country = "未知国家"; info.area = "未知地区"; } return info; } /** * 从offset位置读取4个字节为一个long,因为java为big-endian格式,所以没办法 用了这么一个函数来做转换 * * @param offset * @return 读取的long值,返回-1表示读取文件失败 */ private long readLong4(long offset) { long ret = 0; try { ipFile.seek(offset); ret |= (ipFile.readByte() & 0xFF); ret |= ((ipFile.readByte() << 8) & 0xFF00); ret |= ((ipFile.readByte() << 16) & 0xFF0000); ret |= ((ipFile.readByte() << 24) & 0xFF000000); return ret; } catch (IOException e) { return -1; } } /** * 从offset位置读取3个字节为一个long,因为java为big-endian格式,所以没办法 用了这么一个函数来做转换 * * @param offset * @return 读取的long值,返回-1表示读取文件失败 */ private long readLong3(long offset) { long ret = 0; try { ipFile.seek(offset); ipFile.readFully(b3); ret |= (b3[0] & 0xFF); ret |= ((b3[1] << 8) & 0xFF00); ret |= ((b3[2] << 16) & 0xFF0000); return ret; } catch (IOException e) { return -1; } } /** * 从当前位置读取3个字节转换成long * * @return */ private long readLong3() { long ret = 0; try { ipFile.readFully(b3); ret |= (b3[0] & 0xFF); ret |= ((b3[1] << 8) & 0xFF00); ret |= ((b3[2] << 16) & 0xFF0000); return ret; } catch (IOException e) { return -1; } } /** * 从offset位置读取四个字节的ip地址放入ip数组中,读取后的ip为big-endian格式,但是 * 文件中是little-endian形式,将会进行转换 * * @param offset * @param ip */ private void readIP(long offset, byte[] ip) { try { ipFile.seek(offset); ipFile.readFully(ip); byte temp = ip[0]; ip[0] = ip[3]; ip[3] = temp; temp = ip[1]; ip[1] = ip[2]; ip[2] = temp; } catch (IOException e) { System.out.println(e.getMessage()); } } /** * 从offset位置读取四个字节的ip地址放入ip数组中,读取后的ip为big-endian格式,但是 * 文件中是little-endian形式,将会进行转换 * * @param offset * @param ip */ private void readIP(int offset, byte[] ip) { mbb.position(offset); mbb.get(ip); byte temp = ip[0]; ip[0] = ip[3]; ip[3] = temp; temp = ip[1]; ip[1] = ip[2]; ip[2] = temp; } /** * 把类成员ip和beginIp比较,注意这个beginIp是big-endian的 * * @param ip * 要查询的IP * @param beginIp * 和被查询IP相比较的IP * @return 相等返回0,ip大于beginIp则返回1,小于返回-1。 */ private int compareIP(byte[] ip, byte[] beginIp) { for (int i = 0; i < 4; i++) { int r = compareByte(ip[i], beginIp[i]); if (r != 0) return r; } return 0; } /** * 把两个byte当作无符号数进行比较 * * @param b1 * @param b2 * @return 若b1大于b2则返回1,相等返回0,小于返回-1 */ private int compareByte(byte b1, byte b2) { if ((b1 & 0xFF) > (b2 & 0xFF)) // 比较是否大于 return 1; else if ((b1 ^ b2) == 0)// 判断是否相等 return 0; else return -1; } /** * 这个方法将根据ip的内容,定位到包含这个ip国家地区的记录处,返回一个绝对偏移 方法使用二分法查找。 * * @param ip * 要查询的IP * @return 如果找到了,返回结束IP的偏移,如果没有找到,返回-1 */ private long locateIP(byte[] ip) { long m = 0; int r; // 比较第一个ip项 readIP(ipBegin, b4); r = compareIP(ip, b4); if (r == 0) return ipBegin; else if (r < 0) return -1; // 开始二分搜索 for (long i = ipBegin, j = ipEnd; i < j;) { m = getMiddleOffset(i, j); readIP(m, b4); r = compareIP(ip, b4); // log.debug(Utils.getIpStringFromBytes(b)); if (r > 0) i = m; else if (r < 0) { if (m == j) { j -= IP_RECORD_LENGTH; m = j; } else j = m; } else return readLong3(m + 4); } // 如果循环结束了,那么i和j必定是相等的,这个记录为最可能的记录,但是并非 // 肯定就是,还要检查一下,如果是,就返回结束地址区的绝对偏移 m = readLong3(m + 4); readIP(m, b4); r = compareIP(ip, b4); if (r <= 0) return m; else return -1; } /** * 