







文章目录
项目需求
统计每个手机号上行流量和、下行流量和、总流量和(上
行流量和+下行流量和),并且:将统计结果按照手机号的前缀
进行区分,并输出到不同的输出文件中去。
13* ==> …
15* ==> …
other ==> …
整体架构流程

PhoneFlow.java ------- 封装手机流量数据,包括上行流量、下行流量和总流量
PhoneFlowMapper.java ------- 从输入的文本行中提取手机号码、上行流量和下行流量,并将它们作为键值对输出
MyPartitioner ------- 根据输入数据的特定特征将数据分配到不同的分区中并将数据传给Reduce进行处理
PhoneFlowReducer.java ------- 将Map阶段输出的按MyPartitioner分类的手机流量数据进行汇总,计算出每个分类的总上行流量和总下行流量,并将结果输出
LocationPartMain.java ------- 继承自Configured并实现了Tool接口。这允许该类作为Hadoop工具运行
相关技术
MapReduce的基本原理和流程
MapReduce 把任务分为 Map 阶段和 Reduce 阶段。开发人员使用存储在HDFS 中数据(可实现快速存储),编写 Hadoop 的 MapReduce 任务

Map阶段(Mapper):
输入数据被分割成一系列小的数据块(键值对),这些块被分发到集群中的多个节点上。
每个节点上的Mapper会独立处理这些数据块,对每个键应用映射函数(map function),将原始键值对转换为一组新的键值对,生成中间结果。
这些中间结果通常基于相同的键进行排序,以便后续的Reduce阶段能更有效地合并。
Shuffle阶段:
Mapper完成后,会将中间键值对发送回一个称为"shuffle"的过程,这个过程根据键进行排序,使得具有相同键的值聚集在一起。
Reduce阶段(Reducer):
Shuffle阶段结束后,每个键的值集合会被发送到同一个Reducer节点,Reducer接收到这些值后,应用reduce函数(reduce function),对相同键的所有值进行汇总,生成最终的结果。
Reduce函数通常是对所有值进行某种聚合操作,比如求和、计数、平均值等。
数据集分析
数据集
链接:https://pan.baidu.com/s/1qSCdH9eEhIAsjJaWirDeQw?pwd=gnz1
提取码:gnz1

以第一行数据为例每个数据对应的属性
| 数据 | 属性 |
|---|---|
| 1363157985066 | 时间戳 |
| 13726230503 | 电话号码 |
| 00-FD-07-A4-72-B8:CMCC | 基站的物理地址 |
| 120.196.100.82 | 访问网址的ip |
| i02.c.aliimg.com | 网站域名 |
| 24 | 数据包 |
| 27 | 接包数 |
| 2481 | 上行/传流量 |
| 24681 | 下行/载流量 |
| 200 | 响应码 |
实验步骤
- 先在虚拟机上创建一个txt文件
创建一个输入数据的文件夹
mkdir input
创建txt文件
vim input.txt
- 将数据复制到txt文件里(也可以用xftp直接传上去)
注意:复制数据后要查看数据最后一行有没有回车,如果有回车,处理数据时就会把最后一行也算在内,会出现HDFS上有输出数据的文件夹,但是文件夹里面没有数据 - 启动Hadoop集群
启动HDFS
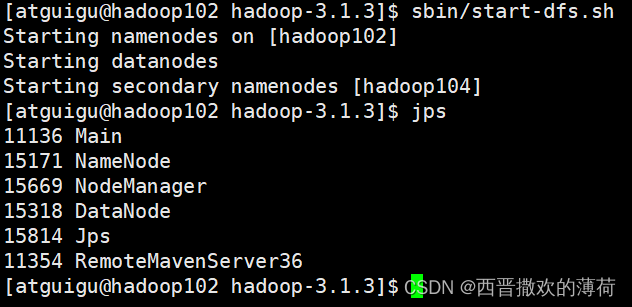
启动yarn
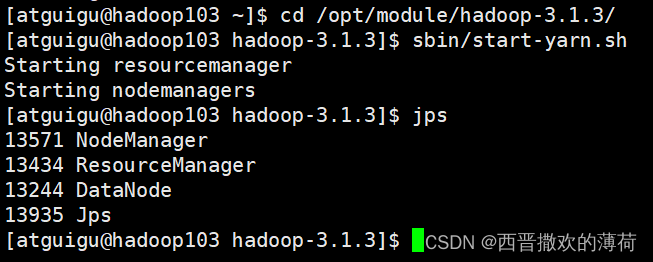
- 将数据传到HDFS上
在HDFS上创建存放的文件夹
hdfs dfs -mkdir -p /flow/input/
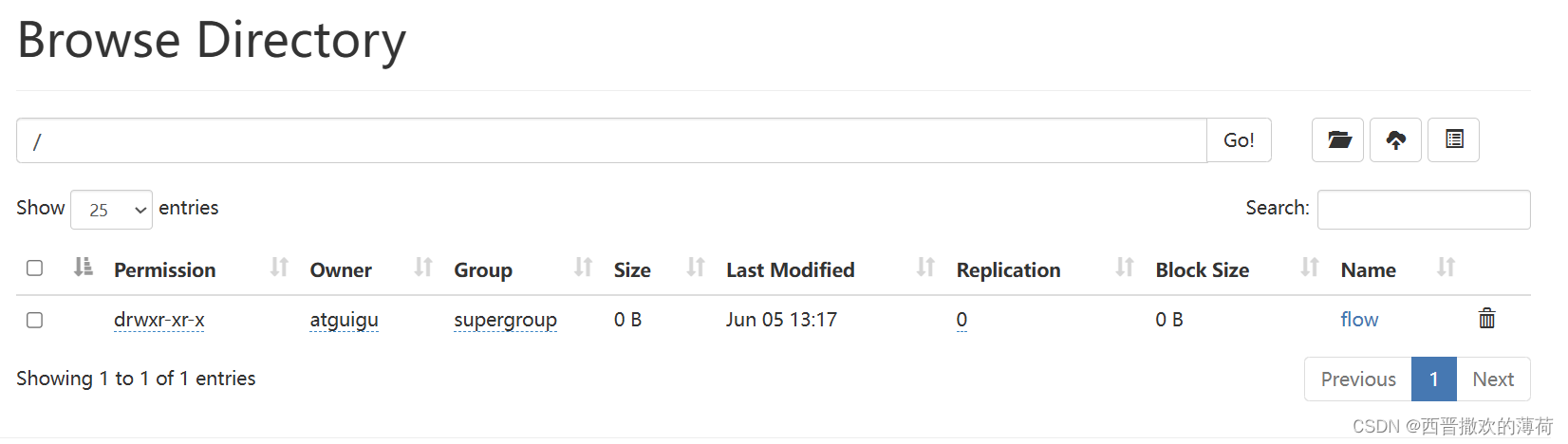

hdfs dfs -put input.txt /flow/input/
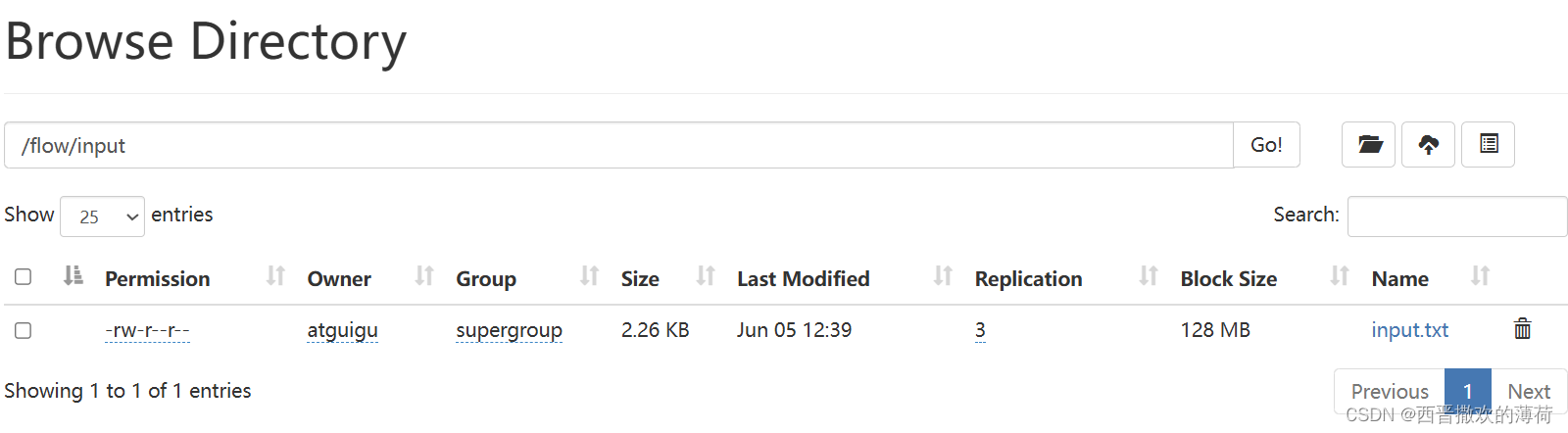
- 运行代码


- 查看结果
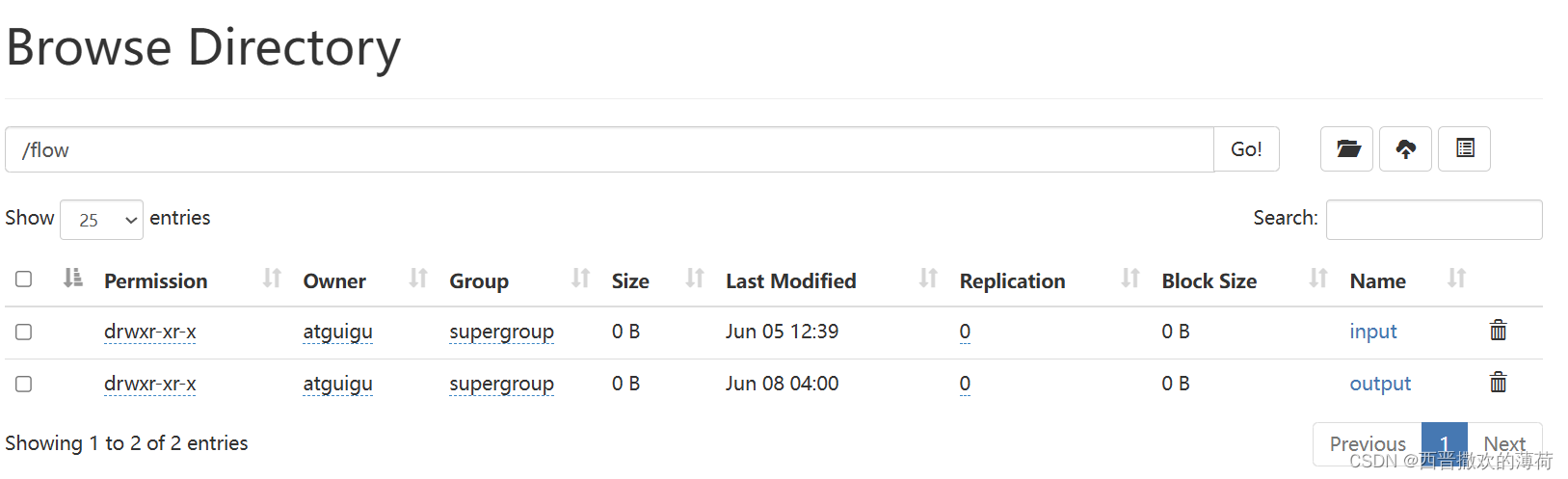
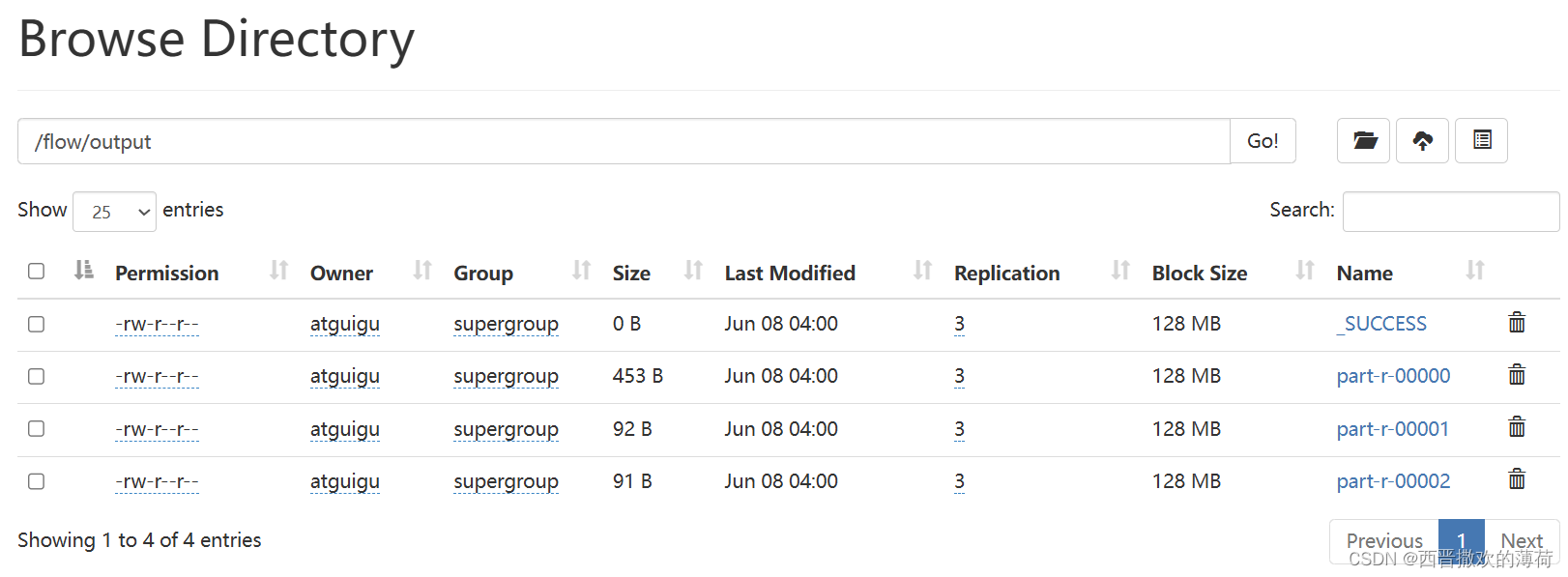
-
以
13为开头的数据

-
以15为开头的数据

-
其他数据

代码
PhoneFlow.java
