









1.RANSAC 原理
就是首先随机抽取观测数据子集,我们假设视为这子集就是“内点”(局内点或者局内数据)。然后用这子集进行相关的拟合来计算模型参数(或者估计函数)。找到这模型(或者函数)以后,利用观测点(数据)进行是否正确,如果求出来的模型能够满足足够多的数据,我们视为很正确的数据。最后我们采纳。但是,如果不适合,也就是说求出来的模型(或者函数,也可以是模型参数)满足的数据点很少,我们就放弃,从新随机抽取观测数据子集,再进行上述的操作。这样的运算进行N次,然后进行比较,如果第M(M<N)次运算求出来的模型满足的观测数据足够多的话,我们视为最终正确的模型(或者称之为正确地拟合函数)。可见,所谓的随机抽样一致性算法很适合对包含很多局外点(噪声,干扰等)的观测数据的拟合以及模型参数估计。当然最小二乘法也是不错的算法,但是,最小二乘法虽然功能强大,不过,它所适合的范围没有RANSAC那么广。
2.SURF算法与ransac算法相结合
(1)从SURF 算法预匹配数据集中随机取出一些匹配点对,计算出变换矩阵H,记为模型M。理论上只需要4对点。
(2)计算数据集中所有数据与模型M的投影误差,若误差小于阈值,加入内点集 I ;
(3)如果当前内点集 I 元素个数大于最优内点集 I_best , 则更新 I_best = I,同时更新迭代次数k ;
(4) 如果迭代次数大于k,则退出 ; 否则迭代次数加1,并重复上述步骤;
注:在OpenCV中迭代次数k在不大于最大迭代次数的情况下,是在不断更新而不是固定的;
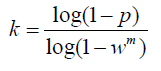
其中,p为置信度,一般取0.995;w为”内点”的比例 ; m为计算模型所需要的最少样本数=4;
在opencv里,findFundamentalMat函数来得到变换模型。
3.RANSAC源码解析
(1)cv::findFundamentalMat()返回一个基础矩阵。
_points1:图像1的坐标点
_points2:图像2的坐标点
cv::Mat cv::findFundamentalMat( InputArray _points1, InputArray _points2,
int method, double param1, double param2,
OutputArray _mask )
{
Mat points1 = _points1.getMat(), points2 = _points2.getMat();
int npoints = points1.checkVector(2);
CV_Assert( npoints >= 0 && points2.checkVector(2) == npoints &&
points1.type() == points2.type());
Mat F(method == CV_FM_7POINT ? 9 : 3, 3, CV_64F);
CvMat _pt1 = points1, _pt2 = points2;
CvMat matF = F, c_mask, *p_mask = 0;
if( _mask.needed() )
{
_mask.create(npoints, 1, CV_8U, -1, true);
p_mask = &(c_mask = _mask.getMat());
}
int n = cvFindFundamentalMat( &_pt1, &_pt2, &matF, method, param1, param2, p_mask );//见(2)
if( n <= 0 )
F = Scalar(0);
if( n == 1 )
F = F.rowRange(0, 3);
return F;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
(2)cvFindFundamentalMat()返回一个整数值
CV_IMPL int cvFindFundamentalMat( const CvMat* points1, const CvMat* points2,
CvMat* fmatrix, int method,
double param1, double param2, CvMat* mask )
{
int result = 0;
Ptr<CvMat> m1, m2, tempMask;
double F[3*9];
CvMat _F3x3 = cvMat( 3, 3, CV_64FC1, F ), _F9x3 = cvMat( 9, 3, CV_64FC1, F );
int count;
CV_Assert( CV_IS_MAT(points1) && CV_IS_MAT(points2) && CV_ARE_SIZES_EQ(points1, points2) );
CV_Assert( CV_IS_MAT(fmatrix) && fmatrix->cols == 3 &&
(fmatrix->rows == 3 || (fmatrix->rows == 9 && method == CV_FM_7POINT)) );
count = MAX(points1->cols, points1->rows);
if( count < 7 )
return 0;
m1 = cvCreateMat( 1, count, CV_64FC2 );
cvConvertPointsHomogeneous( points1, m1 );
m2 = cvCreateMat( 1, count, CV_64FC2 );
cvConvertPointsHomogeneous( points2, m2 );
if( mask )
{
CV_Assert( CV_IS_MASK_ARR(mask) && CV_IS_MAT_CONT(mask->type) &&
(mask->rows == 1 || mask->cols == 1) &&
mask->rows*mask->cols == count );
}
if( mask || count >= 8 )
tempMask = cvCreateMat( 1, count, CV_8U );
if( !tempMask.empty() )
cvSet( tempMask, cvScalarAll(1.) );
CvFMEstimator estimator(7);
if( count == 7 )
result = estimator.run7Point(m1, m2, &_F9x3);
else if( method == CV_FM_8POINT )
result = estimator.run8Point(m1, m2, &_F3x3);
else
{
if( param1 <= 0 )
param1 = 3;
if( param2 < DBL_EPSILON || param2 > 1 - DBL_EPSILON )
param2 = 0.99;
if( (method & ~3) == CV_RANSAC && count >= 15 )
result = estimator.runRANSAC(m1, m2, &_F3x3, tempMask, param1, param2 );//在数据点数大于15个时才调用ransac方法见(3)
else
result = estimator.runLMeDS(m1, m2, &_F3x3, tempMask, param2 );
if( result <= 0 )
