







1 INTRODUCTION
基于人工神经网络的深度学习的最新进展见证了语音识别[1],图像识别[2],药物发现[3]和癌症研究的基因分析[4],[5]等各种任务的前所未有的准确性。为了获得更高的准确性,必须将大量数据馈入深度学习模型,从而导致过高的计算开销[6],[7]。但是,可以通过采用近年来已广泛研究的分布式深度学习技术来解决此问题。不幸的是,与传统的独立深度学习方案相比,在分布式深度学习的情况下,隐私问题更加恶化。
因此,保护隐私的深度学习应运而生,以解决深度学习中的隐私问题,并且在过去几年中出现了各种模型[8],[9],[10],[11],[12],[13] ,[14],[15],[16]。在这些现有工作中,联合学习是被广泛采用的系统上下文。联合学习(也称为协作学习,分布式学习)本质上是深度学习和分布式计算的组合,其中有一个服务器(称为参数服务器),该服务器维护深度学习模型以进行培训,并且有多个参与分布式培训的参与者处理。首先,训练数据被划分并存储在各方。然后,各方分别在其本地数据上训练深度学习模型(与参数服务器上维护的模型相同),并将中间梯度上传到参数服务器。在收到所有各方的梯度后,参数服务器会汇总这些梯度并相应地更新学习模型参数,此后,各方都会从服务器下载更新的参数,并继续使用相同的本地数据再次训练她的模型下载的参数。重复此训练过程,直到训练误差小于预定阈值为止。但是,这种联合学习框架无法保护训练数据的私密性,即使训练数据被分割并单独存储也是如此。例如,一些研究人员表明,中间梯度可用于推断有关训练数据的重要信息[17],[18]。 Shokri等。 [11]等人[11]通过在梯度中添加噪声以上传来应用差分隐私技术,从而在数据隐私和训练准确性之间取得了权衡。 Hitaj等al [19]指出,Shokri的工作未能保护数据隐私,并证明了好奇的参数服务器可以通过GAN(通用对抗网络)学习来学习私有数据。 Orekondy等。 al [20]利用中间梯度对训练数据发起可链接性攻击,因为梯度包含足够的数据特征。
丰等人[16]提出使用同态加密技术来保护训练数据的隐私免受好奇参数服务器的侵害。他们的计划的缺点是他们假设协作参与者是诚实的但并不好奇,因此在某些参与者感到好奇的情况下,他们的计划可能会失败。为了防止好奇的参与者,Bonawitz等。 [14]等人采用了秘密共享和对称加密机制来确保参与者梯度的保密性。他们假设(1)参与者和参数服务器根本无法合谋,并且(2)纯文本中的汇总梯度不会显示有关参与者本地数据的任何信息。不幸的是,第二个假设不再有效,因为现在可以对聚合的位置数据进行成员推断攻击[21]。
尽管正在进行有关分布式深度学习的广泛研究,但到目前为止,有两个严重的问题很少受到关注。第一个是现有工作通常考虑来自好奇参数服务器的隐私威胁,而忽略了梯度收集和参数更新中不诚实行为还存在其他安全威胁的事实,这可能会破坏协作培训过程。例如,参数服务器可能会故意降低某些参与者的梯度,或者故意错误地更新模型参数。最近,Bagdasaryan等。文献[22]证明了这个问题的存在,即不诚实的当事方可以通过用精心设计的更新模型代替更新模型来毒害协作模型。因此,分布式深度学习框架不仅要保证梯度的机密性,还要保证梯度收集和参数更新的正确性的可审计性至关重要。
2. BACKGROUND
2.1 Blockchain technology
区块链是第一种技术,在研究界和行业中都引起了人们的兴趣[25]。它成为一种去中心化,不变,共享和按时间顺序分类账的新兴技术。交易被存储到包含时间戳和引用(即,前一个块的哈希)的块中,它们被维护为链。在区块链中,交易是由匿名参与者创建的,并由一个称为工作者的实体竞争性地收集以建立新的区块。建立新的有效区块的工人可以获得一定数量的奖励,从而使具有竞争力的工人不断延长链条。提出了区块链环境中的激励机制。此外,正在开发的引入智能合约的区块链技术支持Turingcomplete可编程性,例如以太坊和Hyperledger。另一方面,通过将加密工具应用到Blockchain中,一系列关于交易隐私的作品很受欢迎,例如Zerocash [26],Zerocoin [27]和Hawk [28]。因此,区块链技术的激励功能及其先进技术促使我们解决方案问题,例如缺少激励功能和协作公平性。
