







💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。
推荐:Linux运维老纪的首页,持续学习,不断总结,共同进步,活到老学到老
导航剑指大厂系列:全面总结 运维核心技术:系统基础、数据库、网路技术、系统安全、自动化运维、容器技术、监控工具、脚本编程、云服务等。
常用运维工具系列:常用的运维开发工具, zabbix、nagios、docker、k8s、puppet、ansible等
数据库系列:详细总结了常用数据库 mysql、Redis、MongoDB、oracle 技术点,以及工作中遇到的 mysql 问题等
懒人运维系列:总结好用的命令,解放双手不香吗?能用一个命令完成绝不用两个操作
数据结构与算法系列:总结数据结构和算法,不同类型针对性训练,提升编程思维,剑指大厂
非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。💝💝💝 ✨✨ 欢迎订阅本专栏 ✨✨
Apache Hudi性能提升三倍的查询优化
这篇文章主要为大家介绍了Apache Hudi性能提升三倍的查询优化,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步早日升职加薪
从 Hudi 0.10.0版本开始,我们很高兴推出在数据库领域中称为 Z-Order 和 Hilbert 空间填充曲线的高级数据布局优化技术的支持。
1. 背景
Amazon EMR 团队最近发表了一篇很不错的文章展示了对数据进行聚簇是如何提高查询性能的,为了更好地了解发生了什么以及它与空间填充曲线的关系,让我们仔细研究该文章的设置。
文章中比较了 2 个 Apache Hudi 表(均来自 Amazon Reviews 数据集):
未聚簇的 amazon_reviews 表(即数据尚未按任何特定键重新排序)
amazon_reviews_clustered 聚簇表。当数据被聚簇后,数据按字典顺序排列(这里我们将这种排序称为线性排序),排序列为star_rating、total_votes两列(见下图)

为了展示查询性能的改进,对这两个表执行以下查询:


这里要指出的重要考虑因素是查询指定了排序的两个列(star_rating 和 total_votes)。但不幸的是这是线性/词典排序的一个关键限制,如果添加更多列,排序的价值会会随之减少。
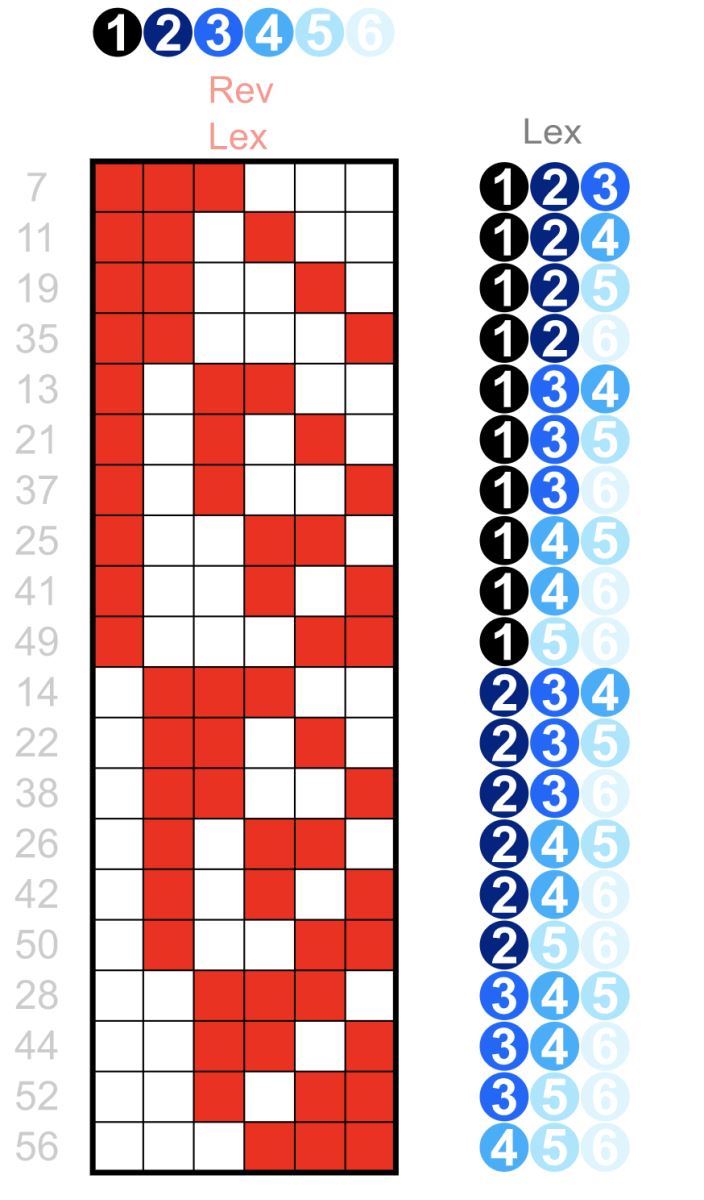
从上图可以看到,对于按字典顺序排列的 3 元组整数,只有第一列能够对所有具有相同值的记录具有关键的局部性属性:例如所有记录都具有以“开头的值” 1"、"2"、"3"(在第一列中)很好地聚簇在一起。但是如果尝试在第三列中查找所有值为"5"的值,会发现这些值现在分散在所有地方,根本没有局部性,过滤效果很差。
提高查询性能的关键因素是局部性:它使查询能够显着减少搜索空间和需要扫描、解析等的文件数量。
但是这是否意味着如果我们按表排序的列的第一个(或更准确地说是前缀)以外的任何内容进行过滤,我们的查询就注定要进行全面扫描?不完全是,局部性也是空间填充曲线在枚举多维空间时启用的属性(我们表中的记录可以表示为 N 维空间中的点,其中 N 是我们表中的列数)
那么它是如何工作的?我们以 Z 曲线为例:拟合二维平面的 Z 阶曲线如下所示:
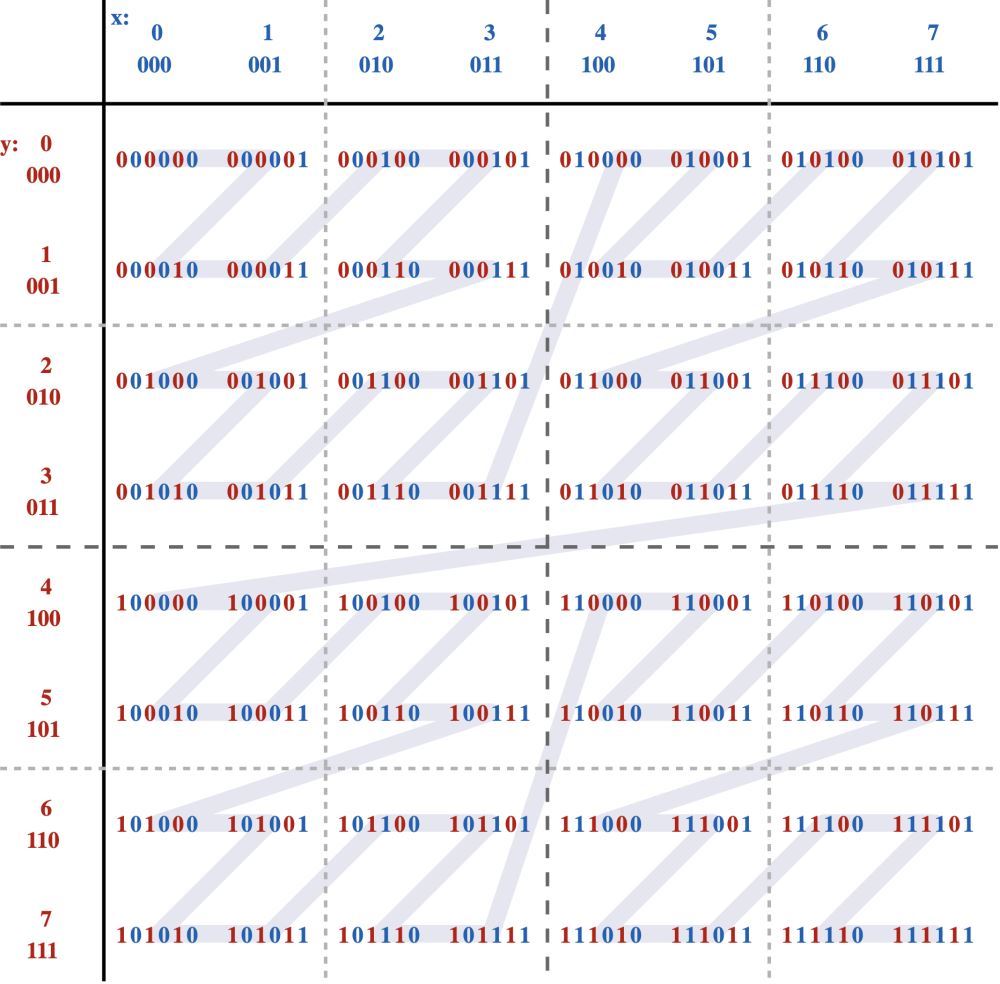
可以看到按照路径,不是简单地先按一个坐标 ("x") 排序,然后再按另一个坐标排序,它实际上是在对它们进行排序,就好像这些坐标的位已交织成单个值一样:
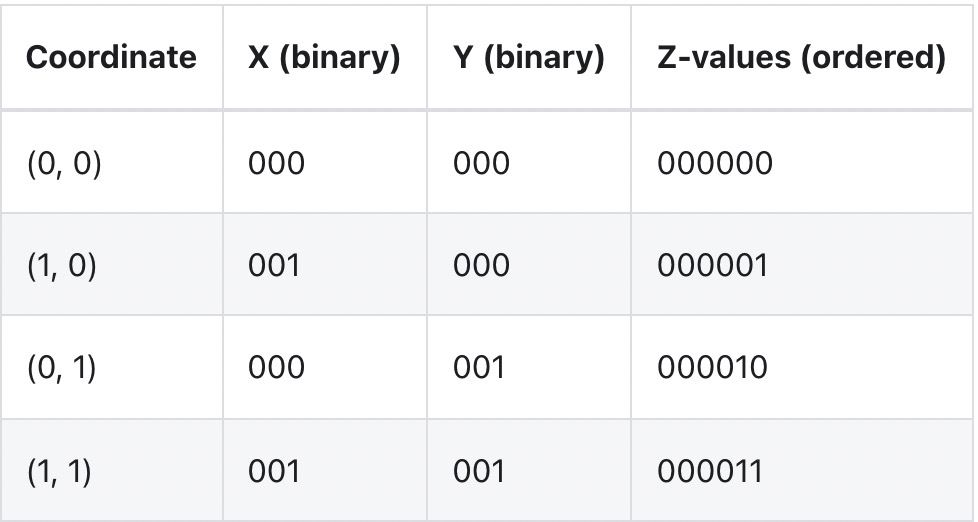
在线性排序的情况下局部性仅使用第一列相比,该方法的局部性使用到所有列。
