




一、图形显示技术基础
1.1 计算机图形显示简史
从CRT到现代显示器
早期的CRT显示器通过模拟信号逐行扫描成像,而现代显示器(如LCD、OLED)则依赖数字信号和像素矩阵。显示技术演进带来两个核心需求:
- 精准控制显示时序(水平同步、垂直同步)
- 高效传输像素数据(从内存到屏幕)
1.2 图形渲染流程
应用程序 → 图形API(OpenGL/Vulkan) → GPU驱动 → 显示控制器 → 显示器
关键环节:
- 合成(Composition):多窗口内容合并
- 扫描输出(Scanout):将帧缓冲区内容输出到屏幕
二、DRM(Direct Rendering Manager)详解
2.1 DRM的诞生背景
- 传统问题:X Server独占GPU导致无法直接渲染
- 解决方案:在内核中统一管理GPU资源(2006年引入Linux内核)
2.2 DRM核心组件
| 组件 | 功能描述 |
|---|---|
| GEM | 显存管理(Graphics Execution Manager) |
| TTM | 显存迁移与交换(已逐步被GEM取代) |
| KMS | 显示模式设置与显示管线控制(下文详解) |
2.3 DRM设备操作示例
// 打开DRM设备
int fd = open("/dev/dri/card0", O_RDWR);
// 获取设备能力
drmGetCap(fd, DRM_CAP_DUMB_BUFFER, &cap);
// 创建Dumb Buffer(CPU可访问的显存)
struct drm_mode_create_dumb create_arg = {0};
ioctl(fd, DRM_IOCTL_MODE_CREATE_DUMB, &create_arg);
// 映射Buffer到用户空间
struct drm_mode_map_dumb map_arg = { .handle = create_arg.handle };
ioctl(fd, DRM_IOCTL_MODE_MAP_DUMB, &map_arg);
void *vaddr = mmap(0, create_arg.size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, map_arg.offset);
三、KMS(Kernel Mode Setting)深度解析
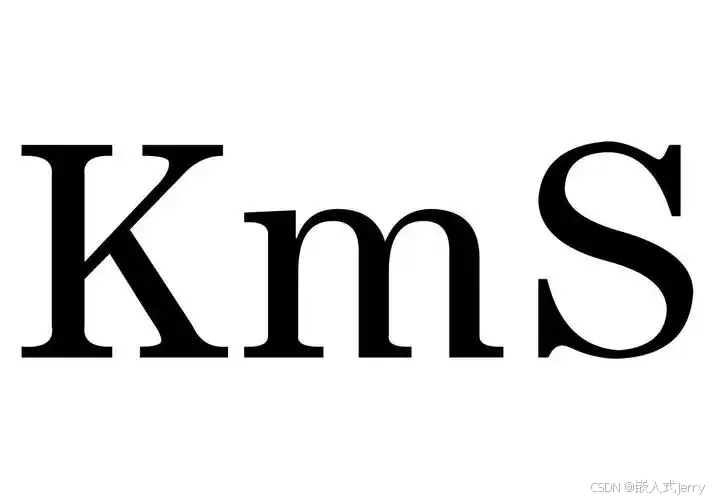
3.1 什么是模式设置(Mode Setting)?
