









该系列仅在原课程基础上部分知识点添加个人学习笔记,或相关推导补充等。如有错误,还请批评指教。在学习了 Andrew Ng 课程的基础上,为了更方便的查阅复习,将其整理成文字。因本人一直在学习英语,所以该系列以英文为主,同时也建议读者以英文为主,中文辅助,以便后期进阶时,为学习相关领域的学术论文做铺垫。- ZJ
转载请注明作者和出处:ZJ 微信公众号-「SelfImprovementLab」
知乎:https://zhuanlan.zhihu.com/c_147249273
CSDN:http://blog.csdn.net/junjun_zhao/article/details/79077130
1.11 Weight initialization for deep networks (神经网络的权重初始化)
(字幕来源:网易云课堂)

In the last video you saw how very deep neural networks can have the problems of vanishing and exploding gradients. It turns out that a partial solution to this, doesn’t solve it entirely, but helps a lot, is better or more careful choice of the random initialization for your neural network.To understand this, let’s start with the example of initializing the weights for a single neuron and then we’re going to generalize this to a deep network.Let’s go through this with an example with just a single neuron and then we’ll talk about the deep net later.
上节课 我们学习了深度神经网络如何,产生梯度消失和梯度爆炸问题,最终 针对该问题 我们想出了一个不完整的解决方案 虽然不能彻底解决问题,却很有用,有助于我们为神经网络更谨慎地选择随机初始化参数,为了更好地理解它,我们先举一个神经单元权重初始化的例子 然后再演变到整个深度网络,我们来看看只有一个神经元的情况,然后才是深度网络。
So a single neuron you might input four features x1 through x4, and then you have some a=g(z) and end it up with some y, and later on for a deeper net you know these inputs will be right some layer a(l), but for now let’s just call this x for now. So z is going to be equal to w1x1 + w2x2 +… + it goes WnXn and let’s set b=0, so you know lets just ignore b for now. So in order to make z not blow up and not become too small, you notice that the larger n is, the smaller you want Wi to be, right? Because z is the sum of the WiXi, and so if you’re adding up a lot of these terms, you want each of these terms to be smaller. One reasonable thing to do would be to set the variance of Wi to be equal to 1 over n,where n is the number of input features that’s going into a neuron. So in practice, what you can do is set the weight matrix W for a certain layer to be np.random.randn you know, and then whatever the shape of the matrix is for this out here, and then times square root of one over the number of features that I fed into each neuron in layer l so it’s going to be n of (l-1) because that’s the number of units that I’m feeding in to each of the units in layer l.

单个神经元可能有 4 个输入特征 从 X1 到 X4,经过
a=g(z)
处理 最终得到
ŷ
,稍后讲深度网络时 这些输入表示为np.random.randn,这里是矩阵的 shape 函数,再乘以,该层每个神经元的特征数量分之一,即
1/n[l−1]
,这就是
l
层上拟合的单元数量。
It turns out that if you’re using a Relu activation function that rather than 1 over n, it turns out that set in the variance that 2 over n works a little bit better. So you often see that in initialization, especially if you’re using a Relu activation function, so if gl of (z) is ReLu of (z), oh, and it depends on how familiar you are with random variables. It turns out that something, a Gaussian random variable and then multiplying it by a square root of this, that says the variance to be quoted to this thing, to be to 2/n and the reason I went from n to this n superscript l-1 was, in this example with logistic regression which is unable to input features, but in more general case layer l would have n (l-1) inputs each of the units in that layer. So if the input features of activations are roughly mean 0 and standard variance and variance 1 then this would cause z to also take on a similar scale and this doesn’t solve, but it definitely helps reduce the vanishing, exploding gradients problem because it’s trying to set each of the weight matrices w you know so that it’s not too much bigger than 1, and not too much less than 1, so it doesn’t explode or vanish too quickly.