2.2 Deep learning and distributed deep learning
3 THREATS AND SECURITY GOALS
在本节中,我们讨论协作学习的威胁以及DeepBC可以解决这些威胁的安全目标。
威胁1:暴露本地数据和模型。尽管在分布式深度训练中,每个参与方仅将其本地梯度上传到参数服务器,但攻击者仍可以通过发起推理攻击或成员攻击来推断这些梯度有关该方本地数据的重要信息。另一方面,基于梯度,对手也可以发起参数推断攻击以获得模型的敏感信息[19]。
安全目标:局部梯度的机密性。假设参与者没有公开自己的数据,并且至少t位参与者是诚实的(即,不多于t位参与者合谋暴露参数)。这样一来,除非至少有t个参与者勾结,否则各方的本地梯度都不会暴露给其他任何人。另外,如果在任何情况下参与者都不公开从协作模型中下载的参数,则对手将无法获得有关参数的任何信息。为了实现此目标,在DeepChain中,每个参与者分别加密,然后上传从其本地模型获得的梯度。使用所有梯度来更新由所有参与者进行协作加密的协作模型的参数,然后参与者在每次迭代中通过协作解密获得更新的参数。在此,协作解密意味着至少t个参与者提供其秘密份额以解密密码。
威胁2:行为不当的参与者。考虑在协作培训期间参与者可能有恶意行为的情况。他们可能会随意选择输入内容,从而产生不正确的渐变,从而误导协作式培训过程。结果,当使用上载的梯度更新协作模型的参数时,不可避免地会得到错误的结果。另一方面,在协作解密阶段,不诚实的参与者可能会给出有问题的解密份额,并且他们可能很自私,因此会提前中止本地培训过程以节省培训成本。此外,不诚实的参与者可能会为了自己的利益而延迟交易或终止合同,这会使诚实的参与者蒙受损失。所有这些恶意行为都可能使协作培训任务失败。安全目标1:梯度收集和参数更新的可审核性。在DeepChain中,假定大多数参与者和超过2 3的工作人员在梯度收集和参数更新方面分别是诚实的。在进行梯度收集期间,参与者的交易包含加密的梯度和正确性证明,从而使第三方可以审核参与者是否给出了正确的加密梯度构造。另一方面,对于参数更新,工作人员通过将记录在DeepChain中的交易声明计算结果。这些交易也是可审计的,并且只有在2 3个工人诚实的情况下,才能保证计算结果正确。在更新参数之后,参与者通过提供其解密份额和用于正确性验证的相应证明来下载和协作解密参数。同样,任何第三方都可以审核解密份额是否正确。
安全目标2:为参与者提供公平保证。 DeepChain通过超时检查和罚款机制为参与者提供公平。具体来说,对于具有智能合约的每个功能,DeepChain为其定义一个时间点。在函数执行后的时间点,将验证函数结果。如果验证失败,则意味着(1)到该时间点尚不准时存在参与者,并且(2)一些参与者可能会错误地执行该功能。对于这两种情况中的任何一种,DeepChain都将应用罚款机制,撤销不诚实参与者的预冻结存款,并将其重新分配给诚实参与者。因此,可以实现公平,因为永远不会对守时和正确行为的诚实参与者施加惩罚,如果存在不诚实的参与者,他们将得到补偿。
4 THE DEEPCHAIN MODEL
在本节中,我们介绍DeepChain,这是一个用于保护隐私的深度学习的安全且分散的框架。
4.1 系统概述
在介绍DeepChain之前,我们先给出DeepChain中使用的相关概念和术语的定义。
•参与方:在DeepChain中,参与方与传统的分布式深度学习模型中定义的实体相同,具有相似的需求,但由于资源限制(例如计算能力不足或数据有限)而无法单独执行整个培训任务。
•交易:当一方获得其本地渐变时,她会通过称为交易合约的智能合约向DeepChain发送渐变。此过程称为交易。这些合同可以由工人(即将在DeepChain中定义的实体)下载并处理。
•合作小组:合作小组是一组具有相同深度学习模型的参与方。
