









EDTER: Edge Detection with Transformer(EDTER: 基于 Transformer 的边缘检测)
期刊合集:最近五年,包含顶刊,顶会,学报>>网址
文章来源:CVPR 2022
研究背景
卷积神经网络通过逐步探索上下文和语义特征,在边缘检测方面取得了重大进展,然而,局部细节随着感受野的扩大而逐渐被抑制。基于 Transformer 在 长期依赖关系 方面出色的表现,文章提出一种基于 Transformer 的边缘检测器,通过利用完整的图像上下文信息和详细的局部线索来提取清晰的物体边界和有意义的边缘。
EDTER 分两阶段进行:在阶段 I 中,使用 global transformer encoder 捕获粗粒度图像补丁上的远距离全局上下文;第 II 阶段, local transformer encoder 在细粒度补丁上工作,以挖掘近距离局部线索,每个 Transformer 编码器后面都有一个 双向多级聚合解码器,用于提高分辨率。最后,通过特征融合模块将全局上下文和局部线索结合起来,并输入决策头(head)进行边缘预测。
问题引入
边缘检测是计算机视觉中最基本的问题之一,具有广泛的应用,如图像分割,物体检测,视频物体分割。对于给定的输入图像,边缘检测的目的是提取精确的物体边界和视觉显著的边缘,但由于复杂的背景、不一致的注释等因素,它具有挑战性。

首先,考虑到计算量的问题,Transformer 通常应用于尺寸相对较大的 patch,而粗粒度的 patch 不利于学习边缘的精确特征,在不增加计算负担的情况下对细粒度补丁执行自我关注是至关重要的。其次,如图 (d) 所示,从相交的薄物体(有多个物体的情况)中提取精确的边缘是具有挑战性的,因此,有必要设计一个有效的 decoder 用于生成边缘感知的高分辨率特征的编码器。
论文分析
文章贡献如下:
1)提出了边缘检测变压器( EDTER ),用于检测自然图像中的物体轮廓和有意义的边缘。
2)EDTER 设计用于有效地探索远程全局上下文( 阶段 I )和捕获细粒度局部线索( 阶段 II )。
4)提出了一种新的双向多级聚合( BiMLA ) decoder 来促进 Transformer 中的信息流。
3)为了有效地整合全局信息和局部信息,使用特征融合模块( FFM )来融合从阶段 I 和阶段 II 提取的线索。
网络框架
1、Overview

首先在阶段 I,将输入图像分割为粗粒度补丁序列,并使用全局转换器编码器(Global Transformer Enconder)来学习全局上下文信息,然后再采用双向的多级聚合( BiMLA )解码器生成高分辨率特征。在阶段 II 中,通过不重叠的滑动窗口采样,将整个图像分割成多个细粒度斑块序列。然后,依次对每个序列执行一个局部变压器编码器,以捕获短程局部线索,将所有的局部线索整合到一个局部的BiMLA解码器中,实现像素级的特征映射。最后,通过特征融合模块( FFM )对全局特征和局部特征进行融合,然后输入决策头预测最终的边缘图。
2、Review Vision Transformer
本文中的框架所使用的变压器编码器遵循视觉变压器 ( ViT ),如下所述。
Image Partition:
ViT 的第一步工作,就是将一个( X ∈ R H×W ×3) 的二维图像转换为一维图像补丁序列(可以理解为转变为列向量或者行向量)。具体来说,将图像 X 均匀地分割成一组大小为 P × P 的扁平图像斑块序列,得到 H / P × W / P 的 vision tokens。然后,利用可学习线性投影将序列映射到隐藏的嵌入空间中。(经过投影的特征称之为补丁嵌入)。此外,为了保留这些位置信息,将标准的可学习一维位置嵌入添加到补丁嵌入中。最后,将组合好的嵌入 (记为z0 ) 被馈送到 Transformer encoder。
Transformer Encoder:
一个标准 Transformer encoder 是由 L 个 Transformer 块组成,每个块都有一个多头自注意力 操作( MSA )、一个多层感知机 ( MLP )和 两个 Layernorm 步骤( LN ),另外,每块还应用了一个残差连接(什么是ResNet50),MSA 并行执行 M 个自注意力并输出它们串联 (concat) 的结果。

