







词转为词向量的过程:
三层结构:
-
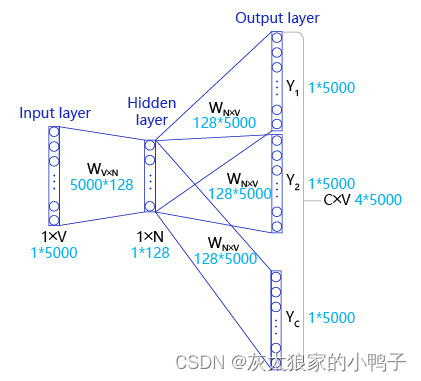
输入层:输入参数是V=(1 * 5000)的张量,表示当前句子中心词的ont_hot;
-
隐藏层:隐藏层的参数 W1=(5000 * 128) 也叫词向量,隐藏层的输出是R1=(1 * 128) ,表示当前句子中心词得词向量。
-
输出层:输入参数是:R1=(1 *128) ,输出层的参数W2=(128 * 5000),W2也叫词向量,输出大小是R2=(1 * 5000),经过softmax变换就可以得到上下文预测的结果。
-
在实际操作中,使用一个滑动窗口(一般情况下,长度是奇数),从左到右开始扫描当前句子。每个扫描出来的片段被当成一个小句子,每个小句子中间的词被认为是中心词,其余的词被认为是这个中心词的上下文。
理论实现:
使用神经网络实现Skip-gram中,模型接收的输入应该有2个不同的tensor:
-
代表中心词的tensor:假设我们称之为center_words V,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中,每个中心词的ID,对应位置为1,其余为0。
-
代表目标词的tensor:目标词是指需要推理出来的上下文词,假设我们称之为target_words T,一般来说,这个tensor是一个形状为[batch_size, 1]的整型tensor,这个tensor中的每个元素是一个[0, vocab_size-1]的值,代表目标词的ID。
在理想情况下,我们可以使用一个简单的方式实现skip-gram。即把需要推理的每个目标词都当成一个标签,把skip-gram当成一个大规模分类任务进行网络构建,过程如下:
-
对于给定的输入V=[batch_size,vocab_size],声明一个形状为W0=[vocab_size, embedding_size]的张量,作为需要学习的词向量,记为W0。使用向量乘法,将V乘以W0,这样就得到了一个形状为[batch_size, embedding_size]的张量,记H=V×W0。这个张量H就可以看成是经过词向量查表后的结果。
-
将上一步得到的H=[batch_size,embedding_size]去乘以W1,声明另外一个需要学习的参数W1,这个参数的形状为W1=[embedding_size, vocab_size]。得到一个新的tensor O=H×W1,此时的O是一个形状为O=[batch_size, vocab_size]的tensor,表示当前这个mini-batch中的每个中心词预测出的目标词的概率。
-
使用softmax函数对mini-batch中每个中心词的预测结果做归一化,即可完成网络构建。
实际实现:
然而在实际情况中,vocab_size通常很大(几十万甚至几百万),导致W0和W1也会非常大。对于W0而言,所参与的矩阵运算并不是通过一个矩阵乘法实现,而是通过指定ID。
在实现的过程中,通常会让模型接收3个tensor输入:
-
代表中心词的tensor:假设我们称之为center_words V,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个中心词具体的ID。
-
代表目标词的tensor:假设我们称之为target_words T,一般来说,这个tensor同样是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个目标词具体的ID。
-
代表目标词标签的tensor:假设我们称之为labels L,一般来说,这个tensor是一个形状为[batch_size, 1]的tensor,每个元素不是0就是1(0:负样本,1:正样本)。
模型训练过程如下:
-
用V去查询W0,用T去查询W1,分别得到两个形状为[batch_size, embedding_size]的tensor,记为H1和H2。
-
将这两个tensor进行点积运算,最终得到一个形状为[batch_size]的tensor O;
-
点积:a·b=a1b1+a2b2+……+anbn。
-
使用sigmoid函数作用在O上,将上述点积的结果归一化为一个0-1的概率值,作为预测概率,根据标签信息L训练这个模型即可。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









