







1、算法基本思想
K最近邻(k-Nearest Neighbor,KNN)分类算法可以说是最简单的机器学习算法了。它采用测量不同特征值之间的距离方法进行分类。它的思想很简单:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
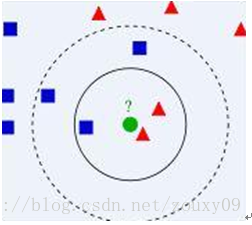
比如上面这个图,我们有两类数据,分别是蓝色方块和红色三角形,他们分布在一个上图的二维中间中。那么假如我们有一个绿色圆圈这个数据,需要判断这个数据是属于蓝色方块这一类,还是与红色三角形同类。怎么做呢?我们先把离这个绿色圆圈最近的几个点找到,因为我们觉得离绿色圆圈最近的才对它的类别有判断的帮助。那到底要用多少个来判断呢?这个个数就是k了。如果k=3,就表示我们选择离绿色圆圈最近的3个点来判断,由于红色三角形所占比例为2/3,所以我们认为绿色圆是和红色三角形同类。如果k=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。从这里可以看到,k的值还是很重要的。
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。因此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分[参考机器学习十大算法]。
总的来说就是我们已经存在了一个带标签的数据库,然后输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似(最近邻)的分类标签。一般来说,只选择样本数据库中前k个最相似的数据。最后,选择k个最相似数据中出现次数最多的分类。其算法描述如下:
1)计算已知类别数据集中的点与当前点之间的距离;
2)按照距离递增次序排序;
3)选取与当前点距离最小的k个点;
4)确定前k个点所在类别的出现频率;
5)返回前k个点出现频率最高的类别作为当前点的预测分类。
2、python代码实现
首先借助sklearn工具包,使用iris数据集进行学习和预测,代码如下:
# -*- coding: utf-8 -*-
"""
Created on Thu Jul 07 18:41:32 2016
@author: irvingzhang
"""
from sklearn import neighbors
from sklearn import datasets
knn = neighbors.KNeighborsClassifier()
iris = datasets.load_iris()
print iris
knn.fit(iris.data,iris.target)
predictedLabel = knn.predict([[0.1,0.2,0.3,0.4]])
print predictedLabel
# -*- coding: utf-8 -*-
"""
Created on Thu Jul 07 21:07:08 2016
@author: irvingzhang
"""
import csv
import random
import math
import operator
#从txt中导入数据
def loadDataset(filename, split, trainingSet=[], testSet=[]):
with open(filename,'rb') as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
if random.random() < split:
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x])
#计算欧氏距离
def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length):
distance += pow(instance1[x] - instance2[x], 2)
return math.sqrt(distance)
#得到最近的k个点
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors
#从最近的k个点中进行投票分类
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.iteritems(),key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0]
#计算对测试集预测的准确度
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet))) * 100.0
#主函数,将knn串联起来
def main():
trainingSet = []
testSet = []
split = 0.67
loadDataset(r'iris.txt', split, trainingSet, testSet)
predictions = []
k = 3
for x in range(len(testSet)):
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print('predicted='+ repr(result) + ',actural=' + repr(testSet[x][-1]))
accuracy = getAccuracy(testSet, predictions)
print('Accuracy:' + repr(accuracy) + '%')
main()
优点:
(1)简单,易于理解,易于实现,无需估计参数,无需训练
(2)适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型)
(3)特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类,kNN比SVM的表现要好
缺点:
(1)懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢
(2)可解释性较差,无法给出决策树那样的规则。
性能:
kNN是一种懒惰算法,平时不好好学习,考试(对测试样本分类)时才临阵磨枪(临时去找k个近邻)。
懒惰的后果:构造模型很简单,但在对测试样本分类地的系统开销大,因为要扫描全部训练样本并计算距离。















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