package com.tao.CountFlow; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** 1. 封装上行流量、下行流量、总流量 */ public class PhoneFlow implements Writable{ private Long up; private Long down; private Long sum; public PhoneFlow() { } public PhoneFlow(Long up, Long down) { this.up = up; this.down = down; this.sum = up+down; } public Long getUp() { return up; } public void setUp(Long up) { this.up = up; } public Long getDown() { return down; } public void setDown(Long down) { this.down = down; } public Long getSum() { return sum; } public void setSum(Long sum) { this.sum = sum; } @Override public String toString() { return String.valueOf(up) + " "+String.valueOf(down) +" "+ String.valueOf(sum); } //序列化 public void write(DataOutput dataOutput) throws IOException { dataOutput.writeLong(up); dataOutput.writeLong(down); dataOutput.writeLong(sum); } //反序列化 public void readFields(DataInput dataInput) throws IOException { up = dataInput.readLong(); down = dataInput.readLong(); sum = dataInput.readLong(); } }
PhoneFlowMapper.java
package com.tao.CountFlow; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class PhoneFlowMapper extends Mapper<LongWritable,Text, Text, PhoneFlow> >{ @Override protected void map(LongWritable key, Text value, Context context) throws >IOException, InterruptedException { //1、将每一行的内容转换为string并进行拆分 String[] split = value.toString().split("\\s+"); //2、获取手机号码、上行流量、下行流量 String phoneNumber = split[1]; long up = Long.parseLong(split[split.length-3]); long down = Long.parseLong(split[split.length-2]); //3、写入上下文 context.write(new Text(phoneNumber), new PhoneFlow(up, down)); } }
PhoneFlowReducer.java
package com.tao.CountFlow; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class PhoneFlowReducer extends Reducer<Text,PhoneFlow,Text,PhoneFlow> { @Override protected void reduce(Text key, Iterable<PhoneFlow> values, Context context) throws IOException, InterruptedException { long sumUp = 0; long sumDown = 0; //1、将所有的上行流量和下行流量求和 for(PhoneFlow phoneFlow :values){ sumUp = sumUp + phoneFlow.getUp(); sumDown = sumDown + phoneFlow.getDown(); } //2、获取总流量 PhoneFlow phoneFlow = new PhoneFlow(sumUp,sumDown); //3、写入上下文 context.write(key,phoneFlow); } }
MyPartitioner.java
