







1. SQL语句的执行过程
解析:数据库解析器会将语句解析成解析树。
预处理:检查语法、权限、表的存在性
优化:优化器生成执行计划,选择最有效的查询策略
执行:按照执行计划查询后返回结果
2. MySQL的长连接与短连接
短连接:每次数据库操作后,连接立刻关闭。
可节约占用服务器资源的时间
长连接:允许连接一次数据库,进行多次操作。
适合高并发,可节约 连接与断开 的开销
3. ping命令在哪一层,用的什么协议?
ping命令在网络层,用的是ICMP协议。
4. UDP如何保证可靠传输?
1. 重传:应用层检测丢包并重传
2. 确认应答:接收端发送确认消息,表明成功接收
3. 顺序控制:检测序列号
4. 流量控制:控制发送速度,防止接收端过载
5. linux查看端口占用情况用什么命令?
netstat -tuln:显示所有监听的端口和使用的协议
ss -tuln:功能与netstat一样,但可能更快
netstat -anp | grep <端口号>:显示指定端口详细信息
6. C++从一堆数中查找最大的10个数,应该怎么找?
维护一个大小为10的最小堆,遍历一遍所有数:
如果堆未满,则将其插入堆中。
如果堆已满 且 当前数字大于堆顶元素,则将其插入,并重新排列堆。
7. 把用户数据复制到磁盘需要经历哪些缓冲区
用户缓冲区:数据最初在应用程序的内存中
内核区缓冲区:
页缓存:数据从用户区复制到内核区,为了提高磁盘I/O性能
I/O缓冲区:再页缓存中进一步处理数据,准备写入磁盘
磁盘控制器缓存:数据从内核区缓存到控制器的缓存中,进一步提高写入效率
磁盘:最终被写到物理介质上
8. 如果cpu利用率过高,你会怎么排查问题?
1. 使用gprof分析性能瓶颈
gprof my_program gmon.out > analysis.txt2. 检查线程和并发,看是否存在竞争和死锁问题
3. 用top监控系统资源,看是否有其他进程占用CPU
4. 检查I/O操作,确保没有导致CPU过度等待
9. mmap主要用来做什么?
1. 文件映射:将文件内容映射进虚拟地址,可以向操作内存一样操作文件,提高访问率
2. 共享内存:实现线程间通信
3. 处理大数据集:通过内存映射避免大文件的显式读写,提高效率
10. 操作系统:windows和linux用的什么任务调度算法?
-
Windows:使用基于优先级的抢占式调度算法。具体来说,Windows 10 和 Windows Server 采用了类似于“多级反馈队列”的算法,其中每个线程都有一个优先级,系统会根据线程的优先级和当前的 CPU 使用情况来决定调度。
-
Linux:主要使用“完全公平调度器”(CFS)。CFS 是一种基于红黑树的数据结构实现的调度算法,旨在确保所有进程公平地共享 CPU 时间。它会动态调整进程的调度优先级,以实现高效和公平的任务调度
11. 子网掩码
子网掩码指的是一串二进制数据,前1后0, 1的部分为主机,0的部分为子网地址。
判断网络是否处于同一网络:将网络地址与子网掩码相与得到主机地址,判断是否一致。
12. 六大排序
| 名称 | 时间复杂度 | 是否稳定 | 适用情况 |
| 选择排序 | O(n^2) | 不稳定 | 数据量小 |
1. 选择排序:
void insertSort(vector<int> &nums) {
int n = nums.size();
for(int i = 0; i < n-1; i++) {
int end = i;//有序序列最后一个元素的下标
int tmp = nums[i+1];//待插入元素
while(end >= 0) {
//如果当前数比插入的数要大,则当前数向后移动
if(tmp < nums[end]) {
nums[end+1] = nums[end];
end--;
} else {
break;
}
}
nums[end+1] = tmp;//插入当前数
}
}
13. 折半查找 与 二叉搜索树BST
折半查找:用于已排序的序列,每次查找的范围减半。通过比较中间值和目标大小确定新的范围。
BST二叉搜索树:每个节点左子树都比自己小,右子树都比自己大。BST平均查找O(logn)
14. B树、B+树
15. 数据库五大范式
1NF:确保每列中的数据都是原子性的,消除重复的列。
2NF:在满足1NF的基础上,每个非主键属性必须依赖于主键。
3NF:在满足2NF的基础上,非主属性不能依赖于其他非主属性。
4NF:在满足3NF的基础上,确保一个关系的多值依赖不会影响其他数据。
5NF:在满足4NF的基础上,确保每个关系都无法再分解。为了保持数据完整性。
16. 缺页是操作系统如何处理?
