






Word2Vec主要有两种模型:Skip-Gram和CBOW两种。从直观上理解,Skip-Gram是给定input word来预测上下文,而CBOW是给定上下文,来预测input word。
主要讲Skip-Gram模型
1、先从one-hot编码开始
什么是one-hot编码?
one-hot编码,即一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有自己独立的寄存器位,并且在任意时候,其中只有一位有效。
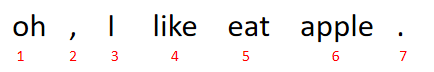
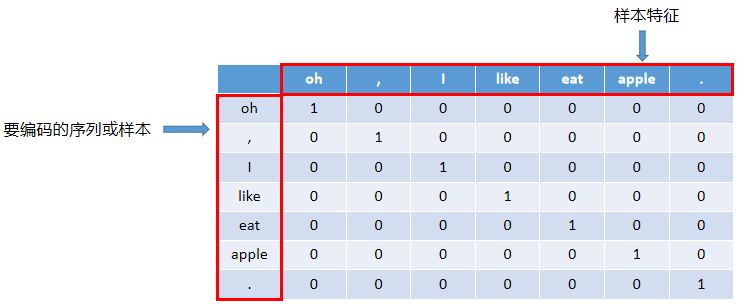
上图中有7个样本,7个特征。那么每个单词以及符号可以用以下向量表示:
2、Skip-Gram模型:由输入找输出

假设有1000个词,则生成1000个one-hot编码。上面的单词,都是1000个词里面存在的。(为了简便,在这里不考虑标点符号)
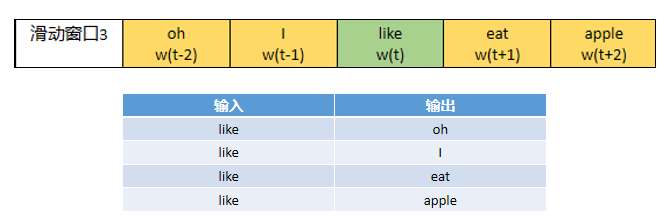
假设like为输入,那么接下来要挑选输出。这里涉及到滑动窗口(sliding window)的概念。
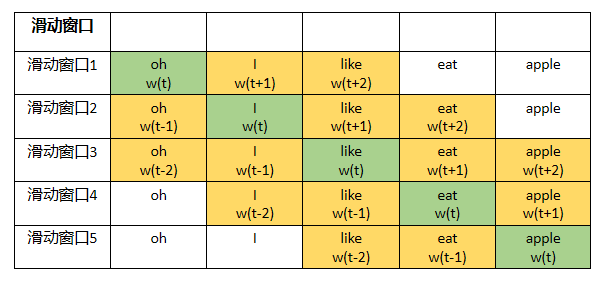
不管是CBOW还是Skip-Gram,都会用到“中心词”和它周围的“上下文”的概念。和文章中的上下文不一样。这里的“上下文”不是指真正的一个文章段落的上下文,而是提前设置好长度的“窗口”。一个窗口包含的词的数量是一定的(除了在开头和结尾处出现长度不够的情况),所以当中心词向前移动时,整个“窗口”都会随之移动,称这种窗口为“滑动窗口”。
上图是以窗口大小为中心词的前后两个词(±2)为例,标为绿色的表明当前是中心词,即w(t),标为橘色表明当前窗口所覆盖的范围,即从w(t-2)到w(t+2)。即标为绿色的中心词为输入,标位橘色的词为我们要寻找的输出。
3、Skip-Gram模型:bp神经网络
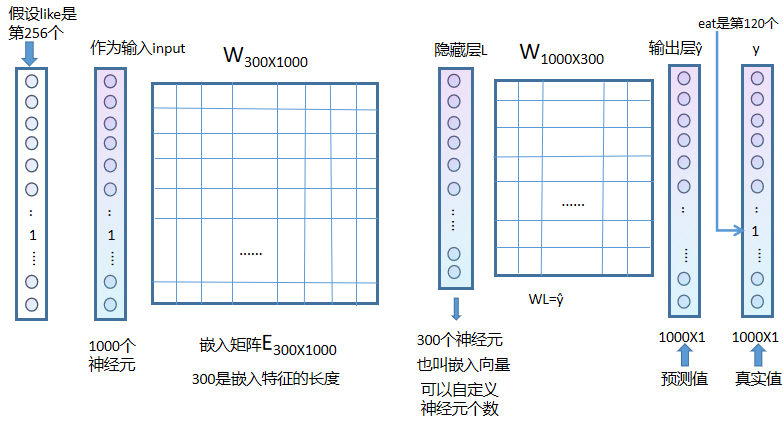
注意:
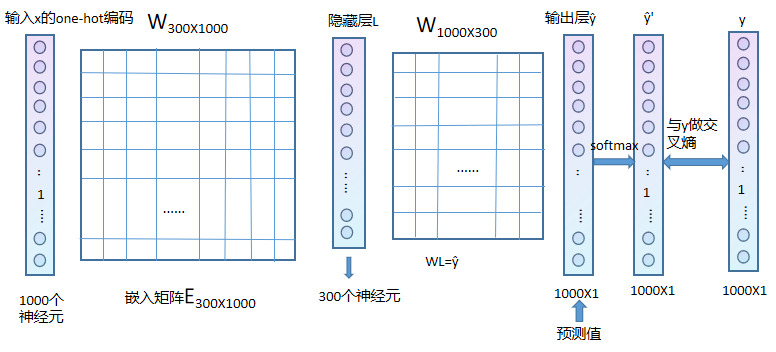
①当权重矩阵和神经元进行计算时,需要将权重矩阵放在前面,即WL=ŷ
②隐藏层不需要激活函数
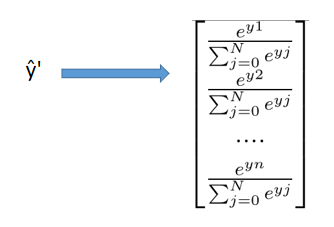
③理论上得到的输出ŷ与y做误差进行反向传播即可,但是在这个推导里面不可以,因为y为one-hot矩阵,只有1个地方为1,其他地方均为0,为了反向传播的效果更好,需要对预测的值进行softmax,得到ŷ',但是这样做会导致反向传播的计算量特别大。
4、反向传播计算量大的原因