package com.tao.LocationPart; import com.tao.CountFlow.PhoneFlow; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; /** * 输入类型和map阶段相同 */ public class MyPartitioner extends Partitioner<Text, PhoneFlow> { @Override public int getPartition(Text text, PhoneFlow phoneFlow, int i) { //1、获取前两位号码 String num = text.toString().substring(0,2); //2、观察文档,有134、135、136、137、138、139、182、841、159、150、183开头的地区 //设置分区为13、15和其他 switch (num) { case "13": return 0; case "15": return 1; default: return 2; } } }
LocationPartMain.java
package com.tao.LocationPart; import com.tao.CountFlow.PhoneFlow; import com.tao.CountFlow.PhoneFlowMapper; import com.tao.CountFlow.PhoneFlowReducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.net.URI; public class LocationPartMain extends Configured implements Tool { /** * 该方法用于指定一个job任务 */ public int run(String[] strings) throws Exception { //1、创建一个job Job job = Job.getInstance(super.getConf(),"locationPart"); //2、配置job任务对象(八个步骤) //第一步:指定文件的读取方式和读取路径 job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("hdfs://hadoop102:8020/flow/input/input.txt")); //第二步:指定map阶段的处理方式和数据类型 job.setMapperClass(PhoneFlowMapper.class); job.setJarByClass(PhoneFlowMapper.class); //设置map阶段k2的类型 job.setMapOutputKeyClass(Text.class); //设置map阶段v2的类型 job.setMapOutputValueClass(PhoneFlow.class); //第三、四、五、六步:shuffle 采用默认的方式 //第七步:指定reduce阶段的处理方式和数据类型 job.setReducerClass(PhoneFlowReducer.class); job.setJarByClass(PhoneFlowReducer.class); //设置k3的类型 job.setOutputKeyClass(Text.class); //设置v3的类型 job.setOutputValueClass(PhoneFlow.class); //第八步:设置输出类型 job.setOutputFormatClass(TextOutputFormat.class); //设置输出的路径 Path path = new Path("hdfs://hadoop102:8020/flow/output"); TextOutputFormat.setOutputPath(job,path); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),new Configuration()); if(fs.exists(path)){ fs.delete(path,true); } //设置part job.setPartitionerClass(MyPartitioner.class); //设置分区数量 job.setNumReduceTasks(3); //等待任务结束 boolean b1 = job.waitForCompletion(true); return b1? 0:1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); //启动job任务 int run = ToolRunner.run(conf,new LocationPartMain(),args); System.exit(run); } }
代码细节
PhoneFlow.java详细解释
