







流是一个抽象的概念
当Java程序需要从数据源读取数据时,会开启一个到数据源的流。数据源可以是文件,内存或者网络等。同样,当程序需要输出数据到目的地时也一样会开启一个流,数据目的地也可以是文件、内存或者网络等。流的创建是为了更方便地处理数据的输入输出。
流是同步的
也就是说,当程序(确切的将是线程)请求一个流读/写一段数据时,在做任何其他操作前,它要等待读/写的数据。Java还支持使用通道和缓冲区的非阻塞I/O。
参考博文:NIO究竟是什么?
流主要有字节流和字符流
字节流也称为原始数据,需要用户读入后进行相应的编码转换。而字符流的实现是基于自动转换的,读取数据时会把数据按照JVM的默认编码自动转换成字符。
字节流由InputStream和OutputStream处理,而字符流由Reader和Writer处理。
Reader和Writer是Java后加入的处理类,出于让数据的处理更方便的目的。
【1】Java IO原理

图示输入输出流:

【2】流的分类
按照数据流向的不同:输入流(写) 输出流(读)。
按照处理数据的单位的不同:字节流(8bit) 字符流(16 bit-处理的文本文件)。
按照角色的不同:节点流(直接作用于文件的) 处理流(构造函数为流)。

添加处理流:

【3】IO流体系

【4】节点流和处理流
节点流可以从一个特定的数据源读写数据

处理流是“连接”在已存在的流(节点流或处理流)之上,通过对数据的处理为程序提供更为强大的读写功能。


对开发人员来说,使用处理流进行输入/输出操作更简单;使用处理流的执行效率更高。
处理流的构造器的参数不是一个物理节点,而是已经存在的流。而节点流都是直接以物理IO及节点作为构造器参数的。
【5】输入流基类-抽象基类,不能实例化
InputStream 和 Reader 是所有输入流的基类
InputStream(典型实现:FileInputStream)
int read()
# 读取单个字节
int read(byte[] b)
# 调用流对象的读取方法将流中的数据读入到数组中
int read(byte[] b, int off, int len)
Reader(典型实现:FileReader)
int read()
# 读取单个字符
int read(char [] c)
# 调用流对象的读取方法将流中的数据读入到数组中
int read(char [] c, int off, int len)
程序中打开的文件 IO 资源不属于内存里的资源,垃圾回收机制无法回收该资源,所以应该显式关闭文件 IO 资源。
InpuStream的基本方法是没有参数的read()。这个方法从输入源的流中读取1字节数据,作为一个0-255的int返回。流的结束通过返回-1来表示。read()方法会等待并阻塞其后任何代码的执行。
byte[] input = new byte[10];
for(int i=0;i<input.length;i++){
int b = in.read();
if(b==-1) break;
input[i]=(byte)b;
}
虽然read()只读取一个字节,但是会返回一个int,这样在把结果存储到字节数组前就必须进行类型转换。可能会产生一个-128-127的有符号字节而不是read()方法返回的0-255之间的一个无符号字节。
不过可以使用下面方法进行转换:
int i=b>0?b:256+b;
单字节读取太慢,可以使用重载方法二三。
InputStream类还有3个不太常用的方法,允许程序备份和重新读取已经读取的数据。
public void mark(int readAheadLimit);
public void reset()throw IOException;
public boolean markSupported();
//告知是否支持标记和重置
为了重新读取数据,要用mark方法标记流的当前位置。在以后某个时刻,可以用reset方法把流重置到之前标记的位置。接下来的读取操作会返回从标记位置开始的数据。
不过需要注意的是,不能随心所欲向前重置任意字节的位置。从标记处读取和重置的字节数由mark的readAheadLimit参数确定。如果试图重置的太远,就会抛出IOException异常。除此之外,一个流在任何时刻都只能有一个标记,标记第二个位置会清除第一个标记。
java.io中仅有的两个始终支持标记的输入流类是BufferedInputStream和ByteArrayInputStream。而其他流(如TelnetInputStream)如果先串链到缓冲的输入流时才支持标记。
比较特殊的是Reader类有一个ready()方法,它与InputStream类的avaliable()用途相同。但语义却不尽相同,尽管都涉及到字节到字符转换。
avaliable返回一个int,指定可以无阻塞地最少读取多少个字节,但ready只返回一个boolean,指示阅读器是否可以无阻塞地读取。
【6】输出流基类-抽象基类,不能实例化
OutputStream 和 Writer 也非常相似:
void write(int b/int c);
void write(byte[] b/char[] cbuf);
void write(byte[] b/char[] buff, int off, int len);
void flush();
void close(); 需要先刷新,再关闭此流
因为字符流直接以字符作为操作单位,所以 Writer 可以用字符串来替换字符数组,即以 String 对象作为参数
void write(String str);
void write(String str, int off, int len);
OutoutStream的基本方法是write(int b),这个方法接受一个0-255之间的整数作为参数,将对应的字节写入到流中。
需要注意的是 ,虽然该方法接受一个int作为参数,但它实际上会写入一个无符号字节。Java没有无符号字节数据类型,故用int代替。
无符号字节和有符号字节唯一的区别在于它们都有8个二进制位组成。当使用write(int b)将int写入一个网络连接时,线缆上只会放8个二进制位。如果参数超过0-255,将写入这个数的最低字节,其他3字节忽略(将int强制转换为了byte)。
flush()方法可以强迫缓冲的流发送数据,即使缓冲区还没有填满。不管是否有必要,刷新输出流都很重要。你可能知道某种流是缓冲,也可能不知道(System.out会缓冲)。
当结束一个流的操作时,通过调用close()方法来关闭。这会释放与这个流关联的所有资源,如文件句柄或端口占用;如果该流来自网络连接,那么关闭这个流也会关闭连接。
【7】处理流-缓冲流
为了提高数据读写的速度,Java API提供了带缓冲功能的流类,在使用这些流类时,会创建一个内部缓冲区数组。
根据数据操作单位可以把缓冲流分为:
BufferedInputStream 和 BufferedOutputStream
BufferedReader 和 BufferedWriter
缓冲流要“套接”在相应的节点流之上,对读写的数据提供了缓冲的功能,提高了读写的效率,同时增加了一些新的方法。
对于输出的缓冲流,写出的数据会先在内存中缓存,使用flush()将会使内存中的数据立刻写出。
BufferedOutputStream类将写入的数据存储在缓冲区(一个名为buf的保护字节数组字段),直到缓冲区满或刷新缓冲区,然后它将数据一次写入底层输出流。
BufferedInputStream类也有一个作为缓冲区的保护字节数组,名为buf。当调用某个流的read方法时,它首先尝试从缓冲区读取数据。只有当缓冲区没有数据时,流才从底层的源中读取数据。这时它会从底层的源中读取尽可能多的数据进入缓冲区,而不管它是否马上需要这些数据。
默认情况下,输入流的缓冲区大小为2048字节,输出流的缓冲区大小为512字节。
BufferedReader和BufferedWriter类是基于字符的,对应于上述的字节缓冲流。字节缓冲流使用一个内部字节数组作为缓冲区,字符缓冲流使用一个内部字符数组作为缓冲区。
默认情况下,字符缓冲流的缓冲区大小为8192字符。
【8】处理流-转换流
转换流提供了在字节流和字符流之间的转换。
Java API提供了两个转换流:
InputStreamReader和OutputStreamWriter
字节流中的数据都是字符时,转成字符流操作更高效。
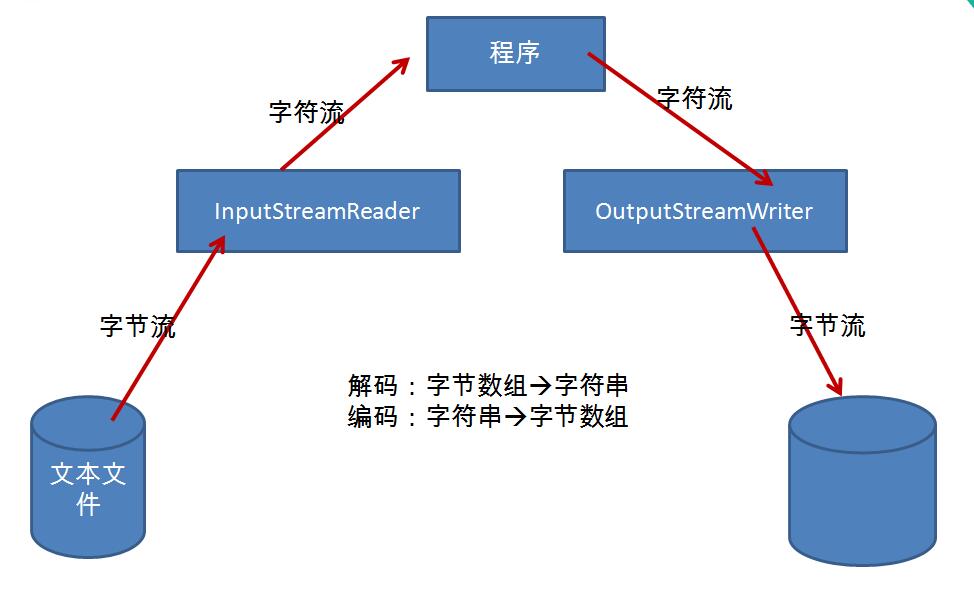
InputStreamReader
用于将字节流中读取到的字节按指定字符集解码成字符。需要和InputStream“套接”。
构造方法
public InputStreamReader(InputStream in)
public InputSreamReader(InputStream in,String charsetName)
实例如下:
Reader isr = new InputStreamReader(System.in,”UTF-8”);
OutputStreamWriter
用于将要写入到字节流中的字符按指定字符集编码成字节。需要和OutputStream“套接”。
构造方法:
public OutputStreamWriter(OutputStream out)
public OutputSreamWriter(OutputStream out,String charsetName)
综合实例如下:
public void testMyInput() throws Exception{
FileInputStream fis = new FileInputStream("dbcp.txt");
FileOutputStream fos = new FileOutputStream("dbcp5.txt");
InputStreamReader isr = new InputStreamReader(fis,"GBK");
OutputStreamWriter osw = new OutputStreamWriter(fos,"GBK");
BufferedReader br = new BufferedReader(isr);
BufferedWriter bw = new BufferedWriter(osw);
String str = null;
while((str = br.readLine()) != null){
bw.write(str);
bw.newLine();
bw.flush();
}
bw.close();
br.close();
}
InputStreamReader类包含一个底层输入流,可以从中读取原始字节。它根据指定的编码方式,将这些字节转换为Unicode字符。
OutputStreamWriter从运行的程序中接受Unicode字符,并使用指定的编码方式讲这些字符转换为字节,然后发送到底层输出流。
如果OutputStreamWriter(InputStreamReader)没有指定编码方式,就使用平台默认的编码方式。这是很糟糕的,所以尽可能地指定编码方式(UTF-8)。
字符编码:
计算机只能识别二进制数据,早期由来是电信号。为了方便应用计算机,让它可以识别各个国家的文字。就将各个国家的文字用数字来表示,并一一对应,形成一张表。这就是编码表。
常见的编码表
ASCII:美国标准信息交换码。
用一个字节的7位可以表示。
ISO8859-1:拉丁码表。欧洲码表
用一个字节的8位表示。
GB2312:中国的中文编码表。
GBK:中国的中文编码表升级,融合了更多的中文文字符号。
Unicode:国际标准码,融合了多种文字。
所有文字都用两个字节来表示,Java语言使用的就是unicode
UTF-8:最多用三个字节来表示一个字符。
GBK:
一个英文字母一个字节;一个英文符号一个字节;一个空格一个字节;一个中文两个字节;一个中文标点两个字节。
UTF-8:
一个中文三个字节;一个中文标点三个字节;一个空格一个字节;一个英文字母一个字节;一个英文标点一个字节。
编码:字符串—>字节数组
解码:字节数组—>字符串
转换流的编码应用
可以将字符按指定编码格式存储。
可以对文本数据按指定编码格式来解读。
指定编码表的动作由构造器完成。
【9】处理流-标准输入输出流
System.in和System.out分别代表了系统标准的输入和输出设备。
默认输入设备是键盘,输出设备是显示器
System.in的类型是抽象类InputStream,System.out的类型是PrintStream–其是OutputStream的子类FilterOutputStream 的子类。
PrintStream继承示意图如下:

通过System类的setIn,setOut方法对默认设备进行改变。
public static void setIn(InputStream in)
public static void setOut(PrintStream out)
# 获取键盘输入
Scanner s = new Scanner(System.in);
s.nextInt();
s.next();
【10】处理流-打印流
在整个IO包中,打印流是输出信息最方便的类。PrintStream(字节打印流)和PrintWriter(字符打印流)提供了一系列重载的print和println方法,用于多种数据类型的输出。
- PrintStream和PrintWriter的输出不会抛出异常
- PrintStream和PrintWriter有自动flush功能
- System.out返回的是PrintStream的实例
PrintStream.print(String s)方法如下
/**
1.打印一个字符串,如果是null则打印字符串null;
2.否则将字符串以平台默认编码转为字节并调用write方法
3.write方法会使用默认输出打印
*/
public void print(String s) {
if (s == null) {
s = "null";
}
write(s);
}
//write方法如下
private void write(String s) {
try {
synchronized (this) {
ensureOpen();
textOut.write(s);
textOut.flushBuffer();
charOut.flushBuffer();
if (autoFlush && (s.indexOf('\n') >= 0))
out.flush();
}
}
catch (InterruptedIOException x) {
Thread.currentThread().interrupt();
}
catch (IOException x) {
trouble = true;
}
}
PrintStream的每个print()方法都将参数以默认的编码方式写入底层的输出流。println()方法也能完成相同的操作,但会在所写的行末尾追加一个与平台有关的行分隔符。在unix下是换行符\n,在Mac OS 9下是回车符\r,在windows下是回车/换行对(\r\n)。
PrintStream.println(String x)方法如下
//实际上该方法是两个方法拼接
public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}
另外PrintStream吞掉了所有的异常。综上,除了调试查看信息打印到控制台外,谨慎使用打印流。
PrintWriter类用于取代PrintStream,它能正确处理多字节字符集和国际化文本。如果使用打印流,请尽可能使用PrintWriter而非PrintStream。虽然它也存在困扰PrintStream类的平台依赖性和错误报告信息量小的问题。
从响应中获取打印流并打印信息
//设置编码,否则会乱码
response.setHeader("content-type", "text/html;charset=UTF-8");
//字符打印流
PrintWriter outWrite = null;
JSONObject info = new JSONObject();
info.put("FLAG", SystemConstant.SYS_FAIL_MESSAGE);
info.put("CODE", SystemConstant.CODE_CALL_METHOD);
info.put("MESSAGE","导出数据不能大于20000 条!");
outWrite=response.getWriter();
outWrite.print(info.toJSONString());
【11】处理流-数据流
为了方便地操作Java语言的基本数据类型的数,可以使用数据流。
数据流有两个类,分别用于读取和写出基本数据类型的数据。
DataInputStream和DataOutputStream,分别套接在InputStream和OutputStream节点流上。
DataInputStream中的方法如下:

对比下图,没有readChars和readBytes方法,需要进行单字符或字节读取。
比较特殊的时DataInputStream提供了两个方法可以读取无符号字节和无符号短整数,并返回等价的int。
public final int readUnsignedByte();
public final int readUnsignedShort();
readFully两个重载方法可以重复地从底层输入流向一个数组读取数据,直到读取了所请求的字节数为止。如果不能读取到足够的数据,就会抛出IOException异常。
另外,如上图可知,readLine方法被废弃。该方法读取用行结束符分割的一行文本,并返回一个字符串。之所以将该方法废弃,是因为大多数情况下它并不能正确地将非ASCII字符转换为字节。这个任务现在由BufferedReader类的readLine()方法替代。
不过这两个方法都有一个隐藏的bug:它们并不总能把一个回车识别为行结束。实际上readLine只能识别换行或回车/换行对。该问题在读取文件时不明显,在网络连接中影响比较大。

DataOutputStream中的方法如下:

需要说明的时writeChars()方法只是对String参数迭代(循环)处理,将各个字符按照顺序写为一个2字节的big-endian Unicode字符(确切地将是UTF-16码点)。
writeBytes()方法迭代处理String参数,但只写入每个字符的低字节。因此如果字符串中含有Lantin-1字符集之外的字符信息,将会丢失。故而,谨慎使用。

