







 本文介绍了在Hive+Spark离线数仓工业项目中,如何使用Prometheus监控服务器性能,包括Prometheus的功能、特点、架构和部署,以及集成node_exporter和mysqld_exporter插件。同时,文章还详细讲解了Grafana的部署和集成Prometheus进行可视化监控。
本文介绍了在Hive+Spark离线数仓工业项目中,如何使用Prometheus监控服务器性能,包括Prometheus的功能、特点、架构和部署,以及集成node_exporter和mysqld_exporter插件。同时,文章还详细讲解了Grafana的部署和集成Prometheus进行可视化监控。
监控需求及常见工具
目标:了解服务器性能监控需求及常见监控工具
路径
- step1:监控需求
- step2:常见工具
实施
监控需求
- 问题:数据量越来越大,机器数量越来越多,如何保证所有服务器稳定的的运行,确保所有业务不掉线?
- 资源:CPU、内存、磁盘、网络
- 阈值:80%
- 解决:高效的监控系统可以对运维数据进行分析整理,将运维工作透明化可视化,方便运维人员及时找出问题,保障系统稳定运行,提高运维效率,满足不同业务需求,适用不同服务器场景,也是决定运维成本和效率的重要因素
- 需求
覆盖式监控:监控所有机器、所有服务的运行
统一监控内容:CPU、内存、磁盘、网络IO
分离告警和显示:实时的监控机器负载,程序运行,并针对不同业务实现不同方式的告警和报表
常见工具
zabbix
基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案
zabbix能监视各种网络参数,保证服务器系统的安全运营
提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题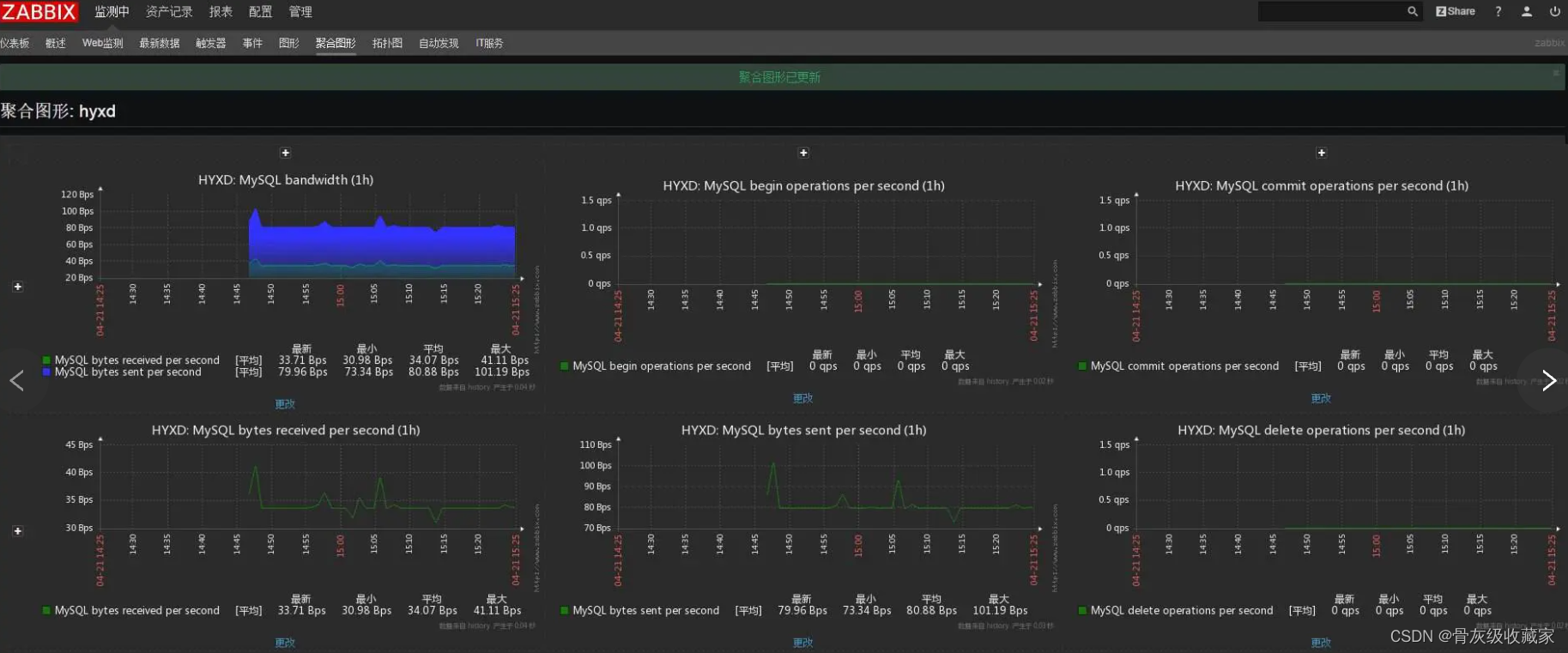
Nagios
一款开源的免费网络监视工具,能有效监控Windows、Linux和Unix的状态,交换机路由器等网络设备,打印机等