package com.tao.CountFlow; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** 1. 封装上行流量、下行流量、总流量 */ public class PhoneFlow implements Writable{ private Long up; private Long down; private Long sum; public PhoneFlow() { } public PhoneFlow(Long up, Long down) { this.up = up; this.down = down; this.sum = up+down; } public Long getUp() { return up; } public void setUp(Long up) { this.up = up; } public Long getDown() { return down; } public void setDown(Long down) { this.down = down; } public Long getSum() { return sum; } public void setSum(Long sum) { this.sum = sum; } @Override public String toString() { return String.valueOf(up) + " "+String.valueOf(down) +" "+ String.valueOf(sum); } //序列化 public void write(DataOutput dataOutput) throws IOException { dataOutput.writeLong(up); dataOutput.writeLong(down); dataOutput.writeLong(sum); } //反序列化 public void readFields(DataInput dataInput) throws IOException { up = dataInput.readLong(); down = dataInput.readLong(); sum = dataInput.readLong(); } }它实现了
Writable接口,用于在Hadoop框架中处理数据。这个类的主要目的是封装手机流量数据,包括上行流量、下行流量和总流量。
- 类定义
public class PhoneFlow implements Writable这行代码定义了一个名为
PhoneFlow的公共类,它实现了Writable接口。Writable是Hadoop框架中用于数据序列化和反序列化的接口。
- 成员变量
private Long up; private Long down; private Long sum;这里定义了三个私有成员变量:
up(上行流量)、down(下行流量)和sum(总流量)。
- 构造函数
- 无参构造函数
public PhoneFlow() { }这是一个无参构造函数,用于创建
PhoneFlow对象时不传入任何参数。
- 带参数的构造函数
public PhoneFlow(Long up, Long down) { this.up = up; this.down = down; this.sum = up+down; }这个构造函数接受上行流量和下行流量作为参数,并计算总流量。
- Getter和Setter方法
public Long getUp() { return up; } public void setUp(Long up) { this.up = up; } public Long getDown() { return down; } public void setDown(Long down) { this.down = down; } public Long getSum() { return sum; } public void setSum(Long sum) { this.sum = sum; }用于获取和设置
up(上行流量)、down(下行流量)和sum(总流量)的值。
- toString方法
public String toString() { return String.valueOf(up) + " "+String.valueOf(down) +" "+ String.valueOf(sum); }这个方法重写了
Object类的toString方法,用于返回PhoneFlow对象的字符串表示,格式为“上行流量 下行流量 总流量”。
- 序列化和反序列化方法
write方法public void write(DataOutput dataOutput) throws IOException { dataOutput.writeLong(up); dataOutput.writeLong(down); dataOutput.writeLong(sum); }
readFields方法
这个方法用于将PhoneFlow对象的数据写入到DataOutput流中,以便进行序列化。public void readFields(DataInput dataInput) throws IOException { up = dataInput.readLong(); down = dataInput.readLong(); sum = dataInput.readLong(); }这个方法用于从