•本地模型训练:每个参与方独立地训练其本地模型,并且在本地迭代结束时,该参与方通过将其本地渐变附加到合同来生成要交易的合同。
•协作模型培训:一个协作小组的各方可以协作地训练深度学习模型。具体而言,在确定相同的深度学习模型和参数初始化之后,以迭代方式训练模型。在每次迭代中,所有各方都使用其梯度进行交易,并且工作人员下载合同以处理梯度。然后,工作人员通过称为处理合同的智能合同发送已处理的渐变。正确处理的渐变用于从领导者更新协作模型的参数。各方下载协作模型的更新参数,并相应地更新其本地模型。之后,各方开始进行模型训练的下一个迭代。
•工人:类似于BitCoin中的矿工,通过激励工人处理包含(训练权重以进行协作模型更新的)交易。工人竞争在街区工作,而第一个完成工作的人就是领导者。领导者将获得将来可以使用的集体奖励,例如,她可以使用奖励来支付DeepChain中训练有素的模型的使用费。
•迭代:深度学习模型训练包含称为迭代的多个步骤,其中在每次迭代结束时,模型神经元的所有权重都会更新一次。
•回合:在DeepChain中,回合是指创建新区块的过程。
•DeepCoin:DeepCoin,表示为$ Coin,是DeepChain上的一种资产。特别是,对于每个新生成的区块,DeepChain将生成一定数量的$ Coin作为奖励。 DeepChain的参与者包括参与者和工作人员,前者因对当地模型培训的贡献而获得了$ Coin奖励,后者因帮助各方更新培训模型而获得了$ Coin奖励。同时,一个训练有素的模型将使那些没有能力自己训练模型并想使用该模型的人花费$ Coin。该设置是合理的,因为最近在机器学习的基于模型的定价上的工作已在某些场景中找到了应用[39],[40]。我们为$ Coin定义了一个有效性值,它实际上是一轮的时间间隔。有效性值与DeepChain中的共识机制有关,我们将在4.2.5中对其进行详细讨论。
4.2 Components of DeepChain
4.2.1 DeepChain bootstrapping
DeepChain自举包含两个步骤,即DeepCoin分发和创世块生成。假设所有参与者和工作人员都已在DeepChain中注册(即拥有有效帐户),其中每个人都使用与DeepCoin单位相对应的地址pk发起交易。
第一步,DeepCoin分发实现了在各方和工作人员之间进行DeepCoin分配,并且最初为每个参与方或工作人员分配了相同数量的DeepCoin。然后在第二步中,在第0轮生成一个创世块,其中包含记录每个DeepCoin所有权声明的初始交易。
创建创世块后,一个随机种子seed0也是众所周知的,它最初由注册用户通过例程随机选择,用于生成分布式随机数。当DeepChain继续运行时,在第i轮,seedi-1用于生成seedi。值得一提的是,这些随机种子对于DeepChain至关重要,因为它们在选择领导者在每一轮中创建新区块时都保证了随机性。引入随机种子的想法是由Algorand的密码分类[41],[42]推动的,详细信息将在第4.2.5节中给出。
4.2.2 Incentive mechanism
激励可以作为参与者积极,诚实地参加协作培训任务的动力,激励机制的目标是产生和分配价值,以便参与者根据自己的贡献获得奖励或惩罚。由于以下原因,激励机制的引入对于协作式深度学习至关重要。首先,对于那些想要深度学习模型但数据不足以自行训练该模型的参与者而言,激励可以激励他们加入他们本地数据的协作训练。其次,通过奖励和惩罚机制,激励机制可以确保(1)各方在本地模型培训和梯度交易中诚实,(2)工人在处理各方交易中诚实。为了便于理解激励机制,我们举一个由两方组成的示例。这两方通过发起事务将其数据贡献给协作培训。假设双方拥有的数据数量不相等。每一方都可以发起交易并根据她拥有的数据量支付交易费。通常,一方拥有的数据量越大,她将支付的费用就越少。双方同意共同培训模型的费用总额。在处理交易时成功创建新区块的工人可以成为领导者并获得奖励。请注意,交易的发出和处理是可验证的,这意味着如果某方提出无效交易,则该方将受到惩罚。另一方面,如果领导者错误地处理了交易,则她将受到相应的惩罚。