MSA 并行执行 M 自注意力并输出它们 concat 的结果:具体细节如下:
在第 m 个自注意力中,给定第( l−1 )个变压器块的输出 z l−1 ∈ R N×C,则查询 Q ∈ R N×U,键 K ∈ R N×U,值 V ∈ R N×U,计算如下:

其中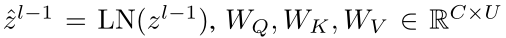 属于是参数矩阵,C 是嵌入的维数,U 是 Q,K,V 的维数(三个矩阵的维数是一样的,LN 是 layernorm 操作)。然后,根据序列中两个元素之间的成对相似度计算第 m 个自注意力的输出:
属于是参数矩阵,C 是嵌入的维数,U 是 Q,K,V 的维数(三个矩阵的维数是一样的,LN 是 layernorm 操作)。然后,根据序列中两个元素之间的成对相似度计算第 m 个自注意力的输出:

其中 ysam 为注意权重,d 代表的是矩阵的维数,最后,MSA 就可以表示为:

其中 ymsa 为 MSA 的输出,WO ∈ RM·U×C 为投影参数,[·] 作用为拼接。
3、 Stage I: Global Context Modeling
由于图像中的边和边界具有鲁棒语义,捕捉抽象的线索和整个图像的整体背景是至关重要的。
第一个阶段:通过 globalTranformer encoder Ge 和 global decoder Gd 来提取粗粒度补丁上的全局上下文特征。具体来说,首先将输入图像分割成大小为 16×16 的粗粒度补丁序列,然后生成嵌入 z0g 作为编码器的输入,全局 Transformer 编码器 GE 在嵌入 z0g 上工作,用于计算全局注意力。

计算得到的全局上下文特征 zg 序列经过全局解码器 Gd 上采样 到高分辨率特征进行合并。
BiMLA Decoder:
生成边缘感知的像素级表示 对于精确的边缘检测至关重要。文章希望可以设计出一个实用解码器( decoder ),用来鼓励 Transformer encoder 计算边缘感知的注意,并以可学习的方式对注意力进行上采样,受多级特征融合的影响,作者提出了 双向多级聚合解码器(BiMLA)。

在 BiMLA 中,设计了一种双向特征聚合策略,包括自顶向下路径(Top-down path)和自底向上路径(Bottom-up path),以促进 Transformer coder 中的信息流。具体来说,将 Lg 个 Transformer 块统一划分为 4 组,并将每组最后一块的嵌入特征 { z6g, z12g, z18g, z24g } 作为输入。然后将它们 reshape 成 3D 特征图( H/16×W/16×C )。对于自顶向下的路径,采用相同的设计(一个 1×1 卷积和一个 3×3 卷积层)作用于 reshaped feature 得到四个输出 features ( t6,t12,t18,t24 ),遵循 SETR-MLA 的方法。同样地,自底向上的路径从最底层逐步到顶层,分配 3×3 卷积层到多级特征上,最后产生另外四个输出 features ( b6,b12,b18,b24 )。与通过双线性操作对特征进行上采样的 SETR-MLA 不同,每个聚合特征通过一个反卷积 block,包含 4×4 和 16×16 两个反卷积层,每个反卷积之后加入 批归一化 BN 和 ReLU 。双向路径的八个特征图(包含top-down path 和 Bottom-up path 得来的特征)进行 concat 操作得到一个 tensor。BIMLA 使用额外的卷积层来平滑 features,包括三层 3×3 卷积层和一个 1×1 卷积层+BN+ReLU。