return 0;
/*icvCompressPoints( (CvPoint2D64f*)m1->data.ptr, tempMask->data.ptr, 1, count );
count = icvCompressPoints( (CvPoint2D64f*)m2->data.ptr, tempMask->data.ptr, 1, count );
assert( count >= 8 );
m1->cols = m2->cols = count;
estimator.run8Point(m1, m2, &_F3x3);*/
}
if( result )
cvConvert( fmatrix->rows == 3 ? &_F3x3 : &_F9x3, fmatrix );
if( mask && tempMask )
{
if( CV_ARE_SIZES_EQ(mask, tempMask) )
cvCopy( tempMask, mask );
else
cvTranspose( tempMask, mask );
}
return result;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
(3)
maxIters:最大迭代次数
m1,m2 :数据样本
model:变换矩阵
reprojThreshold:投影误差阈值 3
confidence:置信度 0.99
bool CvModelEstimator2::runRANSAC( const CvMat* m1, const CvMat* m2, CvMat* model,
CvMat* mask0, double reprojThreshold,
double confidence, int maxIters )
{
bool result = false;
cv::Ptr<CvMat> mask = cvCloneMat(mask0);
cv::Ptr<CvMat> models, err, tmask;
cv::Ptr<CvMat> ms1, ms2;
int iter, niters = maxIters;
int count = m1->rows*m1->cols, maxGoodCount = 0;
CV_Assert( CV_ARE_SIZES_EQ(m1, m2) && CV_ARE_SIZES_EQ(m1, mask) );
if( count < modelPoints )
return false;
models = cvCreateMat( modelSize.height*maxBasicSolutions, modelSize.width, CV_64FC1 );
err = cvCreateMat( 1, count, CV_32FC1 );//保存每组点对应的投影误差
tmask = cvCreateMat( 1, count, CV_8UC1 );
if( count > modelPoints ) //多于4个点
{
ms1 = cvCreateMat( 1, modelPoints, m1->type );
ms2 = cvCreateMat( 1, modelPoints, m2->type );
}
else //等于4个点
{
niters = 1; //迭代一次
ms1 = cvCloneMat(m1); //保存每次随机找到的样本点
ms2 = cvCloneMat(m2);
}
for( iter = 0; iter < niters; iter++ ) //不断迭代
{
int i, goodCount, nmodels;
if( count > modelPoints )
{
//在(4)解析getSubset
bool found = getSubset( m1, m2, ms1, ms2, 300 ); //随机选择4组点,且三点之间不共线,见(4),最大迭代次数300
if( !found )
{
if( iter == 0 )
return false;
break;
}
}
nmodels = runKernel( ms1, ms2, models ); //估算近似变换矩阵,返回1 见(7)
if( nmodels <= 0 )
continue;
for( i = 0; i < nmodels; i++ )//执行一次
{
CvMat model_i;
cvGetRows( models, &model_i, i*modelSize.height, (i+1)*modelSize.height );//获取3×3矩阵元素
goodCount = findInliers( m1, m2, &model_i, err, tmask, reprojThreshold ); //找出内点,(5)解析
if( goodCount > MAX(maxGoodCount, modelPoints-1) ) //当前内点集元素个数大于最优内点集元素个数
{
std::swap(tmask, mask);
cvCopy( &model_i, model ); //更新最优模型
maxGoodCount = goodCount;
//confidence 为置信度默认0.995,modelPoints为最少所需样本数=4,niters迭代次数
niters = cvRANSACUpdateNumIters( confidence, //更新迭代次数,(6)解析
(double)(count - goodCount)/count, modelPoints, niters );
}
}
}
if( maxGoodCount > 0 )
{
if( mask != mask0 )
cvCopy( mask, mask0 );
result = true;
}
return result;
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
(4)getSubset()得到子集
bool CvModelEstimator2::getSubset( const CvMat* m1, const CvMat* m2,
CvMat* ms1, CvMat* ms2, int maxAttempts )
{
cv::AutoBuffer<int> _idx(modelPoints); //modelPoints 所需要最少的样本点个数
int* idx = _idx;
int i = 0, j, k, idx_i, iters = 0;
int type = CV_MAT_TYPE(m1->type), elemSize = CV_ELEM_SIZE(type);
const int *m1ptr = m1->data.i, *m2ptr = m2->data.i;
int *ms1ptr = ms1->data.i, *ms2ptr = ms2->data.i;
int count = m1->cols*m1->rows;
assert( CV_IS_MAT_CONT(m1->type & m2->type) && (elemSize % sizeof(int) == 0) );
elemSize /= sizeof(int); //每个数据占用字节数
for(; iters < maxAttempts; iters++)
{
for( i = 0; i < modelPoints && iters < maxAttempts; )
{