缺页指进程访问一个不在内存中的虚拟页面。
处理:当发生缺页时,CPU会触发缺页异常
暂停进程,并查找缺页的存储位置
将所需页面替换进来,如果页面已满则利用FIFO、LRU和LFU替换, 更新页面表
恢复进程
17. MySQL索引
索引指index,通过索引可以快速查询到某个记录。
MySQL的数据索引采用B+树结构,时间复杂度O(log n)。
18. 什么是饥饿现象?
指的是某些进程一直得不到资源的情况。
解决策略:
1.老化:系统会逐渐提升等待久的进程的优先级
2.时间片转移:进程被分配固定的时间片执行,时间到后,会直接中断进程
3.抢占短作业优先:估计执行最短的进程,如果有更短的进程来,则抢占正在执行的进程
无效策略:
1.静态优先:各个进程的优先级固定,不会改变。系统依照优先级调度。
2.非抢占作业优先:一个进程开始执行,除非完成或主动等待,否则不释放资源。
19. IP数据报文尽最大努力交付是什么意思?
1.无连接性:IP协议不建立连接
2.不保证性:数据包可能丢失、重复、乱序,或传输中受损。
3.尽力而为:数据包可能不送达。
20. 进程有几种状态,在什么时候向PCB写入管理信息?
(五种:创建态、就绪态、运行态、阻塞态、终止态)
在进程创建态时写入PCB管理信息。
21. FCFS算法、SJF算法、平均带权周期时间
FCFS(First Come First Service)算法:先来先服务。
按照进程到达的顺序进行调度,先到达的进程优先执行。
FCFS优点:公平。
FCFS缺点:当长作业在前,短作业在后,容易“饥饿”。
SJF(Shortest Job First ):短作业优先。
运行估计执行时间最短的进程。
SJF优点:减少“饥饿”。
SJF缺点:长作业可能会被一直延迟,造成“饥饿”。

22. (命令)如何计算一个txt的单词数
使用wc -w命令查询一个txt文件中的单词数量
wc命令:用于查询TXT文件中的指定类型数目
| 选项 | 解释 |
| -w | 单词数 |
| -c | 字节数 |
| -l | 行数 |
| -m | 字符数 |
| -L | 最长行的长度 |
23. Prim算法、Kruskal(克鲁斯卡尔)算法
二者均是用于寻找加权无向图的最小生成树MST。
(最小生成树:边权重和最小的连通图)
Prim算法思想:
(首先将所有顶点分为2个集合: 已遍历顶点 和 未遍历顶点)
1. 先从一个顶点出发(将第一个顶点加入 已遍历顶点)
2. 寻找 已遍历顶点 通向一个 未遍历顶点 的权值最小的边,将其加入 已遍历顶点 中
3. 再次重复上述操作,直到所有顶点都加入 已遍历顶点 集合
Kruskal算法思想:
(首先将所有边排序从小到大排序)
1. 依次选择权值最小的边,如果构成回路则舍弃此边
2. 直到所有顶点都被遍历。
24. Dijkstra(迪杰斯特拉)算法、图的存储方式
25. 广播地址IP有什么特点?
广播地址就是子网地址全为1的IP地址。
(他是和子网掩码配合使用的,比如子网掩码是255.255.255.0
那么192.168.3.255就是一个广播地址)
26. 如何通过ack和seq的值知道在Close-Wait阶段发送了多少字节?