DataInput流中读取数据,以便进行反序列化。
PhoneFlowMapper.java详细解释
package com.tao.CountFlow; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class PhoneFlowMapper extends Mapper<LongWritable,Text, Text, PhoneFlow> >{ @Override protected void map(LongWritable key, Text value, Context context) throws >IOException, InterruptedException { //1、将每一行的内容转换为string并进行拆分 String[] split = value.toString().split("\\s+"); //2、获取手机号码、上行流量、下行流量 String phoneNumber = split[1]; long up = Long.parseLong(split[split.length-3]); long down = Long.parseLong(split[split.length-2]); //3、写入上下文 context.write(new Text(phoneNumber), new PhoneFlow(up, down)); } }它定义了一个名为
PhoneFlowMapper的Mapper类,该类继承自Mapper类。这个Mapper的作用是处理输入数据,并将其转换为适合进一步处理的格式。
- 类定义
public class PhoneFlowMapper extends Mapper<LongWritable, Text, Text, PhoneFlow>这行代码定义了一个名为
PhoneFlowMapper的类,它继承自Mapper类。这个类用于处理键值对,其中键(Key)是LongWritable类型,值(Value)是Text类型。Mapper的输出键值对的键是Text类型,值是PhoneFlow类型。
- map方法
@Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //1、将每一行的内容转换为string并进行拆分 String[] split = value.toString().split("\\s+"); //2、获取手机号码、上行流量、下行流量 String phoneNumber = split[1]; long up = Long.parseLong(split[split.length-3]); long down = Long.parseLong(split[split.length-2]); //3、写入上下文 context.write(new Text(phoneNumber), new PhoneFlow(up, down)); }这是Mapper类的核心方法,用于处理每个输入的键值对。
key是输入数据的键,value是输入数据的值,context用于输出处理后的数据。
- 数据处理
- 将输入的文本行(value)转换为字符串并拆分
String[] split = value.toString().split("\\s+");这里使用split方法按空白字符(如空格、制表符等)拆分字符串。
- 从拆分后的数组中提取手机号码、上行流量和下行流量
String phoneNumber = split[1]; long up = Long.parseLong(split[split.length-3]); long down = Long.parseLong(split[split.length-2]);手机号码位于拆分数组的第二个位置,上行流量和下行流量分别位于倒数第三和倒数第二个位置
4.写入上下文
context.write(new Text(phoneNumber), new PhoneFlow(up, down));将处理后的数据写入上下文,以便后续处理。这里使用手机号码作为键,创建一个新的
PhoneFlow对象作为值,其中包含上行流量和下行流量。
PhoneFlowReducer.java详细解释
package com.tao.CountFlow; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class PhoneFlowReducer extends Reducer<Text,PhoneFlow,Text,PhoneFlow> { @Override protected void reduce(Text key, Iterable<PhoneFlow> values, Context context) throws IOException, InterruptedException { long sumUp = 0; long sumDown = 0; //1、将所有的上行流量和下行流量求和 for(PhoneFlow phoneFlow :values){ sumUp = sumUp + phoneFlow.getUp(); sumDown = sumDown + phoneFlow.getDown(); } //2、获取总流量 PhoneFlow phoneFlow = new PhoneFlow(sumUp,sumDown); //3、写入上下文 context.write(key,phoneFlow); } }这是一个