经过ŷ的softmax计算得到ŷ',ŷ'与y相减(左图)进行反向传播的计算,在隐藏层时,隐藏层数为300,需要乘以一个普通的权重矩阵,还原回1000层,在这期间,计算量很大,隐藏层的每一层都需要和权重矩阵的每一行进行乘积并相加(右图红框部分),得到ŷ一个神经元的输出。
计算次数:
①右图中权重矩阵每一行乘以隐藏层每一列,权重矩阵共1000行,所以需要进行1000次计算。
②左图中ŷ转化为ŷ'需要进行1000次计算。
简单来看,总共需要2000次计算,这是一个输入和输出的组合,如下图,若有4个输入输出组合,则需要进行4X2000次计算,导致计算量过大。
5、如何训练多个词?
在4中说明了使用softmax进行计算导致反向传播计算量大的原因,暂不考虑改进这个方面,先继续往下进行,网络是如何对多个组合进行训练的?
假设有如下N=5个样本(x表示输入,y表示输出):
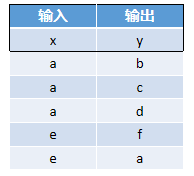
①我们输入a的one-hot编码,经过计算得到ŷ',ŷ'与b的one-hot编码做交叉熵。
②再将a输入。经过计算得到ŷ',ŷ'与c的one-hot编码做交叉熵。
...........
最后将得到的损失函数结果相加(N个)
6、优化
可以将softmax改进成n个二分类的逻辑回归分类器,即把词匹配的方法改进。
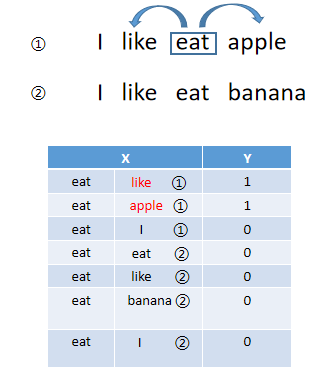
若like和apple是来自第一个句子的滑动窗口里面的,称为正样本(有效配对) 。当第一个句子中eat和I配对时,为负样本,因为skip-window=1,即滑动窗口大小为1。负样本是随机的,是采样才出来的,一般为1个正样本配上5个负样本。(①表示单词来自第一个句子,②表示单词来自第二个句子)
7、模型如何放进网络里面训练,又如何产生结果?
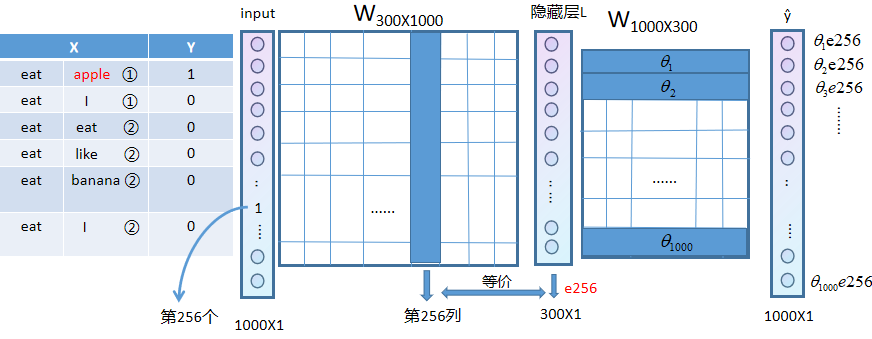
①将eat的one-hot编码放入input(这里假设eat是1000个词里的第256个,apple是第200个,banana是第400个)
②隐藏层简记为e(嵌入向量),将每一行记为
③使用sigmoid函数
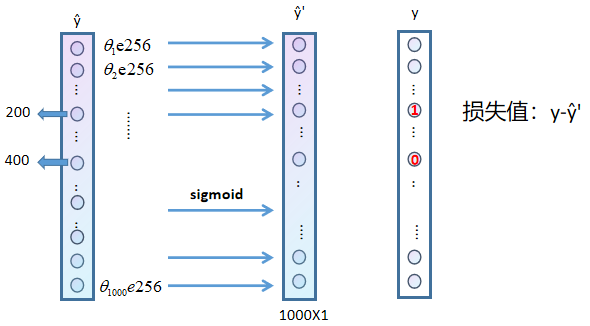
其中ŷ'的计算值为,
,
,.......
④一般是1个正样本+5个负样本组成一对X,Y
⑤只更新这个6个即可
注:本文参考B站视频。https://www.bilibili.com/video/BV1mL411L7ia















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