ack - seq可以预测close
27. 程序装入内存的方式
4种方式
静态载入:编译时,载入内存
动态载入:运行时,载入内存
分页载入:将程序分割成固定大小的页面,载入内存(允许非连续物理内存分配)
分段装入:将程序分为不同段(代码段,全局区,堆,栈),按需载入内存。
28. MySQL 的 Innodb引擎的自适应哈希索引功能,对索引字段使用哪些运算符关键字,不会造成索引失效的有哪些?
不会失效:
=、>、>=、<、<=、IN、BETWEEN、LIKE(不带通配符)
会索引失效:
!=或<>、函数调用、类型转换、OR、LIKE(带通配符)
29. 路由器和交换机有啥区别
| 路由器 | 交换机 | |
| 工作层 | 网络层 | 数据链路层 |
| 连接 | 用于不同网络间的数据转换 | 用于同一网络中的数据交换 |
| 寻址方式 | 通过路由表确定 | 通过数据帧中的MAC地址确定 |
| Net | 一般:广域网(WAN) | 一般:局域网(LAN) |
30. 进程与线程的区别
| 进程 | 线程 | |
| 概念 | 操作系统调度的基本单位 | CPU资源分配的基本单位 |
| 调度 | 上下文切换开销大 | 上下文切换开销小 |
| 开销 | 创建、销毁 开销大 | 创建、销毁 开销小 |
| 资源共享 | 每个进程有独立的地址空间和数据栈 | 同一进程下的线程共享地址空间 但也有自己的 栈 和 寄存器 |
31. 进程间通信方式
管道、共享内存、消息队列、信号量、套接字、屏障
屏障:一种同步机制,多个进程在到达某个点时必须等待,只有当所有进程都到达后才能继续执行
32. 线程间通信方式
共享变量(全局变量)、条件变量、读写锁、互斥锁
33. float和double数值相等比较结果
false
34. 设计模式的三大类
-
创建型模式:
- 这些模式涉及对象的创建,帮助提高对象创建的灵活性和可复用性。
- 主要模式包括:
- 单例模式(Singleton)
- 工厂方法模式(Factory Method)
- 抽象工厂模式(Abstract Factory)
- 建造者模式(Builder)
- 原型模式(Prototype)
-
结构型模式:
- 这些模式关注于对象的组合,帮助简化复杂结构。
- 主要模式包括:
- 适配器模式(Adapter)
- 装饰者模式(Decorator)
- 代理模式(Proxy)
- 外观模式(Facade)
- 组合模式(Composite)
- 桥接模式(Bridge)
- 享元模式(Flyweight)
-
行为型模式:
- 这些模式关注对象之间的通信和职责分配。
- 主要模式包括:
- 策略模式(Strategy)
- 观察者模式(Observer)
- 迭代器模式(Iterator)
- 责任链模式(Chain of Responsibility)
- 命令模式(Command)
- 状态模式(State)
- 模板方法模式(Template Method)
- 访问者模式(Visitor)
35. 同步传输和异步传输
同步传输:发送方和接收方在传输数据时使用相同的时钟信号。数据在特定的时钟信号下被发送和接收,确保数据的时序一致。长度固定。(TCP)
异步传输:发送和接收双方不使用统一的时钟信号,而是通过特定的控制信号(如起始位和停止位)来标识数据的开始和结束。长度不固定。(UDP)
36. MySQL事务
事务指的是一些操作的组合,要么全部执行,要么全部不执行。事务满足以下四个属性:
原子性、一致性、隔离性、持久性
事务的隔离级别(四种):
- READ UNCOMMITTED:允许读取未提交的数据,可能导致脏读。
- READ COMMITTED:只读取已提交的数据,防止脏读,但可能发生不可重复读。
- REPEATABLE READ:在同一事务中多次读取相同数据结果一致,防止脏读和不可重复读,但可能出现幻读。
- SERIALIZABLE:最高隔离级别,完全隔离所有事务,防止所有并发问题,但性能较低
37. 脏读和幻读、不可重复读
脏读:一个事务读取了另一个未提交事务的数据。
幻读:一个事务在多次查询时,因另一个事务的插入或删除导致查询结果发生变化。
不可重复读:一个事物由于并发,导致多次读取同一个数据的结果不一致
38. 哈夫曼树、带权平均路径长度、哈弗曼编码
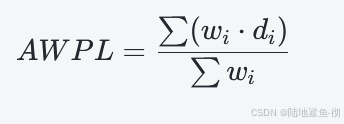
哈夫曼树:权重大结点的靠近根。编码仅在叶子结点。
哈夫曼编码:左0右1 或 左1右0 均可。
39. DNS解析时,英文区分大小写吗
不区分
40. web wervice发布占用端口号多少?