Reducer类,用于汇总Map阶段的输出结果。
- 类定义
public class PhoneFlowReducer extends Reducer<Text, PhoneFlow, Text, PhoneFlow>这行代码定义了一个名为
PhoneFlowReducer的类,它继承自Hadoop的Reducer类。这个Reducer处理的输入键值对是<Text, PhoneFlow>类型,输出键值对也是<Text, PhoneFlow>类型。
- reduce方法
@Override protected void reduce(Text key, Iterable<PhoneFlow> values, Context context) throws IOException, InterruptedException这是重写的reduce方法,它是MapReduce框架中Reducer的核心方法。该方法接收三个参数:
Text key:Map阶段输出的键,通常是某种分类标准(如日期、用户ID等)。Iterable<PhoneFlow> values:与给定键关联的所有PhoneFlow对象的集合。Context context:用于输出结果的上下文对象。
- 流量求和
long sumDown = 0; for(PhoneFlow phoneFlow : values){ sumUp = sumUp + phoneFlow.getUp(); sumDown = sumDown + phoneFlow.getDown(); }在这个循环中,Reducer遍历所有与当前键关联的
PhoneFlow对象。对于每个对象,它将上行流量(getUp())和下行流量(getDown())累加到sumUp和sumDown变量中。
- 创建新的PhoneFlow对象
PhoneFlow phoneFlow = new PhoneFlow(sumUp, sumDown);创建一个新的
PhoneFlow对象,其上行和下行流量分别是之前计算的总和。
- 写入结果
context.write(key,phoneFlow);将键和对应的新
PhoneFlow对象写入上下文中,以便输出。
MyPartitioner.java详细解释
package com.tao.LocationPart; import com.tao.CountFlow.PhoneFlow; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; /** * 输入类型和map阶段相同 */ public class MyPartitioner extends Partitioner<Text, PhoneFlow> { @Override public int getPartition(Text text, PhoneFlow phoneFlow, int i) { //1、获取前两位号码 String num = text.toString().substring(0,2); //2、观察文档,有134、135、136、137、138、139、182、841、159、150、183开头的地区 //设置分区为13、15和其他 switch (num) { case "13": return 0; case "15": return 1; default: return 2; } } }这是一个Java类,用于在Hadoop MapReduce框架中实现自定义的数据分区逻辑。这个类名为
MyPartitioner,继承自Partitioner类。它的主要作用是根据输入数据的特定特征将数据分配到不同的分区中,以便在MapReduce作业中进行更有效的数据处理。
- 类定义
public class MyPartitioner extends Partitioner<Text, PhoneFlow>
MyPartitioner类继承自Partitioner类,并指定了其输入类型为Text和PhoneFlow。这意味着在MapReduce作业中,它将接收Text和PhoneFlow类型的数据作为输入。
- 重写
getPartition方法
@Override public int getPartition(Text text, PhoneFlow phoneFlow, int i)这个方法是