在系统或服务状态异常时发出邮件或短信报警第一时间通知网站运维人员,在状态恢复后发出正常的邮件或短信通知
Prometheus
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB),它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。
2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。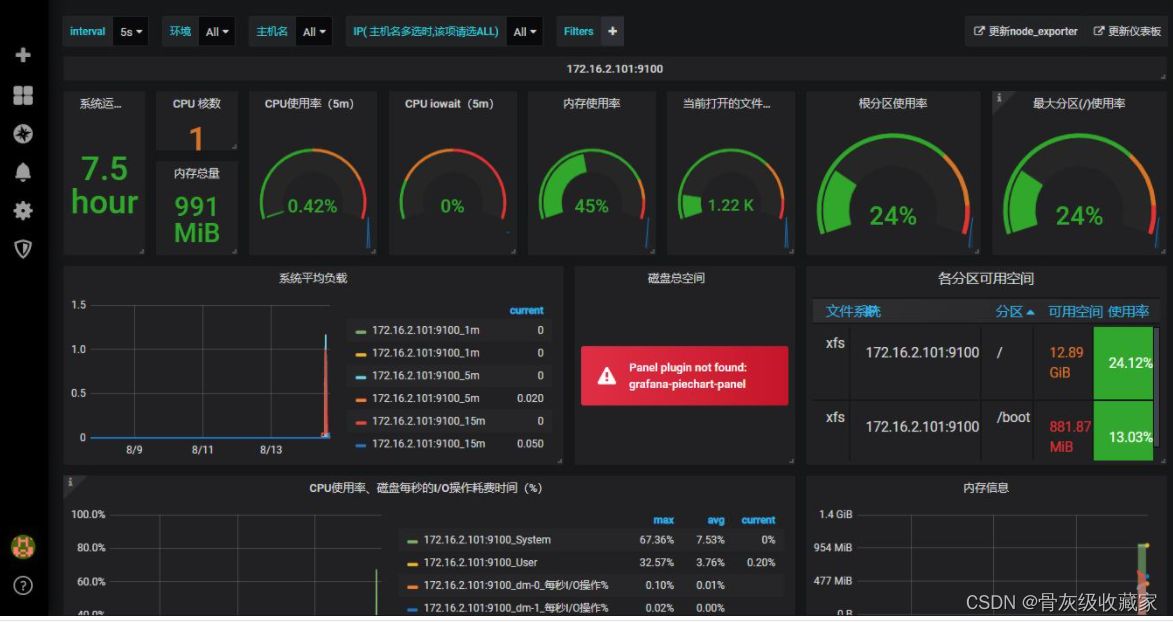
Prometheus的介绍
目标:了解Prometheus的功能和特点
路径
- step1:功能
- step2:特点
实施
- https://prometheus.io/
- 功能:服务器性能指标监控及时序数据存储
- Prometheus实现了高纬度数据模型,时间序列数据由指标名称和键值对指标组成。
- PromQL允许对收集的时间序列数据进行切片和切块,生成ad-hoc图形、图表、告警
- Prometheus有多种数据可视化模式:内置表达式浏览器,grafana集成、控制台模板语言
- Prometheus使用有效的自定义格式将时间序列数据存储在内存中和本地磁盘,通过函数式分片和联邦进行弹性扩展。
- 每个服务器都是独立的,仅依赖于本地存储。用go语言编写,所有二进制文件都是静态链接,易于部署。
- 告警是基于PromQL灵活定义的,并保留维度信息,告警管理器控制告警信息的通知与否。
- 特点
- 多维度数据模型。
- 灵活的查询语言。
- 不依赖分布式存储,单个服务器节点是自主的。
- 通过基于HTTP的pull方式采
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1875
1875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