HTTP Web Service占用端口号80
HTTPS Web Service占用端口号443
41. 端口范围
0 - 65535
42. SQL的JOIN
外连接:LEFT JOIN、RIGHT JOIN
内连接:INNER JOIN
43. CLOCK页面置换
CLOCK页面置换是一种改进的页面替换算法,用于管理计算机内存中的页面。当内存已满且需要加载新页面时,CLOCK算法通过一个循环指针遍历页面,检查每个页面的使用位
44.进程与线程的区别
1. 进程是操作系统(OS)资源分配的基本单位,线程是CPU任务调度与执行的基本单位。
2. 每个进程都有独立的代码和数据空间,程序之间切换的开销较大
每一类线程共享代码与数据空间,每个线程都有自己独立的运行栈和程序计数器,开销较小。
3. 进程的健壮性更强:一个进程崩溃,在保护模式下,不会对其他进程造成影响
但一个线程崩溃,会导致整个进程都死掉
4.每个进程都可以独立运行,有程序运行的入口和出口。
但线程不能独立运行,必须存在于应用程序中。
45. fork创建的是进程还是线程?
进程
46. 常用设计模式
设计模式是为了实现: 高内聚,低耦合
单例模式:构造函数私有化,用一个静态函数获取静态变量
懒汉:在getInstance里new
饿汉:在类外直接new初始化
工厂模式:
给一个produce函数,根据所传参数new不用的子类,返回父类指针
代理模式:
一个只有纯虚函数的抽象父类,子类继承后重写纯虚函数。
代理类有一个父类指针,通过构造函数传入子类对象,并通过父类指针调用子类虚函数。
观察者模式:
建立一种一对多的依赖关系,使得当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并自动更新
接口适配器模式:
将需要实现的功能用虚函数写在父类中,不同的子类重写所需的虚函数。
(但接口都是父类指针的类型)
策略模式:
创建一个类维护一个父类指针,通过构造函数传入不同的子类对象,调用不同的子类虚函数
装饰模式:
做一个装饰器类继承父类,装饰器类中有一个父类指针成员。
重写父类的纯虚函数,在“通过父类指针调用子类虚函数”的基础上,其中添加自己想要的内容
47. pipe函数如何使用?
看以下代码具体理解一下:
#include <iostream>
#include <unistd.h> // pipe, fork, write, read
#include <cstring> // memset
int main() {
int pipefd[2]; // 创建管道的文件描述符
pid_t pid;
char buffer[100];
// 创建管道
if (pipe(pipefd) == -1) {
perror("pipe");
return 1;
}
// 创建子进程
pid = fork();
if (pid == -1) {
perror("fork");
return 1;
}
if (pid == 0) { // 子进程
close(pipefd[1]); // 关闭写端
// 从管道读取数据
ssize_t bytesRead = read(pipefd[0], buffer, sizeof(buffer));
if (bytesRead > 0) {
buffer[bytesRead] = '\0'; // 添加字符串结束符
std::cout << "Child process received: " << buffer << std::endl;
}
close(pipefd[0]); // 关闭读端
} else { // 父进程
close(pipefd[0]); // 关闭读端
// 向管道写入数据
const char* message = "Hello from parent!";
write(pipefd[1], message, strlen(message));
close(pipefd[1]); // 关闭写端
}
return 0;
}
以上代码的解释:
-
创建管道:使用
pipe(pipefd)创建一个管道,pipefd[0]是读端,pipefd[1]是写端。 -
创建子进程:使用
fork()创建一个新的进程。 -
子进程操作:
- 关闭写端
pipefd[1]。 - 从管道读数据并打印。
- 关闭写端
-
父进程操作:
- 关闭读端
pipefd[0]。 - 向管道写入消息。
- 关闭读端
-
关闭管道:在每个进程结束时,关闭相应的管道端,防止资源泄露。
47. 同或
x 同或 y = ~(x^y);
48. malloc可以为一个类申请空间吗?
不可以。
原因:malloc不执行构造函数,因此无法为一个类申请空间。同时当一个结构体包含类成员时,也无法用malloc进行申请
49. 为什么一个线程崩溃,其余的线程没有崩溃?