得到begin偏移和end偏移中间位置记录的偏移 * * @param begin * @param end * @return */ private long getMiddleOffset(long begin, long end) { long records = (end - begin) / IP_RECORD_LENGTH; records >>= 1; if (records == 0) records = 1; return begin + records * IP_RECORD_LENGTH; } /** * 给定一个ip国家地区记录的偏移,返回一个IPLocation结构 * * @param offset * @return */ private IPLocation getIPLocation(long offset) { try { // 跳过4字节ip ipFile.seek(offset + 4); // 读取第一个字节判断是否标志字节 byte b = ipFile.readByte(); if (b == AREA_FOLLOWED) { // 读取国家偏移 long countryOffset = readLong3(); // 跳转至偏移处 ipFile.seek(countryOffset); // 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向 b = ipFile.readByte(); if (b == NO_AREA) { loc.country = readString(readLong3()); ipFile.seek(countryOffset + 4); } else loc.country = readString(countryOffset); // 读取地区标志 loc.area = readArea(ipFile.getFilePointer()); } else if (b == NO_AREA) { loc.country = readString(readLong3()); loc.area = readArea(offset + 8); } else { loc.country = readString(ipFile.getFilePointer() - 1); loc.area = readArea(ipFile.getFilePointer()); } return loc; } catch (IOException e) { return null; } } /** * @param offset * @return */ private IPLocation getIPLocation(int offset) { // 跳过4字节ip mbb.position(offset + 4); // 读取第一个字节判断是否标志字节 byte b = mbb.get(); if (b == AREA_FOLLOWED) { // 读取国家偏移 int countryOffset = readInt3(); // 跳转至偏移处 mbb.position(countryOffset); // 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向 b = mbb.get(); if (b == NO_AREA) { loc.country = readString(readInt3()); mbb.position(countryOffset + 4); } else loc.country = readString(countryOffset); // 读取地区标志 loc.area = readArea(mbb.position()); } else if (b == NO_AREA) { loc.country = readString(readInt3()); loc.area = readArea(offset + 8); } else { loc.country = readString(mbb.position() - 1); loc.area = readArea(mbb.position()); } return loc; } /** * 从offset偏移开始解析后面的字节,读出一个地区名 * * @param offset * @return 地区名字符串 * @throws IOException */ private String readArea(long offset) throws IOException { ipFile.seek(offset); byte b = ipFile.readByte(); if (b == 0x01 || b == 0x02) { long areaOffset = readLong3(offset + 1); if (areaOffset == 0) return "未知地区"; else return readString(areaOffset); } else return readString(offset); } /** * @param offset * @return */ private String readArea(int offset) { mbb.position(offset); byte b = mbb.get(); if (b == 0x01 || b == 0x02) { int areaOffset = readInt3(); if (areaOffset == 0) return "未知地区"; else return readString(areaOffset); } else return readString(offset); } /** * 从offset偏移处读取一个以0结束的字符串 * * @param offset * @return 读取的字符串,出错返回空字符串 */ private String readString(long offset) { try { ipFile.seek(offset); int i; for (i = 0, buf[i] = ipFile.readByte(); buf[i] != 0; buf[++i] = ipFile.readByte()) ; if (i != 0) return IPSeekerUtils.getString(buf, 0, i, "GBK"); } catch (IOException e) { System.out.println(e.getMessage()); } return ""; } /** * 从内存映射文件的offset位置得到一个0结尾字符串 * * @param offset * @return */ private String readString(int offset) { try { mbb.position(offset); int i; for (i = 0, buf[i] = mbb.get(); buf[i] != 