Partitioner类的核心,用于定义如何根据输入数据将数据分配到不同的分区。它接收三个参数:Text text、PhoneFlow phoneFlow和int i。其中i是分区的数量。
- 分区逻辑
String num = text.toString().substring(0,2); switch (num) { case "13": return 0; case "15": return 1; default: return 2; }首先从
Text对象中提取前两个字符,这些字符代表电话号码的前缀。然后,根据这些前缀将数据分配到不同的分区。例如,如果前缀是"13"或"15",则分别分配到分区0和1;否则,分配到分区2。
LocationPartMain.java详细解释
package com.tao.LocationPart; import com.tao.CountFlow.PhoneFlow; import com.tao.CountFlow.PhoneFlowMapper; import com.tao.CountFlow.PhoneFlowReducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.net.URI; public class LocationPartMain extends Configured implements Tool { /** * 该方法用于指定一个job任务 */ public int run(String[] strings) throws Exception { //1、创建一个job Job job = Job.getInstance(super.getConf(),"locationPart"); //2、配置job任务对象(八个步骤) //第一步:指定文件的读取方式和读取路径 job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("hdfs://hadoop102:8020/flow/input/input.txt")); //第二步:指定map阶段的处理方式和数据类型 job.setMapperClass(PhoneFlowMapper.class); job.setJarByClass(PhoneFlowMapper.class); //设置map阶段k2的类型 job.setMapOutputKeyClass(Text.class); //设置map阶段v2的类型 job.setMapOutputValueClass(PhoneFlow.class); //第三、四、五、六步:shuffle 采用默认的方式 //第七步:指定reduce阶段的处理方式和数据类型 job.setReducerClass(PhoneFlowReducer.class); job.setJarByClass(PhoneFlowReducer.class); //设置k3的类型 job.setOutputKeyClass(Text.class); //设置v3的类型 job.setOutputValueClass(PhoneFlow.class); //第八步:设置输出类型 job.setOutputFormatClass(TextOutputFormat.class); //设置输出的路径 Path path = new Path("hdfs://hadoop102:8020/flow/output"); TextOutputFormat.setOutputPath(job,path); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),new Configuration()); if(fs.exists(path)){ fs.delete(path,true); } //设置part job.setPartitionerClass(MyPartitioner.class); //设置分区数量 job.setNumReduceTasks(3); //等待任务结束 boolean b1 = job.waitForCompletion(true); return b1? 0:1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); //启动job任务 int run = ToolRunner.run(conf,new LocationPartMain(),args); System.exit(run); } }使用Apache Hadoop MapReduce框架的Java程序,主要用于处理大规模数据集。
- 类定义
public class LocationPartMain extends Configured implements Tool定义了一个名为
LocationPartMain的类,它继承自Configured并实现了Tool接口。这允许该类作为Hadoop工具运行。
- run方法