原因:1. 线程可能发生的是内存越界,此时其他线程未收到影响。
2. 通过异常机制进行捕获,不会影响其他线程。
50. 但单核电脑CPU利用率很低,但此时有很多进程,可能是什么原因?
程序可能在等待磁盘I/O或者网络I/O操作完成,此时cpu是空闲的。
51. 流媒体如何保证低延迟传输?
1. 设置接收缓冲区,并动态调整大小
2. 控制发送速率,避免丢包
3. 当检测到丢包时重传
4.采用I/O多路复用,减少主线程的阻塞时间,提高性能
5. 在网络层部署QoS策略(如WebRTC),在带宽优先的前提下保证实时传输质量。
52. linux如何检测自己的程序发生内存泄漏或死锁?
使用valgrind工具
检测内存泄漏: valgrind --leak-check=full ./pro
检测死锁: valgrind --tool=helgrind ./pro
53. 32位系统移植到64位系统需要注意什么?
1. 指针位数发生变化
2. 64位地址空间更大,确保程序中没有依赖特定的硬编码地址。
3. 检查结构体和类的内存对齐,64位下可能占用更多内存。
4. 检查依赖库
54. 死锁的四个条件
1. 互斥条件:如果某个共享资源被一个线程占用,其他线程必须等待
2. 请求等待:一个线程等待资源,而这个资源已经被其他线程占据
3. 不可剥夺:已经占有资源的线程除非自己释放,否则不放开资源
4. 循环等待:每个线程都在等待另一个线程已经持有的资源
55. 红黑树
C++中的map、set底层都是红黑树,它是一种AVL(平衡二叉树),增 删 查时间复杂度O(logn)
特点:
1. 节点是黑色或者红色
2. 根节点是黑色
3.没有两个红色节点相联:红色节点的子节点必须是黑色
4. 从任何节点到每个叶子节点的所有路径包含相同数量的黑色节点。
(它保证了从根到叶子的最长路径不会超过最短路径的两倍,从而确保树的平衡性。)
5. 每个叶子节点(空节点)被视为黑色。这些叶子节点不实际存储数据,通常用 nullptr 表示。
对比AVL:
与 AVL 树相比,红黑树在插入和删除操作上通常更快,因为它们进行的旋转次数较少
56. C++什么情况下使用函数指针?
一般是回调函数的时候
57. 什么是僵尸进程和孤儿进程?
僵尸进程:指已经完成执行,但父进程未调用wait()或waitpid()读取。它依旧会在进程表中留下一 些信息,直到父进程读取它。
孤儿进程:父进程已经执行完毕,而子进程还在运行。此时子进程会被操作系统的init进程收养,并继续执行防止内存泄漏。
58. 什么时候会用到二级指针?
动态申请二维数组,修改指针的值。
59. 面向过程比面向对象有哪些优势?
抽象少、前期编码量少、便于调试,适合小程序开发
60. 用户态和内核态的区别?
1. 内核态可以执行特权指令,用户态不可以。
2. 内核态可以访问系统资源与硬件驱动,用户态只能访问自己的空间。
3. 内核态的上下文切换速度慢,用户态的上下文切换速度快
61. DNS查询顺序
1. 本地缓存:DNS解析器首先会检查本地缓存中是否存在,如果命中则返回结果。
2. 根DNS服务器:如果本地无缓存,查询将被发送到根DNS服务器。根服务器将其引导至对应
的顶级域,如.com、.cn等。
3.顶级域名服务器(TLD):TLD会返回负责该域名的权威DNS服务器地址,如baidu.com等。
4.权威DNS服务器:查询被发送至权威域名服务器,如果这个服务器有记录,则返回最终的IP地址
(一直查询到最后一个权威DNS服务器)