结果 如果你用的是 Relu 激活函数 而不是 1/n,方差设置为 2/n 效果会更好,你常常发现初始化时,尤其是使用 Relu 激活函数时,
I’ve just mention some other variants.The version we just described is assuming a Relu activation function, and this by a paper by Herd et al.. A few other variants, if you are using a TanH activation function, then there’s a paper that shows that instead of using the constant 2,it’s better use the constant 1,and so 1 over this, instead of 2, and so you multiply it by the square root of this. So this square root term will plays this term and you use this if you’re using a TanH activation function. This is called Xavier initialization. And another version we’re taught by Yoshua Bengio and his colleagues, you might see in some papers, but is to use this formula, which you know has some other theoretical justification, but I would say if you’re using a Relu activation function, which is really the most common activation function, I would use this formula. If you’re using TanH, you could try this version instead, and some authors will also use this, but in practice,I think all of these formulas just give you a starting point, it gives you a default value to use for the variance of the initialization of your weight matrices. If you wish the variance here, this variance parameter could be another thing that you could tune of your hyperparameters, so you could have another parameter that multiplies into this formula and tune that multiplier as part of your hyperparameter surge.
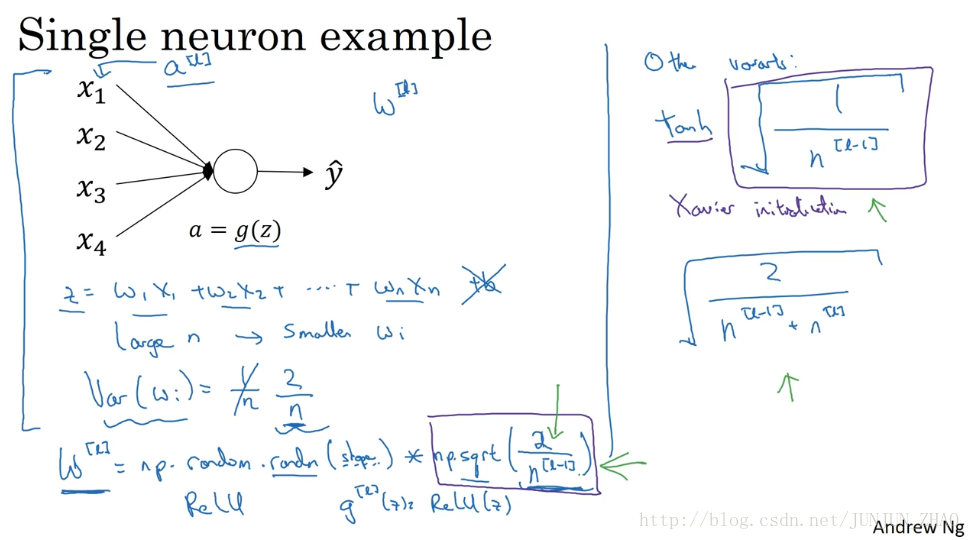
我提到了其它变体函数,刚刚提到的函数是 Relu 激活函数,一篇由 Herd 等人撰写的论文曾介绍过,对于几个其它变体函数,如 Tanh 激活函数,有篇论文提到,常量 1 比常量 2 的效率更高,对于 tanh 函数来说 它是 1/n[l−1] 的平方根,这里平方根的作用与这个公式作用相同,它适用于 Tanh 激活函数,被称为 Xavier 初始化,Yoshua Bengio 和他的同事还提出另一种方法,你可能在一些论文中看到过,他们使用的是公式 2n[l−1]+n[l] 的平方根,其它理论已对此证明,但如果你想用 Relu 激活函数,也就是最常用的激活函数,我会用这个公式 np.sqrt( 2n[l−1] ),如果使用 TanH 函数 可以用公式 1n[l−1]−−−−−√ ,有些作者也会使用这个函数,实际上 我认为所有这些公式只是给你一个起点,它们给出初始化权重矩阵的方差的默认值,如果你想添加方差,方差参数则是另一个你需要调整的超级参数,可以给公式 np.sqrt( 2n[l−1] )添加一个乘数参数,调优作为超级参数激增一份子的乘子参数。
Sometimes tuning the hyperparameter has a modest size effect. It’s not one of the first hyperparameters I would usually try to tune, but I’ve also seen some problems with tuning this you know helps a reasonable amount, but this is usually lower down for me in terms of how important it is relative to the other hyperparameters you can tune. So I hope that gives you some intuition about the problem of vanishing or exploding gradients, as well as how choosing a reasonable scaling for how you initialize the weights. Hopefully that makes your weights, you know not explode too quickly and not decay to zero too quickly so you can train a reasonably deep network without the weights or the gradients exploding or vanishing too much. When you train deep networks this is another trick that will help you make your neural networks trained much more quickly.
有时调优该超级参数效果一般,这并不是我想调优的首要超级参数,但我已经发现调优过程中产生的问题,虽然调优该参数能起到一定作用,但考虑到相比调优其它超级参数的重要性,我通常把它的优先级放得比较低,希望现在你对梯度消失或爆炸问题,以及如何为权重矩阵初始化合理值已经有了一个直观认识,希望你设置的权重矩阵 既不会增长过快 也不会太快下降到 0,从而训练出一个,权重或梯度不会增长或消失过快的深度网络,我们在训练深度网络时,这也是一个加快训练速度的技巧。
重点总结:
利用初始化缓解梯度消失和爆炸问题
以一个单个神经元为例子:
由上图可知,当输入的数量n较大时,我们希望每个wi的值都小一些,这样它们的和得到的z也较小。
这里为了得到较小的 wi ,设置 Var(wi)=1n ,这里称为 Xavier initialization。
对参数进行初始化:
WL = np.random.randn(WL.shape[0],WL.shape[1])* np.sqrt(1/n)这么做是因为,如果激活函数的输入x近似设置成均值为0,标准方差1的情况,输出z也会调整到相似的范围内。虽然没有解决梯度消失和爆炸的问题,但其在一定程度上确实减缓了梯度消失和爆炸的速度。
不同激活函数的 Xavier initialization:
激活函数使用 Relu:
Var(wi)=2n
激活函数使用 tanh:
Var(wi)=1n
其中 n 是输入的神经元个数,也就是 n[l−1]。
参考文献:
[1]. 大树先生.吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(2-1)– 深度学习的实践方面
PS: 欢迎扫码关注公众号:「SelfImprovementLab」!专注「深度学习」,「机器学习」,「人工智能」。以及 「早起」,「阅读」,「运动」,「英语 」「其他」不定期建群 打卡互助活动。
















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