0; buf[++i] = mbb.get()) ; if (i != 0) return IPSeekerUtils.getString(buf, 0, i, "GBK"); } catch (IllegalArgumentException e) { System.out.println(e.getMessage()); } return ""; } public String getAddress(String ip) { String country = getCountry(ip).equals(" CZ88.NET") ? "" : getCountry(ip); String area = getArea(ip).equals(" CZ88.NET") ? "" : getArea(ip); String address = country + " " + area; return address.trim(); } /** * * 用来封装ip相关信息,目前只有两个字段,ip所在的国家和地区 * * * @author swallow */ public class IPLocation { public String country; public String area; public IPLocation() { country = area = ""; } public IPLocation getCopy() { IPLocation ret = new IPLocation(); ret.country = country; ret.area = area; return ret; } } /** * 一条IP范围记录,不仅包括国家和区域,也包括起始IP和结束IP * * * * @author gerry liu */ public class IPEntry { public String beginIp; public String endIp; public String country; public String area; public IPEntry() { beginIp = endIp = country = area = ""; } public String toString() { return this.area + " " + this.country + "IP Χ:" + this.beginIp + "-" + this.endIp; } } /** * 操作工具类 * * @author gerryliu * */ public static class IPSeekerUtils { /** * 从ip的字符串形式得到字节数组形式 * * @param ip * 字符串形式的ip * @return 字节数组形式的ip */ public static byte[] getIpByteArrayFromString(String ip) { byte[] ret = new byte[4]; java.util.StringTokenizer st = new java.util.StringTokenizer(ip, "."); try { ret[0] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF); ret[1] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF); ret[2] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF); ret[3] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF); } catch (Exception e) { System.out.println(e.getMessage()); } return ret; } /** * 对原始字符串进行编码转换,如果失败,返回原始的字符串 * * @param s * 原始字符串 * @param srcEncoding * 源编码方式 * @param destEncoding * 目标编码方式 * @return 转换编码后的字符串,失败返回原始字符串 */ public static String getString(String s, String srcEncoding, String destEncoding) { try { return new String(s.getBytes(srcEncoding), destEncoding); } catch (UnsupportedEncodingException e) { return s; } } /** * 根据某种编码方式将字节数组转换成字符串 * * @param b * 字节数组 * @param encoding * 编码方式 * @return 如果encoding不支持,返回一个缺省编码的字符串 */ public static String getString(byte[] b, String encoding) { try { return new String(b, encoding); } catch (UnsupportedEncodingException e) { return new String(b); } } /** * 根据某种编码方式将字节数组转换成字符串 * * @param b * 字节数组 * @param offset * 要转换的起始位置 * @param len * 要转换的长度 * @param encoding * 编码方式 * @return 如果encoding不支持,返回一个缺省编码的字符串 */ public static String getString(byte[] b, int offset, int len, String encoding) { try { return new String(b, offset, len, encoding); } catch (UnsupportedEncodingException e) { return new String(b, offset, len); } } /** * @param ip * ip的字节数组形式 * @return 字符串形式的ip */ public static String getIpStringFromBytes(byte[] ip) { StringBuffer sb = new StringBuffer(); sb.append(ip[0] & 0xFF); sb.append('.'); sb.append(ip[1] & 0xFF); sb.append('.'); sb.append(ip[2] & 0xFF); sb.append('.'); sb.append(ip[3] & 0xFF); return sb.toString(); } } /** * 获取全部ip地址集合列表 * * @return */ public List<String> getAllIp() { List<String> list = new ArrayList<String>(); byte[] buf = new byte[4]; for (long i = ipBegin; i < ipEnd; i += IP_RECORD_LENGTH) { try { this.readIP(this.readLong3(i + 4), buf); // 读取ip,最终ip放到buf中 String ip = IPSeekerUtils.getIpStringFromBytes(buf); list.add(ip); } catch (Exception e) { // nothing } } return list; } }它用于解析IP地址并获取其对应的国家和地区信息。