62. TCP如何保证可靠传输?
1. 确认应答:当接收端成功收到消息后,回复发送端ACK。
2. 重传机制:发送端如何没有收到ACK,超时后会重传数据包。
3. 流量控制:通过滑动窗口机制:(滑动指的是窗口的大小会根据接收端的反馈而变化)
接收端:通过TCP报文通知发送端当前的接收窗口大小(可以接收多少数据)
发送端:根据接收端的窗口大小控制数据发送速率,防止数据过载。
4. 拥塞控制:(4点)
慢启动:传输开始时,TCP拥塞窗口为1,每接收到一个ACK,拥塞窗口的尺寸
翻倍,这样可以迅速找到网络的可用带宽。
拥塞避免:当拥塞窗口达到一个阈值后,进入拥塞避免状态。此时,拥塞窗口的
尺寸按照线性增长。可以有效控制流量。
快重传:当发送端连续收到三个ACK,将立即重传当前数据包。减少丢包延迟。
快恢复:当快重传后,TCP会进入快恢复状态,而不是回到慢启动状态。此时,
拥塞窗口尺寸设置为阈值大小(拥塞避免阈值),迅速恢复数据传输。
63. C++如何保证线程安全?
1. 互斥锁:使用互斥锁保护共享资源,确保同一时间仅有一个线程可以访问共享资源。
2. 智能指针:减少内存泄漏,提高多线程安全性。
3. 条件变量:可以使 一个线程 等待 另一个线程条件的满足。
4. 原子操作:可以对基本数据类型进行安全的并发操作
5. 读写锁:使用shared_mutex,多个线程可以同时读取数据,但写操作时会阻塞其他线程。
64. 路由选择算法有哪些?
路由:将一个数据包从一个网络发送到另一个网络
路由分为静态路由和动态路由。
静态路由:由管理员手写路由条目
动态路由: 根据实际情况,动态选择路由,常用算法有三种:
| 算法名称 | 解释 |
| RIP 路由信息协议 | 基于距离矢量的 每个结点拥有一个路由表,包含的是达到其他结点的跳数。(直接连接网络为0) 每隔一段时间发给邻接结点的自己的路由表,并更新自己的路由表 (RIP通过路由度量判断路径是否可达,路由度量=15,15为可达,16为不可达 ) |
| BGP 边界网关协议 | 拥有多个自治系统AS,每个AS中的所有结点采用统一的路由策略 AS之间会定期交换路由信息并更新 |
| OSPF 开放式最短路径优先 | 基于路由状态的 通过发送Hello报文建立邻居并更新路由状态 比RIP收敛快,跳数也没有限制,适用于更大型的网络。 |
65. linux服务器如何查看网络连接状态?
netstat查看网络连接、ifconfig查看网络接口、
ping看是否连同某个网络、traceroute查看路由信息
66. TCP的TIME_WAIT
TIME_WAIT是关闭TCP连接时的一方经历的状态(一般是客户端)。
作用:1. TIME_WAIT状态期间,TCP确保所有残余的数据包均可被发送和接收。
2. TIME_WAIT确保一定时间内端口不会被重用,防止重复连接。
3. TIME_WAIT状态下,如果一定时间内没有收到ACK包,则会重传FIN包。
关闭TIME_WAIT:
在一些高并发的场景下,过多的TIME_WAIT会造成高延迟,解决方案如下:
1. linux系统下可以修改/etc/sysctl.conf文件中TIME_WAIT的时间
2. 创建socket时候,可以设置SO_REUSEADDR参数,允许端口快速重用。
3. 采用websocket方式,长连接以减少TIME_WAIT的数量。
67. linux调用fsync
linux中,fsync用于将文件的内存缓冲区强制写入物理磁盘中,确保数据的持久性。
应用场景:数据库、日志文件
#include <unistd.h>
int fsync(int fd);fd是一个已经打开的有效文件描述符。
成功返回0,失败返回-1。
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main() {
int fd = open("example.txt", O_WRONLY | O_CREAT, 0644);
if (fd == -1) {
perror("open");
return 1;
}
const char *text = "Hello, World!";
write(fd, text, strlen(text));
// 调用 fsync 以确保数据写入磁盘
if (fsync(fd) == -1) {
perror("fsync");
close(fd);
return 1;
}
printf("Data synced to disk successfully.\n");
close(fd);
return 0;
}
68. redis持久化一定准确吗?
不一定。
RDB(快照):在两次快照之间,新的写入操作不会被持久化。
AOF(追加):AOF是追加写入,每秒同步,不是真正的实时写入。如果这一秒发生崩溃,
那么最后一段写入命令可能追加失败。
69. C++的枚举默认从几开始?
从0开始
70. 主流开源的用户登录和授权的相关协议?
