









.接上篇进行分析。这篇文章着重分析使用tensorflow构造神经网络进行训练。在阅读本文之前,请确保已经明白上文提到的embedding层的作用。
模型构建
1、初始化权重,embedding层
因为是两个句子,所以定义两个输入input_s1和input_s2,上文说到input_s1的shape是[s_count, sentence_length],代码中的shape=[None, sentence_length]代表sentence_length最大长度为sentence_length,none指这里输入句子个数多少都可以,无论是s_count还是batch_size,然后按照上文的思路,对embedding_w进行embedding_lookup,将[s_count, sentence_length]转化为[s_count, sentence_length, embedding_size]。
self.input_s1 = tf.placeholder(tf.int32, [None, sequence_length], name="input_s1")
self.input_s2 = tf.placeholder(tf.int32, [None, sequence_length], name="input_s2")
self.input_y = tf.placeholder(tf.float32, [None, 1], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
def init_weight(self):
# Embedding layer
with tf.device('/cpu:0'), tf.name_scope("embedding"):
_, self.word_embedding = build_glove_dic()
self.embedding_size = self.word_embedding.shape[1]
self.W = tf.get_variable(name='word_embedding', shape=self.word_embedding.shape, dtype=tf.float32,
initializer=tf.constant_initializer(self.word_embedding), trainable=True)
self.s1 = tf.nn.embedding_lookup(self.W, self.input_s1)
self.s2 = tf.nn.embedding_lookup(self.W, self.input_s2)
self.x = tf.concat([self.s1, self.s2], axis=1)
self.x = tf.expand_dims(self.x, -1)2、通过卷积层,这里直接采用cnn-text-classification-tf中的卷积层。目前处理句子相似度的各类深度学习论文都是在努力的改变模型,以增强句子的表示,因此只要对下面卷积层代码稍作修改,取得更好的效果,就可以水一个论文。因为是重构的代码,所以懒得写卷积层了,直接粘贴了一个文本分类项目的卷积层,训练40000步后能达到71.8%的pearson系数,效果还是很不错的。
def inference(self):
# Create a convolution + maxpool layer for each filter size
pooled_outputs = []
for i, filter_size in enumerate(self.filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, self.embedding_size, 1, self.num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[self.num_filters]), name="b")
conv = tf.nn.conv2d(
self.x,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, self.sequence_length * 2 - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs.append(pooled)
# Combine all the pooled features
self.num_filters_total = self.num_filters * len(self.filter_sizes)
self.h_pool = tf.concat(pooled_outputs, 3)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, self.num_filters_total]3、增加dropout和output层
def add_dropout(self):
# Add dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
def add_output(self):
# Final (unnormalized) scores and predictions
with tf.name_scope("output"):
W = tf.get_variable(
"W",
shape=[self.num_filters_total, self.num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[self.num_classes]), name="b")
self.l2_loss += tf.nn.l2_loss(W)
self.l2_loss += tf.nn.l2_loss(b)
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")4、增加loss和pearson系数。值得注意的是,刚开始仿真的时候,我使用
_, self.pearson = tf.contrib.metrics.streaming_pearson_correlation(self.scores, self.input_y)来计算pearson系数,但是这样计算出来的是连续的pearson系数,即训练到100歩时pearson系数为0.2,那么测试集进行evaluation的时候,会将测试集的pearson系数与训练集前一百个数据的pearson系数进行平均,那么这样evaluation的pearson系数就是不单单是测试集的pearson系数,而是平均之后的结果。所以改为下面代码中的:
def add_loss_acc(self):
# CalculateMean cross-entropy loss
with tf.name_scope("loss"):
losses = tf.square(self.scores - self.input_y)
self.loss = tf.reduce_mean(losses) + self.l2_reg_lambda * self.l2_loss
# Accuracy
with tf.name_scope("pearson"):