public int run(String[] strings) throws Exception { //1、创建一个job Job job = Job.getInstance(super.getConf(),"locationPart"); //2、配置job任务对象(八个步骤) //第一步:指定文件的读取方式和读取路径 job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("hdfs://hadoop102:8020/flow/input/input.txt")); //第二步:指定map阶段的处理方式和数据类型 job.setMapperClass(PhoneFlowMapper.class); job.setJarByClass(PhoneFlowMapper.class); //设置map阶段k2的类型 job.setMapOutputKeyClass(Text.class); //设置map阶段v2的类型 job.setMapOutputValueClass(PhoneFlow.class); //第三、四、五、六步:shuffle 采用默认的方式 //第七步:指定reduce阶段的处理方式和数据类型 job.setReducerClass(PhoneFlowReducer.class); job.setJarByClass(PhoneFlowReducer.class); //设置k3的类型 job.setOutputKeyClass(Text.class); //设置v3的类型 job.setOutputValueClass(PhoneFlow.class); //第八步:设置输出类型 job.setOutputFormatClass(TextOutputFormat.class); //设置输出的路径 Path path = new Path("hdfs://hadoop102:8020/flow/output"); TextOutputFormat.setOutputPath(job,path); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),new Configuration()); if(fs.exists(path)){ fs.delete(path,true); } //设置part job.setPartitionerClass(MyPartitioner.class); //设置分区数量 job.setNumReduceTasks(3); //等待任务结束 boolean b1 = job.waitForCompletion(true); return b1? 0:1; }
- 这是
Tool接口的核心方法,用于配置和执行MapReduce作业。- 创建了一个
Job实例,命名为"locationPart"。- 配置了作业的输入和输出格式、Mapper和Reducer类、输出键值类型等。
- 指定了输入路径(
hdfs://hadoop102:8020/flow/input/input.txt)和输出路径(hdfs://hadoop102:8020/flow/output)。- 设置了自定义的分区器
MyPartitioner和Reduce任务的数量为3。- 最后,调用
job.waitForCompletion(true)等待作业完成,并根据作业成功与否返回相应的退出码。
- main方法
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); //启动job任务 int run = ToolRunner.run(conf,new LocationPartMain(),args); System.exit(run); }
- 创建了一个
Configuration实例。- 使用
ToolRunner.run启动MapReduce作业,传入配置和LocationPartMain类的实例。- 根据作业执行结果退出程序。
- MapReduce流程
- Mapper (
PhoneFlowMapper): 处理输入数据,生成中间键值对。- Shuffle and Sort: 默认方式,对Mapper的输出进行排序和分组。
- Reducer (
PhoneFlowReducer): 对每个键的所有值进行汇总处理。- Output: 将Reducer的输出写入到指定的HDFS路径。
- 自定义分区(Mypartitioner)
- 用于控制数据如何分配到不同的Reducer。
- 作业配置
- 输入和输出格式均为文本格式。
- Mapper和Reducer的输出键值类型均为
Text和PhoneFlow。
代码已上传至Gitee
https://gitee.com/lijiarui-1/test/tree/master/Test_project
















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