OAuth2.0协议:允许用户向第三方程序提供访问服务器资源的权限,但不暴露用户凭证(用户
名和密码)。
C++使用cpr库处理HTTP请求,然后再解析json对象。
71. asio底层的io模型和数据处理的调度方案
(asio是一个用于网络编程的C++库)
I/O模型与调度方案(io_service、事件循环):
1. asio提供了一个I/O的异步模型。
2. asio在后端提供了一个事件循环,监听I/O事件的完成。
3. asio后端有一个io_service队列,提交的异步操作都会被放入队列中。
4. 当发起异步操作(async_read和async_write)时,不会阻塞主线程。
72. 智能指针中嵌套引用
当两个shared_ptr相互引用,会造成内存泄漏。
解决办法:将其中一个改为weak_ptr。
73. Redis
redis是独立的数据库,不是mysql的附属,但可以作为mysql的缓存层。
74. Bestfits算法
Bestfits是一种管理内存的策略。它尽可能寻找更小的可用内存块。
作用:减少内存碎片。
75.折半查找平均查找长度
公式 = log2(n) + 1
折半查找:对于有序序列,先查找中间元素,根据和它的比较在从两个子区间中选择一个,
继续根据中间元素查找。
| 名称 | 解释 |
| 平均成功查找长度 | 序列中每个元素查找一遍, 举例:{10, 20, 30, 40, 50} 1/5 * (3 + 2 + 1 + 2 + 3) = 11/5 |
| 平均失败查找长度 | 举不存在元素的例子,以所有元素作为分隔 举例:{10, 20, 30, 40, 50} { X 10, X 20, X 30, X 40, X 50 X } 1/6 * (3 + 3 + 3 + 3 + 3 + 3)= 3 |
76. hdparm -i /dev/hda
hdparm用于对硬盘驱动器进行查询与设置。
hdparm -i:显示硬盘信息
77. swapon -s
swapon命令用于启动交换分区。
交换分区:物理硬盘上的一块区域,用于物理扩展RAM,帮助系统在内存不足时稳定运行。
swapon -s:显示当前系统的全部交换分区的信息
78. linux的dmesg
dmesg用于查看内核信息的环形缓冲区,包括:硬件检测、驱动加载、错误信息等。
(时间久了,新信息可能覆盖旧信息)
常配合grep搜索关键字:
#IDE:集成开发环境
dmesg | grep IDE
79. linux的fdisk
fdisk用于管理磁盘分区。
| 选项 | 解释 |
| -l | 查看当前分区 |
| -p | 打印分区信息 |
| -n | 新建分区 |
| -d | 删除分区 |
| -w | 写入并退出 |
| -q | 不写入退出 |
80. nslookup
nslookup用于查询域名和IP地址的对应。(DNS)
比如:
nslookup www.baidu.com
nslookup 192.168.1.10981. 网络空间测绘平台
网络空间绘测平台:对网络环境进行检测、分析和可视化的工具。
常用的wireshark就是其中一种。
82. 系统进程和非系统进程
| 名称 | 解释 | 常见 |
| 系统进程 | 由操作系统内核或系统服务启动的进程 | init、systemd、sshd、cron、 syslogd、kthreadd、udevd |
| 非系统进程 | 用户或应用程序创建的进程 |
83. RESTful API是什么?
RESTful是一种基于REST框架的网络服务接口。它通过HTTP协议通信,用于不同系统之间交换数据。
RESTful可以利用HTTP的缓存机制,提高性能和响应速度。
84. IP协议的作用
IP协议(Internet Protocol)是互联网通信的基础协议之一,主要用于在网络中进行数据包的寻址和传输。
85. SMTP协议
SMTP(简单邮件传输协议,Simple Mail Transfer Protocol)是一种用于发送电子邮件的协议。它主要用于在电子邮件服务器之间传输邮件,以及从邮件客户端向邮件服务器发送邮件。
特点:
基于TCP,SMTP是应用层协议。
工作流程:
1. 客户端发送HELO请求连接服务器,并接受服务器的身份验证(防止垃圾邮件)
2. 使用命令MAIL FROM指定发件人,
RCPT TO指定收件人,
DATA 指定发送内容。
3. 使用QUIT结束会话。
86. 什么是CDN服务?