mid1 = tf.reduce_mean(self.scores * self.input_y) - \
tf.reduce_mean(self.scores) * tf.reduce_mean(self.input_y)
mid2 = tf.sqrt(tf.reduce_mean(tf.square(self.scores)) - tf.square(tf.reduce_mean(self.scores))) * \
tf.sqrt(tf.reduce_mean(tf.square(self.input_y)) - tf.square(tf.reduce_mean(self.input_y)))
self.pearson = mid1 / mid2模型训练
tensorflow在训练部分都是一些固定的代码,本文直接采用cnn-text-classification-tf训练部分的源码,稍作修改,就可以变为句子相似度的计算代码。其实这就是初学者进阶的步骤,不断地模仿,练习,理解,直到自己可以完整的完成一个项目为止。
with tf.Graph().as_default():
session_conf = tf.ConfigProto(
allow_soft_placement=FLAGS.allow_soft_placement,
log_device_placement=FLAGS.log_device_placement)
sess = tf.Session(config=session_conf)
with sess.as_default():
cnn = TextCNN(
sequence_length=FLAGS.seq_length,
num_classes=FLAGS.num_classes,
filter_sizes=list(map(int, FLAGS.filter_sizes.split(","))),
num_filters=FLAGS.num_filters,
l2_reg_lambda=FLAGS.l2_reg_lambda)
# Define Training procedure
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(1e-3)
grads_and_vars = optimizer.compute_gradients(cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
# Keep track of gradient values and sparsity (optional)
grad_summaries = []
for g, v in grads_and_vars:
if g is not None:
grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g)
sparsity_summary = tf.summary.scalar("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
grad_summaries.append(grad_hist_summary)
grad_summaries.append(sparsity_summary)
grad_summaries_merged = tf.summary.merge(grad_summaries)
# Output directory for models and summaries
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
# Summaries for loss and pearson
loss_summary = tf.summary.scalar("loss", cnn.loss)
acc_summary = tf.summary.scalar("pearson", cnn.pearson)
# Train Summaries
train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph)
# Dev summaries
dev_summary_op = tf.summary.merge([loss_summary, acc_summary])
dev_summary_dir = os.path.join(out_dir, "summaries", "dev")
dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, sess.graph)
# Checkpoint directory. Tensorflow assumes this directory already exists so we need to create it
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=FLAGS.num_checkpoints)
# Initialize all variables
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
def train_step(s1, s2, score):
"""
A single training step
"""
feed_dict = {
cnn.input_s1: s1,
cnn.input_s2: s2,
cnn.input_y: score,
cnn.dropout_keep_prob: FLAGS.dropout_keep_prob
}
_, step, summaries, loss, pearson = sess.run(
[train_op, global_step, train_summary_op, cnn.loss, cnn.pearson],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, pearson {:g}".format(time_str, step, loss, pearson))
train_summary_writer.add_summary(summaries, step)
def dev_step(s1, s2, score, writer=None):
"""
Evaluates model on a dev set
"""
feed_dict = {
cnn.input_s1: s1,
cnn.input_s2: s2,
cnn.input_y: score,
cnn.dropout_keep_prob: 1.0
}
step, summaries, loss, pearson = sess.run(
[global_step, dev_summary_op, cnn.loss, cnn.pearson],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, pearson))
if writer:
writer.add_summary(summaries, step)
# Generate batches
STS_train = data_helper.dataset(s1=s1_train, s2=s2_train, label=score_train)