这个类包含了几个方法,用于从文件中读取IP地址信息,解析IP地址,并获取其国家、地区、城市等信息。
getCountry方法:用于根据IP地址获取国家信息。getArea方法:用于根据IP地址获取地区信息。getCity方法:用于根据IP地址获取城市信息。locateIP方法:用于根据IP地址在文件中查找对应的记录。readIP方法:用于从文件中读取IP地址信息。readString方法:用于从文件中读取字符串信息。
这些方法的使用需要一个名为IPSeekerUtils的辅助类,它提供了将IP地址转换为字符串、从字节数组中读取字符串等辅助功能。这个类的设计是为了处理IP地址数据库文件,该文件包含大量的IP地址及其对应的国家和地区信息。通过这个类,可以方便地查询任意IP地址的国家和地区信息。
LogParser.java详细解释
package com.IPutils; import org.apache.commons.lang3.StringUtils; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.HashMap; import java.util.Map; public class LogParser { private Logger logger = LoggerFactory.getLogger(LogParser.class); public Map<String, String> parse2(String log) { Map<String, String> logInfo = new HashMap<String,String>(); IPParser ipParse = IPParser.getInstance(); if(StringUtils.isNotBlank(log)) { String[] splits = log.split("\t"); String ip = splits[0]; String url = splits[1]; String sessionId = splits[2]; String time = splits[3]; String country = splits[4]; String province = splits[5]; String city = splits[6]; logInfo.put("ip",ip); logInfo.put("url",url); logInfo.put("sessionId",sessionId); logInfo.put("time",time); logInfo.put("country",country); logInfo.put("province",province); logInfo.put("city",city); } else{ logger.error("日志记录的格式不正确:" + log); } return logInfo; } public Map<String, String> parse(String log) { Map<String, String> logInfo = new HashMap<String,String>(); IPParser ipParse = IPParser.getInstance(); if(StringUtils.isNotBlank(log)) { String[] splits = log.split("\001"); String ip = splits[13]; String url = splits[1]; String sessionId = splits[10]; String time = splits[17]; logInfo.put("ip",ip); logInfo.put("url",url); logInfo.put("sessionId",sessionId); logInfo.put("time",time); IPParser.RegionInfo regionInfo = ipParse.analyseIp(ip); logInfo.put("country",regionInfo.getCountry()); logInfo.put("province",regionInfo.getProvince()); logInfo.put("city",regionInfo.getCity()); } else{ logger.error("日志记录的格式不正确:" + log); } return logInfo; } }该类使用Apache Commons Lang库中的
StringUtils类进行字符串操作,并使用SLF4J进行日志记录。
这个类中有两个方法:parse2和parse。
parse2:这个方法接受一个日志条目作为字符串,并使用制表符(\t)作为分隔符进行分割。然后它提取IP、URL、会话ID、时间、国家、省份和城市信息,并将它们存储在一个HashMap中。如果日志条目为空或格式不符合预期,它将记录一个错误。parse:这个方法与parse2类似,但使用不同的分隔符(\001,这是一个不可打印字符)并从日志条目中提取不同的字段。它还使用一个IPParser对象来分析IP地址并获取地理位置信息,然后这些信息存储在HashMap中。两个方法都返回包含提取信息的
HashMap。
ProviceStatApp.java详细解释