idx[i] = idx_i = cvRandInt(&rng) % count; // 随机选取1组点
for( j = 0; j < i; j++ ) // 检测是否重复选择
if( idx_i == idx[j] )
break;
if( j < i )
continue; //重新选择
for( k = 0; k < elemSize; k++ ) //拷贝点数据
{
ms1ptr[i*elemSize + k] = m1ptr[idx_i*elemSize + k];
ms2ptr[i*elemSize + k] = m2ptr[idx_i*elemSize + k];
}
if( checkPartialSubsets && (!checkSubset( ms1, i+1 ) || !checkSubset( ms2, i+1 )))//检测点之间是否共线
{
iters++; //若共线,重新选择一组
continue;
}
i++;
}
if( !checkPartialSubsets && i == modelPoints &&
(!checkSubset( ms1, i ) || !checkSubset( ms2, i )))
continue;
break;
}
return i == modelPoints && iters < maxAttempts; //返回找到的样本点个数
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
(5)findInliers()找内点
int CvModelEstimator2::findInliers( const CvMat* m1, const CvMat* m2,
const CvMat* model, CvMat* _err,
CvMat* _mask, double threshold )
{
int i, count = _err->rows*_err->cols, goodCount = 0;
const float* err = _err->data.fl;
uchar* mask = _mask->data.ptr;
computeReprojError( m1, m2, model, _err ); //计算每组点的投影误差
threshold *= threshold;
for( i = 0; i < count; i++ )
goodCount += mask[i] = err[i] <= threshold;//误差在限定范围内,加入‘内点集’
return goodCount;
}
//--------------------------------------
void CvHomographyEstimator::computeReprojError( const CvMat* m1, const CvMat* m2,const CvMat* model, CvMat* _err )
{
int i, count = m1->rows*m1->cols;
const CvPoint2D64f* M = (const CvPoint2D64f*)m1->data.ptr;
const CvPoint2D64f* m = (const CvPoint2D64f*)m2->data.ptr;
const double* H = model->data.db;
float* err = _err->data.fl;
for( i = 0; i < count; i++ ) //保存每组点的投影误差,对应上述变换公式
{
double ww = 1./(H[6]*M[i].x + H[7]*M[i].y + 1.);
double dx = (H[0]*M[i].x + H[1]*M[i].y + H[2])*ww - m[i].x;
double dy = (H[3]*M[i].x + H[4]*M[i].y + H[5])*ww - m[i].y;
err[i] = (float)(dx*dx + dy*dy);
}
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
(6)cvRANSACUpdateNumIters
对应上述k的计算公式
p:置信度
ep:外点比例
cvRANSACUpdateNumIters( double p, double ep,
int model_points, int max_iters )
{
if( model_points <= 0 )
CV_Error( CV_StsOutOfRange, "the number of model points should be positive" );
p = MAX(p, 0.);
p = MIN(p, 1.);
ep = MAX(ep, 0.);
ep = MIN(ep, 1.);
// avoid inf's & nan's
double num = MAX(1. - p, DBL_MIN); //num=1-p,做分子
double denom = 1. - pow(1. - ep,model_points);//做分母
if( denom < DBL_MIN )
return 0;
num = log(num);
denom = log(denom);
return denom >= 0 || -num >= max_iters*(-denom) ?
max_iters : cvRound(num/denom);
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
(7)
int cv::Affine3DEstimator::runKernel( const CvMat* m1, const CvMat* m2, CvMat* model )
{
const Point3d* from = reinterpret_cast<const Point3d*>(m1->data.ptr);
const Point3d* to = reinterpret_cast<const Point3d*>(m2->data.ptr);
Mat A(12, 12, CV_64F);
Mat B(12, 1, CV_64F);
A = Scalar(0.0);
for(int i = 0; i < modelPoints; ++i)
{
*B.ptr<Point3d>(3*i) = to[i];
double *aptr = A.ptr<double>(3*i);
for(int k = 0; k < 3; ++k)
{
aptr[3] = 1.0;
*reinterpret_cast<Point3d*>(aptr) = from[i];
aptr += 16;
}
}
CvMat cvA = A;
CvMat cvB = B;
CvMat cvX;
cvReshape(model, &cvX, 1, 12);
cvSolve(&cvA, &cvB, &cvX, CV_SVD );//基于奇异值分解的最小二乘法
return 1;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 本文已收录于以下专栏:
- 计算机视觉















 1121
1121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