CDN(内容分发网络,Content Delivery Network)是一种通过分布在全球的多个服务器节点,来加速和优化网站内容交付的技术架构。
功能:
-
内容缓存:
- CDN会将静态内容(如图片、视频、样式表等)缓存到离用户最近的节点服务器上,从而提高访问速度。
-
负载均衡:
- CDN可以将用户请求分配到不同的服务器,以避免单个服务器的过载,提高整体服务的可用性和响应速度。
-
降低延迟:
- 通过就近访问的方式,CDN可以显著减少数据传输的延迟,让用户更快地获取所需内容。
-
安全性增强:
- CDN通常提供DDoS攻击防护、SSL加密等安全功能,以保护网站免受恶意攻击。
-
高可用性:
- 即使某个节点出现故障,CDN也能自动将流量重定向到其他可用节点,确保服务持续可用
87. 稳定排序
稳定排序指的是如何两个元素A和B相等,排序前后,A与B的相对位置不变。
| 稳定排序 | 冒泡排序 插入排序 归并排序 基数排序 计数排序 桶排序 |
| 不稳定排序 | 快速排序 选择排序 堆排序 |
88. linux的文件同步命令
rsync [- option] {源路径} {目标路径}
| 选项 | 解释 |
| -a | 递归复制 |
| -v | 显示复制的过程信息 |
| -z | 传输中压缩数据,提升速度 |
| -e | 指定远程shell,如SSH 例:rsync -av -e 'ssh -p 8854' ./home/C++ user@remote_host:/home/source/C++ |
| -p | 显示复制的进度,结合--partial选项,可以实现:中断后继续传输 |
89. fopen打开方式
(可以组合使用,比如"rb+")
| 选项 | 必选参数 |
| r | 只读方式,文件必须存在,否则返回nullptr |
| r+ | 读写方式,文件必须存在,否则返回nullptr |
| w | 写方式,如果文件存在则清空,不存在则创建 |
| w+ | 读写方式,如果文件存在则清空,不存在则创建 |
| a | 追加方式,如果文件存在则追加在尾部,不存在则创建 (读取在文件头部) |
| a+ | 读写方式,如果文件存在则写追加到尾部,不存在则创建 (读取在文件头部) |
| 可选参数 | |
| b | 二进制模式 |
| t | 文本模式 |
90. MySQL索引都有哪些?
91. C++异常
92. 操作系统
93.循环冗余码CRC
详述循环冗余校验CRC(C代码)_crc循环冗余校验-CSDN博客
94. IP地址分类
| 类别 | 范围 | 适用 |
| A类地址 |
| 大型网络 |
| B类地址 |
| 中型网络 |
| C类地址 |
| 小型网络 |
| D类地址 (多播地址) |
| 多播组通信 |
| E类地址 (实验性地址) |
| 研究和实验 |
| 特殊地址 | ||
| 私有地址 | 10.0.0.0/8、172.16.0.0/12 和 192.168.0.0/16 | 内部网络,不在公共互联网中路由 |
| 回环地址 | 127.0.0.1 | 用于本机测试 |
95.WinNAT服务
WinNAT(Windows Network Address Translation)是微软在Windows操作系统中提供的一种网络地址转换功能。它主要用于允许多台设备通过一个公共IP地址连接到互联网,常用于家庭或小型办公室网络。
主要特点:
-
地址转换:将私有IP地址转换为公共IP地址,从而实现多台设备共享一个公网IP。
-
支持动态和静态NAT:
- 动态NAT:在动态分配的公网IP中,动态地分配给内部设备。
- 静态NAT:将内部设备的IP地址固定映射到公网IP,适用于需要外部访问的服务。
-
提高安全性:NAT可以隐藏内部网络结构,使外部攻击者更难以识别和访问内部设备。
-
简化网络配置:允许使用私有IP地址,减少对公网IP的需求,简化网络地址管理。
96. iptables
Linux 上用来实现网络地址转换(NAT)功能的工具。允许将内部网络的私有 IP 地址转换为公共 IP 地址,支持多种 NAT 类型,如源 NAT(SNAT)和目的 NAT(DNAT)。


















 696
696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