package com.IPutils; >import org.apache.commons.lang3.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException; import java.net.URI; import java.util.Map; /** * 省份浏览量统计 */ public class ProvinceStatApp { public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); FileSystem hdfs = FileSystem.get(new URI("hdfs://hadoop102:8020"),new Configuration()); Path outputPath = new Path("hdfs://hadoop102:8020/IPTest/output1"); if (hdfs.exists(outputPath)) { hdfs.delete(outputPath, true); } Job job = Job.getInstance(configuration); job.setJarByClass(ProvinceStatApp.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); TextInputFormat.setInputPaths(job, new >Path("hdfs://hadoop102:8020/trackinfo/input/trackinfo.txt")); TextOutputFormat.setOutputPath(job, new Path("hdfs://hadoop102:8020/IPTest/output1")); job.waitForCompletion(true); } static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { private LongWritable ONE = new LongWritable(1); private LogParser logParser; @Override protected void setup(Context context) throws IOException, InterruptedException { logParser = new LogParser(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String log = value.toString(); Map<String, String> info = logParser.parse(log); String ip = info.get("ip"); if (StringUtils.isNotBlank(ip)) { IPParser.RegionInfo regionInfo = IPParser.getInstance().analyseIp(ip); if (regionInfo != null) { String provine = regionInfo.getProvince(); if (StringUtils.isNotBlank(provine)) { context.write(new Text(provine), ONE); } else { context.write(new Text("-"), ONE); } } else { context.write(new Text("-"), ONE); } } else { context.write(new Text("-"), ONE); } } } static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long count = 0; System.out.println(context); for (LongWritable value : values) { count++; } context.write(key, new LongWritable(count)); } } }
Mapper类这个Mapper类用于处理日志数据,并将数据映射到键值对。
这里是代码的详细解释:
MyMapper类继承自Mapper,它接受LongWritable类型的键和Text类型的值。它输出的键也是Text类型,而值是LongWritable类型。
setup方法:在Map任务开始时被调用一次。在这个方法中,创建了一个LogParser对象实例,这个对象用于解析日志条目。map方法:这是MapReduce框架中的核心方法,它对输入的每一条记录(key-value对)执行一次。在这个方法中,首先获取日志条目的字符串表示。然后,使用LogParser对象解析这个日志条目,提取IP地址。接下来,代码使用
IPParser对象获取IP地址对应的国家和地区信息。如果地区信息不为空,则将地区作为键,并输出一个LongWritable类型的值(在这里是1)。
如果IP地址为空,或者无法解析出地区信息,则输出键为"-"(表示未知地区),值仍然是LongWritable类型的1。
这个Mapper类可以作为一个MapReduce作业的一部分,用于处理包含IP地址的日志数据,并将这些IP地址的地区信息进行统计。
Reducer类这个Reducer类用于将来自多个Mapper类的输出合并在一起,并进行聚合操作。
这里是代码的详细解释:
MyReducer类继承自Reducer,它接受Text类型的键和LongWritable类型的迭代器作为输入。它输出的键也是Text类型,而值是LongWritable类型。
reduce方法:这是MapReduce框架中的核心方法,它对所有具有相同键的Mapper输出进行聚合。在这个方法中,首先创建一个计数器count,用于累加所有values中的值。
代码通过迭代values中的每个LongWritable对象,并增加count的值。最后,代码将键和累加后的计数器值作为输出写入到context中。这里的输出是一个键值对,键是Text类型的,值是LongWritable类型的计数。
这个Reducer类可以作为一个MapReduce作业的一部分,用于处理由MyMapper类生成的数据,并进行计数操作,例如统计每个地区出现的次数。
Main方法它用于启动一个Hadoop MapReduce作业。这个作业的目的是处理HDFS上的日志文件,统计每个省份的记录数量。
这里是代码的详细解释:
- 首先,创建一个
Configuration对象,这是Hadoop配置信息的主要容器。- 使用这个配置对象,获取
FileSystem对象,用于与HDFS进行交互。- 创建一个输出路径
outputPath,如果这个路径已经存在,则删除它。- 创建一个
Job对象,它是MapReduce作业的入口点。设置作业的Jar包(这里应该是包含Mapper和Reducer类的Jar包)和作业的名称。- 设置
Mapper和Reducer类,它们分别是MyMapper和MyReducer。- 设置Map输出和Reduce输出的键和值类型。
- 设置输入路径,这里是指定HDFS上的一个日志文件。
- 设置输出路径,这是MapReduce作业完成后结果的存放路径。
- 调用
job.waitForCompletion(true);等待作业完成。这个程序可以作为一个独立的Java应用程序运行,它会启动一个MapReduce作业,处理HDFS上的日志文件,并输出每个省份的记录数量。
代码已上传至Gitee
https://gitee.com/lijiarui-1/test/tree/master/Test_project2

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









