







一、PCA概念
主成分分析(Principal Component Analysis,PCA)是一种常用的数据降维和特征提取技术。它通过线性变换将高维数据映射到低维空间,以发现数据中的主要结构和关系。
PCA的目标:是找到能够最大程度保留原始数据方差的新坐标系。它通过计算协方差矩阵或相关矩阵来确定不同维度之间的相关性。然后,通过对协方差矩阵进行特征值分解,得到特征值和特征向量。
值得注意的是:主成分分析假设数据是线性可分的,并且对数据的尺度和分布敏感。在应用主成分分析之前,通常需要进行数据预处理,如去均值、标准化等操作。
二、数据预处理(标准化)
以下所有处理一个名为“Test1.xlsx"文件数据如下,且均采用相对路径。
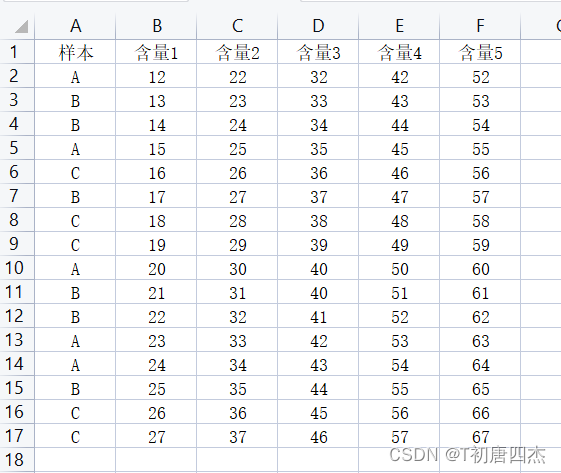
1、max-min标准化
将数据线性地转换到指定的最小值和最大值之间的范围。
公式:
案例:将名为”Test1.xlsx”的文件数据max-min标准化,创建并保存到名为”Tan1.xlsx”的文件中。
以下是Python代码执行上述操作:
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import pandas as pd
# 创建MinMaxScaler对象
scaler = MinMaxScaler()
#读取文件数据(相对路径)
data=pd.DataFrame(pd.read_excel("Test1.xlsx"))
data1=data.values
#删除非数据内容,axis=0按行,axis=1按列
data1= np.delete(data1,0,axis=1)
# 对特征矩阵进行最小-最大缩放,即max-min标准化
data2=scaler.fit_transform(data1)
#DataFrame是一个二维标签化数据结构与二维数组有所不同。
#二维数组转成DataFrame
print("max-min标准化后的数据:\n",data2)
data3=pd.DataFrame(data2)
#创建名字为'Tan1.xlsx'的文件并把数据导入文件中
data3.to_excel("Tan1.xlsx")2、Z-score标准化
Z-score标准化是一种常用的数据标准化方法,用于将数据转换为均值为0,标准差为1的标准正态分布。
公式:
其中,Mean是原始样本值得平均值,Std是原始样本值得标准差。
案例1:把上面名为”Test1”的文件数据Z-score标准化,创建并保存到名为”Tan1.xlsx”的文件中。
from sklearn.preprocessing import StandardScaler
import numpy as np
import pandas as pd
scaler= StandardScaler()
data=pd.DataFrame(pd.read_excel("Test1.xlsx"))
data1=data.values
data1= np.delete(data1,0,axis=1)#一定要删除非数据内容,比如表中有带中文的内容
data2=scaler.fit_transform(data1)
print("Z-score标准化后的数据:\n",data2)
data3=pd.DataFrame(data2)
data3.to_excel("Tan1.xlsx")案例2:有一个二维数组data,可以使用以下步骤对其进行Z-score标准化:
(1)计算数组的均值(mean)和标准差(standard deviation)。
(2)对数组中的每个元素,减去均值,并除以标准差。
import numpy as np
# 二维数组
data = np.array([[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]])
# 计算均值和标准差
Mean = np.mean(data)
Std = np.std(data)
# Z-score标准化
Z_score_data = (data - Mean) / Std
print(Z_score_data)3、中心化
让数据变成平均值为0的一组数据
公式:X=X-Mean
案例:把上面名为”Test1”的文件数据中心化(也是标准化的一种),创建并保存到名为”Tan1.xlsx”的文件中。
import numpy as np
import pandas as pd
data=pd.DataFrame(pd.read_excel("Test1.xlsx"))
data1=data.values
data1=np.delete(data1,0,axis=1)
# 计算中心化后的数据的平均值
data2=data1
for i in range(0,5):
mean = data1[:,i].mean()
#数据中心化
data2[:,i] = data1[:,i]-mean
print("原始数据:\n", data1)
print("中心化后的数据:\n", data2)
data3=pd.DataFrame(data2)
data3.to_excel("Tan1.xlsx")4、归一化
公式为:X= X /(x1+x2+...Xn)
作用:对正数进行变换,使结果落到[0,1]区间,其将数值的绝对值变成相对值关系。
import numpy as np
import pandas as pd
data=pd.DataFrame(pd.read_excel("Test1.xlsx"))
data1=data.values
data1=np.delete(data1,0,axis=1)
print(data1)
data2=data1
for i in range(0,5):
sum1=np.sum(data1[:,i])
data2[:,i]=data1[:,i]/sum1
print("归一化后数据:\n",data2)
data3=pd.DataFrame(data2)
data3.to_excel("Tan1.xlsx")注意:以上标准化处理说法不一,但公式唯一,一公式为准。

















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