协作培训完成后,各方本身就可以从经过培训的模型中受益,该模型可以通过向希望使用经过培训的模型的用户收费的服务为他们带来收益。为了对激励机制进行正式描述,我们首先介绍两个属性,即参与者激励机制的兼容性和活跃性。然后,我们进一步说明,参与者和工人都有激励人们诚实行事的动机。假设我们保证共识协议的数据保密性和安全性(在第4.2.5节中有解释)。我们使用vc和vi分别表示训练有素的协作模型和训练有素的个体模型i的值,并且我们假定vc大于vi。首先,我们说如果每个参与者都能根据自己的贡献获得最佳结果,那么激励机制就具有兼容性。同时,参与者只有在愿意通过连续发起交易来更新其价值vi的本地培训模型时才具有活力,并且每个员工还具有使用价值vc更新协作培训模型的参数的动机。下面,我们将针对参与者的真实贡献和相应的回报描述这两个属性的重要性。令!P和!W分别是一方和工人对最终训练模型的贡献,而πP和πW分别是它们相应的收益。首先,我们假设参与者的贡献很可能来自于她的正确行为,然后我们将解释这种假设是合理的。
活泼:党和工人都有共同的共同兴趣,以获得训练有素的协作模型。因为如果一方在整个培训过程中花费vi,那么她最终将获得vc,这对她很有吸引力,因为vc大于vi。另一方面,工作人员将处理交易以共同构建培训模型,以便有机会获得奖励,从而可以为DeepChain的深度学习服务付费。请注意,工人获得奖励的可能性取决于她已经获得的奖励数量。数量越大,她获得奖励的可能性就越高。结果,激励了党和工人建立协作培训模型。
兼容性:一方贡献!P越多,她获得的πP就越多。这也适用于工人。在协作式培训过程中,双方和员工都在培训模型Max(!P)V Max(!W)上做出最佳贡献,其中最大总回报为Max(πP)+ Max(πW)。如果任何参与者表现不佳,即(!P = 0)W(!W = 0),那么就没有奖励,即(πP= 0)V(πW= 0)。在此,and 表示“和”,or 表示“或”。所以我们有
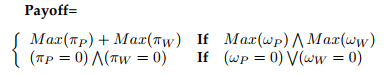
接下来,我们解释一个假设,即参与者的贡献很有可能来自其正确的行为。我们证明,每一方和工人在每个回合中都是以价值驱动的,以使其行为正确,以便他们可以获得最高的回报[43]。当参与者行为正确时,该值最高。我们将其形式化为:派对的V alue(1)=πP-!P(1),类似地,V alue(1)=πW-!W(1)对于工人。数值1表示100%。然后将其替换为P rc(·),用于测量参与者的行为正确性。因此,!P(1)表示一方以100%的概率正确行为,而V alue(1)在这种情况下是相应值,这是预期的情况。然后,我们说!P具有正确提供的概率P rc(P),并且由于验证了该方的实际行为,所以V alue(P rc(P))与P rc(P)有关。假定以方差P rv(P)验证一方恶意行为的方法是正确的。那么,不诚实的一方被抓住的概率为P rv(P)*(1-P rc(P))。一旦发现不诚实的一方,她将被没收存款以受到惩罚,损失记为fP。
因此,根据当事方的正确行为得出的最终价值可以表示为
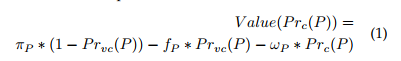
其中P rvc(P)= P rv(P)∗(1 − P rc(P))。 仅当一方诚实行事时,即P rc(P)= 1时,上述值才达到最大值。然后,V alue(1)=πP-!P(1)成立。 这表明了激励机制的重要性。 具体地,可以通过以下定理来确定P rv(P),πP和fP的值。
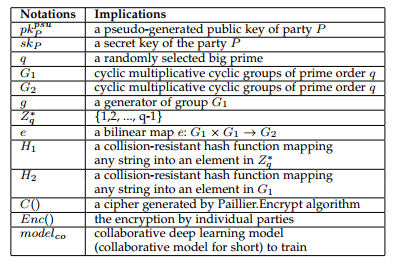

对于工人而言,激励机制的分析与上述对一方的分析相似,期望该工人的回报是有可能获得的。 我们用P rleader表示该概率,然后可以通过以下定理确定四个值P rleader,P rv(W),πW和fW之间的关系,以鼓励工人诚实。
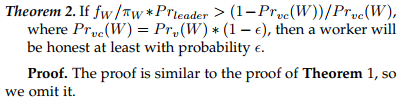
4.2.3 Asset statement