其中 fg 为像素级全局特征,gD为 全局 BiMLA 解码器(global BiMLA decoder)。
4、Stage II: Local Refinement
对于像素级预测,特别是边缘检测,探索细粒度的上下文特征是必不可少的。理想情况下的边缘宽度为 1 像素( 要求较高 ),而 16×16 补丁不利于提取薄边缘。将像素作为 tokens 可能是一种直观的补救方法,但由于计算成本很高,实际上这是不可行的。文章给出的解决方案:使用一个不重叠的滑动窗口对图像进行采样,然后计算采样区域内的注意力,由于窗口中的 patches 的数量是固定的,计算复杂度和图像大小成线性关系。
因此,文章建议在阶段 II 中捕获短程细粒度上下文特征,如图,在图像 X ∈ RH×W ×3 上执行大小为 H / 2 ×W / 2 的不重叠滑动窗口,将输入图像 X 分解为序列{ X1, X2, X3, X4 }。对于每个窗口,将其分割为大小为 8×8 的细粒度补丁(分得更小了),并通过共享的 local transformer encoder RE 计算关注。然后将所有窗口的注意值进行 concat 操作,得到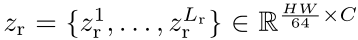 ,为了进一步节省计算资源,将 Lr = 12,也就意味着 local tranformer decoder 由12 个transformer blocks组成,与全局 BiMLA 类似,选择{ Zr3,Zr6,Zr9,Zr12 } 输入到局部 BiMLA RD生成局部高分辨率特征。
,为了进一步节省计算资源,将 Lr = 12,也就意味着 local tranformer decoder 由12 个transformer blocks组成,与全局 BiMLA 类似,选择{ Zr3,Zr6,Zr9,Zr12 } 输入到局部 BiMLA RD生成局部高分辨率特征。

其中 fr 为局部特征。与全局的 BiMLA 区别在于,局部的 BiMLA 中的 3×3 卷积层替换为 1×1 卷积层,目的是为了避免填充操作造成的人工边缘(操作过多)。

Feature Fusion Module:
通过一个特征融合模块 ( FFM ) 整合来自于两个 levels 的上下文信息,并利用局部决策头来预测边缘。FFM 将全局上下文作为先验知识并对局部上下文进行调节,生成包含全局上下文和细粒度局部细节的融合特征(这个是文章需要的)。FFM 由空间特征 transform block和两个 3×3 卷积层组成,然后进行 BN 和 ReLU 操作,前者用于调节,后者用于平滑。然后将融合特征输入局部决策头 RH,预测出边缘图Er。

其中 RH 是局部决策头,由 1×1 卷积层和 sigmoid 操作组成。
5、Network Training
为了训练两阶段框架 EDTER,首先优化第一阶段以生成代表整个图像上下文信息的全局特征。然后,修正阶段 I 的参数,训练阶段 II生成边缘图。
Loss Function: 给定边缘图 E 和对应的实际真相 Y,损失计算为:

其中,α = | Y− | / (| Y− | +| Y+|) 表示负像素样本的百分比,其中 |·| 表示像素个数。在实践中,将多个标签归一化为范围为 [0,1] 的边缘概率映射,然后使用阈值 η 来选择像素,如果概率值大于 η,则像素标记为正样本;否则,表示为负样本。
Training Stage I:
首先将全局决策头(head)合并到全局特征图上,生成边缘图:

其中 GH 表示全局决策头,由 1×1 卷积层和 sigmoid 层组成。此外,获得了多个侧输出S1g, S2g,…,通过对全局 BiMLA 解码器提取的中间特征t6, t12, t18, t24和b6, b12, b18, b24进行相同的设计(4×4反卷积层和16×16反卷积层),逐步强制编码器强调边缘感知注意。

阶段 I 通过最小化每个边缘图与实际真相之间的损失来优化。阶段 I 的损失函数表达式为:

其中LEg为Eg的损失,Lsideg为侧损失,λ 为平衡 LEg 和 Lsideg 的权重。
Training Stage II:
阶段 I 训练完之后,确定其参数然后进入阶段 II 。

其中 LEr 和 Lsider 分别为 Er 和 侧输出 的损失。
实验结果





BSDS500测试集中三个挑战性样本的定性比较:

所有的结果都是用单一的比例输入计算出来的:


总结
限制:该算法提取的边缘宽度占据多个像素,与理想的边缘宽度存在差距,在不进行任何预处理的情况下,生成清晰和细致的边缘是努力的方向。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