代码测试如下:
DataOutputStream dos = null;
try { //创建连接到指定文件的数据输出流对象
dos = new DataOutputStream(new FileOutputStream(
"d:\\IOTest\\destData.dat"));
dos.writeUTF("ab中国"); //写UTF字符串
dos.writeBoolean(false); //写入布尔值
dos.writeLong(1234567890L); //写入长整数
System.out.println("写文件成功!");
} catch (IOException e) {
e.printStackTrace();
} finally { //关闭流对象
try {
if (dos != null) {
// 关闭过滤流时,会自动关闭它包装的底层节点流
dos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
【12】处理流-对象流
详情请看:对象序列化
ObjectInputStream和OjbectOutputSteam
用于存储和读取对象的处理流。它的强大之处就是可以把Java中的对象写入到数据源中,也能把对象从数据源中还原回来。
序列化(Serialize):用ObjectOutputStream类将一个Java对象写入IO流中。
反序列化(Deserialize):用ObjectInputStream类从IO流中恢复该Java对象。
ObjectOutputStream和ObjectInputStream不能序列化static和transient修饰的成员变量。
对象的序列化
对象序列化机制允许把内存中的Java对象转换成平台无关的二进制流,从而允许把这种二进制流持久地保存在磁盘上,或通过网络将这种二进制流传输到另一个网络节点。当其它程序获取了这种二进制流,就可以恢复成原来的Java对象。
序列化的好处在于可将任何实现了Serializable接口的对象转化为字节数据,使其在保存和传输时可被还原。
序列化是 RMI(Remote Method Invoke – 远程方法调用)过程的参数和返回值都必须实现的机制,而 RMI 是 JavaEE 的基础。因此序列化机制是 JavaEE 平台的基础。
如果需要让某个对象支持序列化机制,则必须让其类是可序列化的,为了让某个类是可序列化的,该类必须实现如下两个接口之一:
Serializable
Externalizable
凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量:
private static final long serialVersionUID;
serialVersionUID用来表明类的不同版本间的兼容性。
如果类没有显示定义这个静态变量,它的值是Java运行时环境根据类的内部细节自动生成的。若类的源代码作了修改,serialVersionUID 可能发生变化。故建议,显示声明。
显示定义serialVersionUID的用途
希望类的不同版本对序列化兼容,因此需确保类的不同版本具有相同的serialVersionUID。
不希望类的不同版本对序列化兼容,因此需确保类的不同版本具有不同的serialVersionUID。
使用对象流序列化对象
若某个类实现了 Serializable 接口,该类的对象就是可序列化的:
创建一个 ObjectOutputStream
调用 ObjectOutputStream 对象的 writeObject(对象) 方法输出可序列化对象
# 注意写出一次,操作flush()
反序列化
创建一个 ObjectInputStream
调用 readObject() 方法读取流中的对象
强调:如果某个类的字段不是基本数据类型或 String 类型,而是另一个引用类型,那么这个引用类型必须是可序列化的,否则拥有该类型的 Field 的类也不能序列化。
实例代码如下:
#序列化:将对象写入到磁盘或者进行网络传输。
#要求对象必须实现序列化
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("test3.txt"));
Person p = new Person("韩梅梅",18,"中华大街",new Pet());
oos.writeObject(p);
oos.flush();
oos.close();
//反序列化:将磁盘中的对象数据源读出。
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("test3.txt"));
Person p1 = (Person)ois.readObject();
System.out.println(p1.toString());
ois.close();
【13】流-小结
流是用来处理数据的。
处理数据时,一定要先明确数据源,与数据目的地。数据源可以是文件,可以是键盘。数据目的地可以是文件、显示器或者其他设备。
而流只是在帮助数据进行传输,并对传输的数据进行处理,比如过滤处理、转换处理等。
字节流-缓冲流
输入流InputStream-FileInputStream-BufferedInputStream
输出流OutputStream-FileOutputStream-BufferedOutputStream
字符流-缓冲流
输入流Reader-FileReader-BufferedReader
输出流Writer-FileWriter-BufferedWriter
转换流
InputSteamReader和OutputStreamWriter
对象流
ObjectInputStream和ObjectOutputStream
//序列化
//反序列化
随机存取流RandomAccessFile(掌握读取、写入)。
什么是java序列化,如何实现java序列化?
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。
可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。
序列化是为了解决在对对象流进行读写操作时所引发的问题。
序列化的实现:将需要被序列化的类实现Serializable接口,该接口没有需要实现的方法,implements Serializable只是为了标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream对象的writeObject(Object obj)方法就可以
将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流。
















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