# Training loop. For each batch...
for i in range(40000):
batch_train = STS_train.next_batch(FLAGS.batch_size)
train_step(batch_train[0], batch_train[1], batch_train[2])
current_step = tf.train.global_step(sess, global_step)
if current_step % FLAGS.evaluate_every == 0:
print("\nEvaluation:")
dev_step(s1_dev, s2_dev, score_dev, writer=dev_summary_writer)
print("")
if current_step % FLAGS.checkpoint_every == 0:
path = saver.save(sess, checkpoint_prefix, global_step=current_step)
print("Saved model checkpoint to {}\n".format(path))训练结果
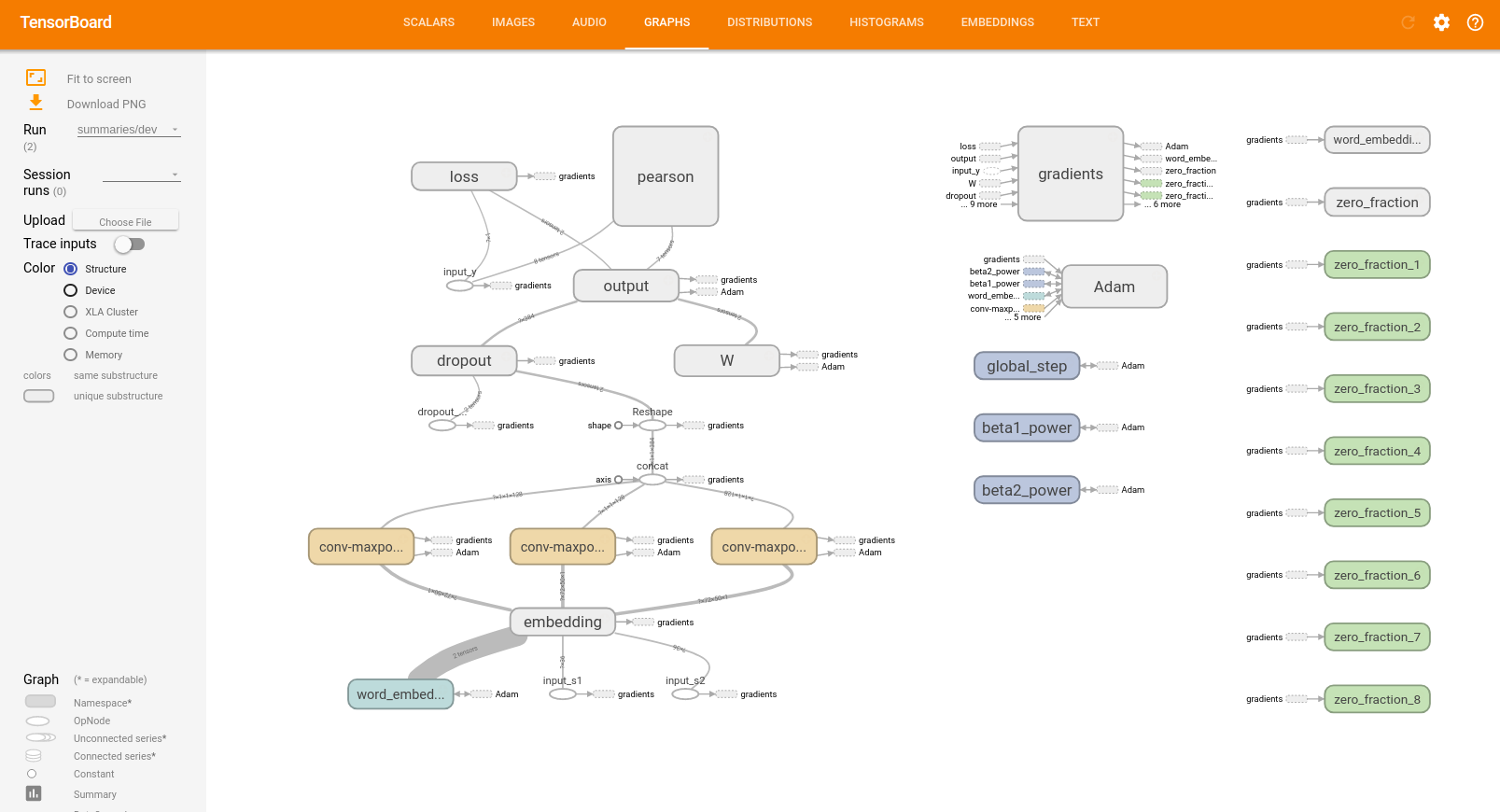
训练的graph
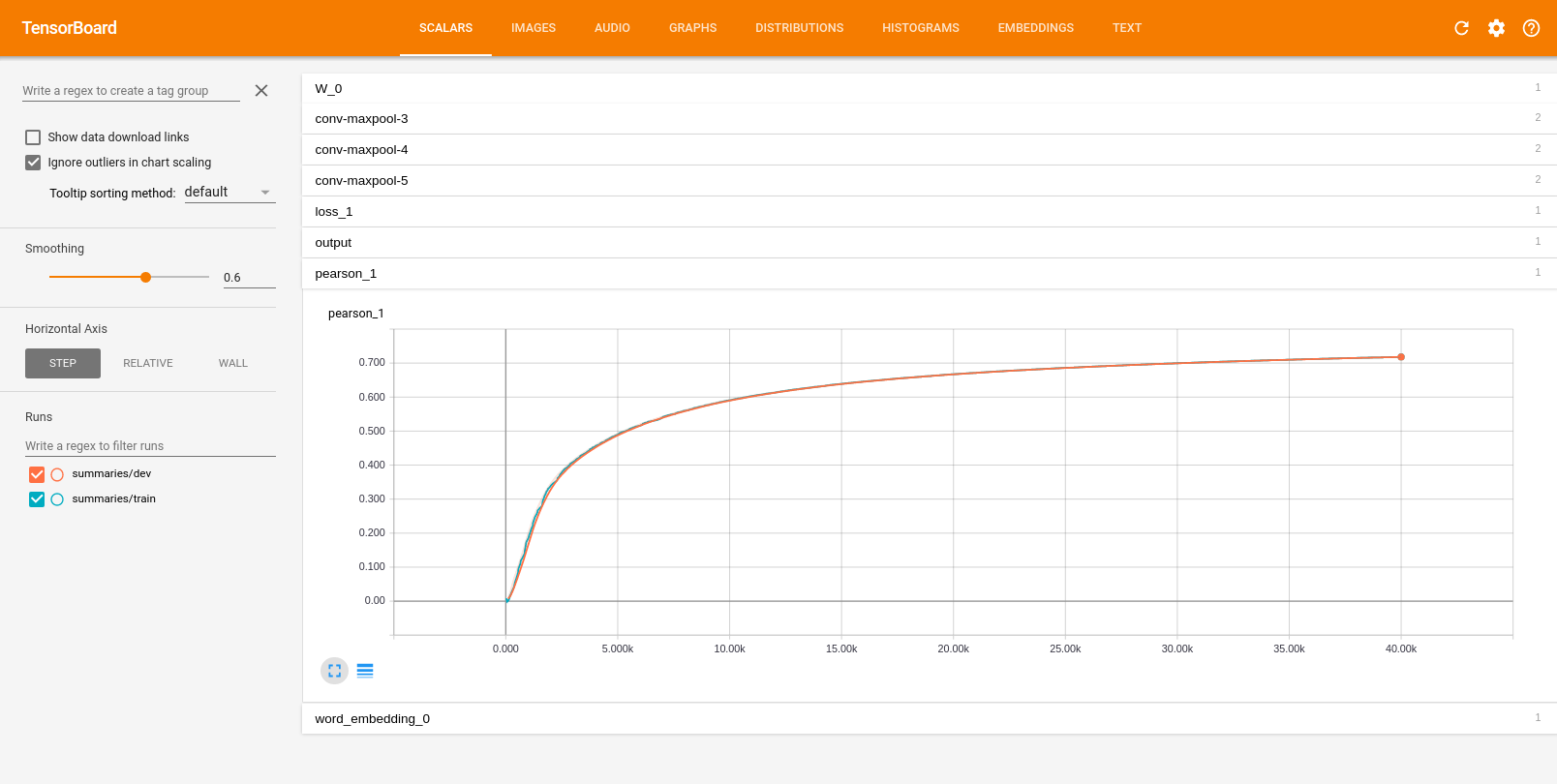
训练的pearson系数















 4014
4014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