为了便于演示,我们在表1中列出了本节中使用的相关加密符号。一方需要陈述其资产,这使她能够找到合作者并完成其深度学习任务。 资产报表不会显示资产的内容,因为它只是资产的某种描述,例如资产可以用于哪种深度学习任务。 具体地说,P方通过发送资产交易来声明资产,这将在以后介绍。
我们回想起交易的形成。 注意,事务是由P根据其希望以以下形式生成的伪公共密钥地址pkPpsu启动的。

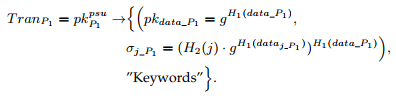
在此事务中,括号中的第一部分由pkdata P1和σjP1组成,这是当事方P1确实拥有资产H1(数据P1)而不会泄漏数据P1内容的声明证明。 特别地,σjP1包含l个分量,其中数据P1分为由dataj P1,j 2 [1; l]。 第二部分“关键字”是资产数据P1的描述。 在我们的实现中,“关键字”采用JSON格式,其中包括四个字段,即数据大小,数据格式,数据主题和数据描述。 通过此交易T ranP1,P1可以履行其资产报表。 我们假设第一个陈述的资产是真实的,这在区块链中是合理的。
4.2.4 Collaborative training
根据陈述的资产,具有相似深度学习任务的各方可以组成一个协作组,并且协作培训过程包括以下四个步骤。
•协作小组的建立。根据类似的“关键字”,各方可以建立一个协作小组。值得注意的是,各方可以通过脱机交互获得有关“关键字”的更多详细信息,这不是本文的重点。在组建协作小组之前,各方可以审核合作者的资产,以确保资产所有权的真实性。审计过程可以使用[44]中的方法完成,为简洁起见,我们省略了详细信息。假设有N个参与方P1,P2,::,PN组成具有假名的组,即,伪公共密钥pkPpsu 1; pkPpsu 2; :::; pkPpsu N及其对应的秘密密钥skP1; skP2; :::; skPN分别是私有的。由于不同方使用她自己的伪公共密钥pkPpsu i启动交易,因此可以验证由相应的秘密密钥skPi签名的交易,以确保这些交易来自同一合作方Pi。
•协作的信息承诺。协作小组形成后,各方就可以安全地训练深度学习模型的信息达成一致。在此步骤中,我们假设可信组件(例如,英特尔SGX [45]之类的可信硬件)仅参与Threshold Paillier算法[46]的设置阶段,并且不参与其他过程。如果不存在这样一个受信任的组件,我们可以通过使用分布式方法(如[47]中的方法)来完成设置阶段。各方同意以下信息。
(1)合作方数目,N
(2)本轮指数 r
(3)Threshold Paillier算法的参数。我们有以下等式
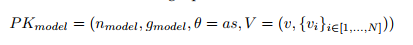
其中模数nmodel是两个选择的安全素数的乘积,gmodel 2 Zn ∗ 2模型,a; s; θ; v; vi 2 Zn *模型。 并且SKmodel = s随机分为N个部分,其中s = f(s1 + ::: + sN),而f是秘密共享协议的函数。 每一方都拥有一部分安全密钥si,v和fvig,i 2 [1; :::; N]是公共验证信息,其中vi对应于si。 阈值t 2 fN2; :::; Ng设置为使得t个以上的方可以一起解密密码。
(4) A collaborative model modelco to be trained
对于协作模型模型,各方在训练神经网络,训练算法和网络配置(例如网络层数,每层神经元数,最小批量和迭代次数)上达成共识。 除了这些信息,他们还对modelco的初始权重W0达成了共识。 请注意,在第i次训练迭代后,权重Wi将更新为Wi + 1。 它们通过应用Paillier.Encrypt算法来保护W0,即C(W0)= gmodel W0·(k0)nmodel,其中k0是从Zn ∗模型中随机选择的。 请注意,我们借助所选的超递增序列来计算gmodel W0,即gmodel W0 = gmodelα1·w01 + ::: +αl·w0l,以便为权重向量W0 =(w01; ::: ; w0l)。
(5) A commitment on SKmodel = s, with respect to PKmodel.