- 核心任务:
- 设置显示器分辨率/刷新率(通过EDID读取显示器参数)
- 配置显示管线(CRTC -> Encoder -> Connector)
3.2 KMS架构图解
+----------------+
| 应用程序 |
+----------------+
|
v
+----------------+
| libdrm/KMS API |
+----------------+
|
v
+----------------+
| 内核DRM驱动 |
+----------------+
|
v
+----------------+
| 显示硬件 |
+----------------+
3.3 KMS关键对象
| 对象 | 作用 | 类比解释 |
|---|---|---|
| CRTC | 显示控制器(扫描输出时序控制) | 类似电影放映机的快门 |
| Encoder | 信号编码器(如HDMI转换器) | 翻译官:数字信号转HDMI |
| Connector | 物理接口(如HDMI端口) | 显示器的物理插口 |
| Plane | 图像层(支持多层合成) | Photoshop中的图层 |
3.4 KMS操作实战:设置显示模式
// 获取所有Connector
drmModeRes *res = drmModeGetResources(fd);
drmModeConnector *conn = drmModeGetConnector(fd, res->connectors[0]);
// 选择第一个有效模式
drmModeModeInfo *mode = &conn->modes[0];
// 创建Frame Buffer
uint32_t fb_id;
drmModeAddFB(fd, mode->hdisplay, mode->vdisplay, 24, 32, stride, create_arg.handle, &fb_id);
// 设置CRTC
drmModeSetCrtc(fd, crtc_id, fb_id, 0, 0, &conn->connector_id, 1, mode);
四、GPU架构核心知识
4.1 GPU vs CPU:设计哲学差异
| 特性 | CPU | GPU |
|---|---|---|
| 核心数量 | 4-64个复杂核心 | 数千个简化核心 |
| 适用场景 | 串行逻辑处理 | 并行数据计算 |
| 内存延迟 | 低延迟 | 高延迟但高带宽 |
4.2 现代GPU架构示例(NVIDIA Ampere)
Graphics Processing Cluster (GPC)
└─ Texture Processing Cluster (TPC)
└─ Streaming Multiprocessor (SM)
├─ CUDA Core × 64
├─ Tensor Core × 4
└─ RT Core × 1
4.3 显存管理:从PCIe到GDDR
- PCIe BAR:CPU通过PCIe空间访问显存
- 显存类型对比:
类型 带宽(GB/s) 典型应用 GDDR6 768 游戏显卡 HBM2 1024 高性能计算卡
五、DRM/KMS高级应用实例
5.1 多显示器配置
// 获取所有Connector
for (int i = 0; i < res->count_connectors; i++) {
drmModeConnector *con = drmModeGetConnector(fd, res->connectors[i]);
if (con->connection == DRM_MODE_CONNECTED) {
// 为每个连接的显示器设置CRTC
drmModeSetCrtc(fd, crtc_ids[i], fb_ids[i], 0, 0, &con->connector_id, 1, &mode);
}
}
5.2 页面翻转(Page Flip)实现无撕裂
void page_flip_handler(int fd, unsigned int frame, unsigned int sec, unsigned int usec, void *data) {
// 翻转完成回调
}
// 发起异步翻转
drmModePageFlip(fd, crtc_id, new_fb_id, DRM_MODE_PAGE_FLIP_EVENT, data);
六、面试题精讲
6.1 基础概念题
Q1: DRM和传统的fbdev有什么区别?
- fbdev:仅支持简单帧缓冲,无GPU加速
- DRM:支持3D加速、多图层合成、原子提交
Q2: 解释KMS中的Plane类型
- Primary Plane:主显示层(必须存在)
- Cursor Plane:鼠标光标层(可选)
- Overlay Plane:视频叠加层(硬件加速)
6.2 实战应用题
Q3: 如何检测显示器热插拔事件?
// 使用DRM的IOCTL监听事件
struct pollfd fds = { .fd = fd, .events = POLLIN };
while (1) {
poll(&fds, 1, -1);
drmEventContext ctx = { .version = 2, .page_flip_handler = ... };
drmHandleEvent(fd, &ctx);
}
6.3 深度原理题
Q4: 为什么需要原子提交(Atomic Commit)?
- 传统问题:多个KMS属性设置可能中间状态导致闪烁
- 解决方案:一次性提交所有变更(如分辨率+色彩空间)
七、性能优化技巧
7.1 减少模式设置延迟
- 技巧:预先验证模式是否支持(
drmModeGetConnector) - 工具:
modetest(DRM测试工具)
7.2 显存零拷贝技术
- DMA-BUF:跨设备共享内存
// 导出DMA-BUF文件描述符
struct drm_prime_handle prime_handle = { .handle = buffer_handle, .flags = DRM_CLOEXEC };
ioctl(fd, DRM_IOCTL_PRIME_HANDLE_TO_FD, &prime_handle);
结语:通向图形专家之路
通过本文,您已掌握DRM/KMS的核心机制与GPU架构精髓。建议进一步研究:
- Vulkan显示扩展(VK_KHR_display)
- Wayland协议的DRM后端实现
- Mesa3D开源驱动架构
掌握这些技术,您将成为Linux图形领域的顶尖开发者!
附录:推荐学习资源
- 书籍:《Linux Device Drivers》第三版(DRM章节)
- 代码库:DRM内核源码(drivers/gpu/drm)
- 工具:DRM Debugging Tools(drm_info, drm-tip)

















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