以类似的方式,希尔伯特曲线允许将 N 维空间中的点(我们表中的行)映射到一维曲线上,基本上对它们进行排序,同时仍然保留局部性的关键属性,在此处阅读有关希尔伯特曲线的更多详细信息,到目前为止我们的实验表明,使用希尔伯特曲线对数据进行排序会有更好的聚簇和性能结果。
现在让我们来看看它的实际效果!
2. 设置
我们将再次使用 Amazon Reviews 数据集,但这次我们将使用 Hudi 按 product_id、customer_id 列元组进行 Z-Order排序,而不是聚簇或线性排序。
数据集不需要特别的准备,可以直接从 S3 中以 Parquet 格式下载并将其直接用作 Spark 将其摄取到 Hudi 表。
启动spark-shell
导入Hudi表
3. 测试
每个单独的测试请在单独的 spark-shell 中运行,以避免缓存影响测试结果。
4. 结果
我们总结了以下的测试结果

可以看到多列线性排序对于按列(Q2、Q3)以外的列进行过滤的查询不是很有效,这与空间填充曲线(Z-order 和 Hilbert)形成了非常明显的对比,后者将查询时间加快多达 3倍 。值得注意的是性能提升在很大程度上取决于基础数据和查询,在我们内部数据的基准测试中,能够实现超过 11倍 的查询性能改进!
5. 总结
Apache Hudi v0.10 为开源带来了新的布局优化功能 Z-order 和 Hilbert。 使用这些行业领先的布局优化技术可以为用户查询带来显着的性能提升和成本节约!

















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