承诺commitSKmodel是通过合并各方对其秘密份额si的承诺而获得的。 回想一下r是当前回合的索引号。 我们有
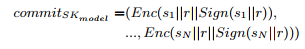
在这里,|| 表示串联。
(6) The initial weights W0;j of local model of party j.
各方提供由Paillier加密的本地模型的初始权重。
(7) A amount of deposits d($Coin).
每个合作方都需要承诺一定数量的保证金以进行安全计算。 在合作培训期间,如果一方故意失职,其存款d($ Coin)将被没收,并补偿其他诚实方。 否则,这些押金将在培训过程完成后退还。
以上所有协作信息都记录在上载到DeepChain的交易T ranco中。 具体地说,T ranco具有以下形式,并附加到通常协调的地址pkco psu上。

此外,为协作组中的各方定义了称为交易员和经理的两个角色,稍后将对其进行说明。接下来,我们介绍如何通过剩下的两个步骤安全地完成协作培训,即通过贸易合同收集渐变和通过处理合同进行参数更新。
首先,当事方通过由合作方中选择的经理执行的交易合同迭代地交易其梯度。每个交易者都诚实地对交易梯度进行加密,同时附加了正确的加密证明,表明了两个安全性要求,即机密性和可审计性。在此,我们说生成了梯度交易。在保密性方面,如果交易者不公开其梯度,则没有人可以获得有关梯度的信息。此外,交易员(最多t个交易方)需要合作解密更新后的参数。与[28]类似,我们假设经理没有透露她所知道的。在可审计性方面,存在可以进行审计的正确加密的证据。在合作解密时,每个交易者都提供自己的解密证明。这些证明是非交互式生成的,并且可由DeepChain上的任何一方公开审核。
通过超时检查和罚款机制,交易者和经理的行为被迫真实可信。即使经理与交易者串通,交易合同的结果也无法修改[28]。除交易合同外,处理合同还负责参数更新。工人通过累加梯度来处理交易,并将计算结果发送到“处理合同”。处理合同验证正确的计算结果并更新组的模型参数。这两个合同被迭代调用,以完成整个培训过程。这两个步骤的详细信息如下。
7. CONCLUSION AND FUTURE WORK
在本文中,我们介绍了DeepChain,这是一个基于区块链的健壮且公平的去中心化平台,用于安全的协作深度培训。具体来说,我们引入一种激励机制并实现三个安全目标,即机密性,可审核性和公平性。我们从兼容性和活跃性的角度正式制定了基于区块链的激励机制。此外,在激励机制的背景下,我们证明了参与者具有高概率正确行为的激励。为了保证局部梯度的机密性,我们采用阈值Paillier算法来保护数据。通过将熟练的组件应用于加密算法,可以实现仅为一方生成一个密码的目标。除了保密之外,我们还通过解决恶意参与者可能破坏协作培训过程的问题来提供可审计性和公平性。我们集成了非交互式零知识证明工具,以提供对协作培训过程的审核能力,并通过区块链的超时检查和罚款机制来推动参与者公平行事。我们最终实现了DeepChain的原型,并对其进行了评估,以从密文大小,吞吐量,训练准确性和训练时间四个方面说明可行性。
接下来,我们希望长期讨论DeepChain的重要性。 DeepChain存储的数据不仅包括迭代训练参数,还包括训练模型。一方面,很明显,当基于模型的定价市场充满希望时,经过训练的模型可以创造财务价值。这给拥有训练有素的模型的参与者带来了长期的利益,因为他们的模型可以通过付款的方式为有AI任务的人提供服务。另一方面,记录了每次迭代的所有训练过程和模型参数,这可以促进转移学习的发展。因此,在第二方面,我们采取了第一步考虑,即DeepChain可以扩展模型的潜在价值以转移学习。直觉是,可以将训练有素的模型应用于为其他但相关的AI任务训练新模型。在这种情况下,应重新定义安全性问题,将在以后的工作中进行讨论。


















 2137
2137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











