






该方法只能爬取30条/page的内容,同时使用pyecharts作简单的可视化处理
后期会持续更新突破访问量限制、反爬等的方法
pyecharts官方文档https://gallery.pyecharts.org/#/README
- 首先进行网站设置,把地址改成浏览器的exe文件(非桌面快捷方式),执行代码,temp.py
from DrissionPage import ChromiumOptions
path = r'D:\Chrome\Application\chrome.exe'
ChromiumOptions().set_browser_path(path).save()
- 开始爬取信息 boss.py
# 导入自动化模板
from DrissionPage import ChromiumPage
import csv
f = open('data.csv',mode = 'w',encoding = 'utf-8',newline = '')
# 字典写入的方法,传入文件对象和字段名,字段名就是字典里的键
csv_writer = csv.DictWriter(f, fieldnames=['职位','公司','薪资','城市','区域','基本要求'])
# 写入表头
csv_writer.writeheader()
# 导入格式化输出模块
from pprint import pprint
# 实例化浏览器对象
dp = ChromiumPage()
#监听数据包
dp.listen.start('wapi/zpgeek/search/joblist.json')
#访问网站
dp.get('https://www.zhipin.com/web/geek/job?query=%E5%89%8D%E7%AB%AF&city=101090200')
# 循环翻页1-10
for page in range(1,2):
# 下滑网页页面到底部
dp.scroll.to_bottom()
print(f'正在采集第{page}页的数据内容')
#等待数据包加载
res = dp.listen.wait()
#获取响应体
json_data = res.response.body
# print(json_data)
jobList = json_data['zpData']['jobList']
for index in jobList:
# 提起职位信息数据,保存字典
jobDesc = {
'职位':index['jobName'],
'公司':index['brandName'],
'薪资':index['salaryDesc'],
'城市':index['cityName'],
'区域':index['areaDistrict'],
'基本要求':','.join(index['skills'])
}
# 写入数据
csv_writer.writerow(jobDesc)
# 批量操作
# 点击下一页(元素定位)
# dp.ele()通过元素定位
# css通过CSS语法
# .类名
# dp.ele('css:.options-pages a:last-of-type').click()
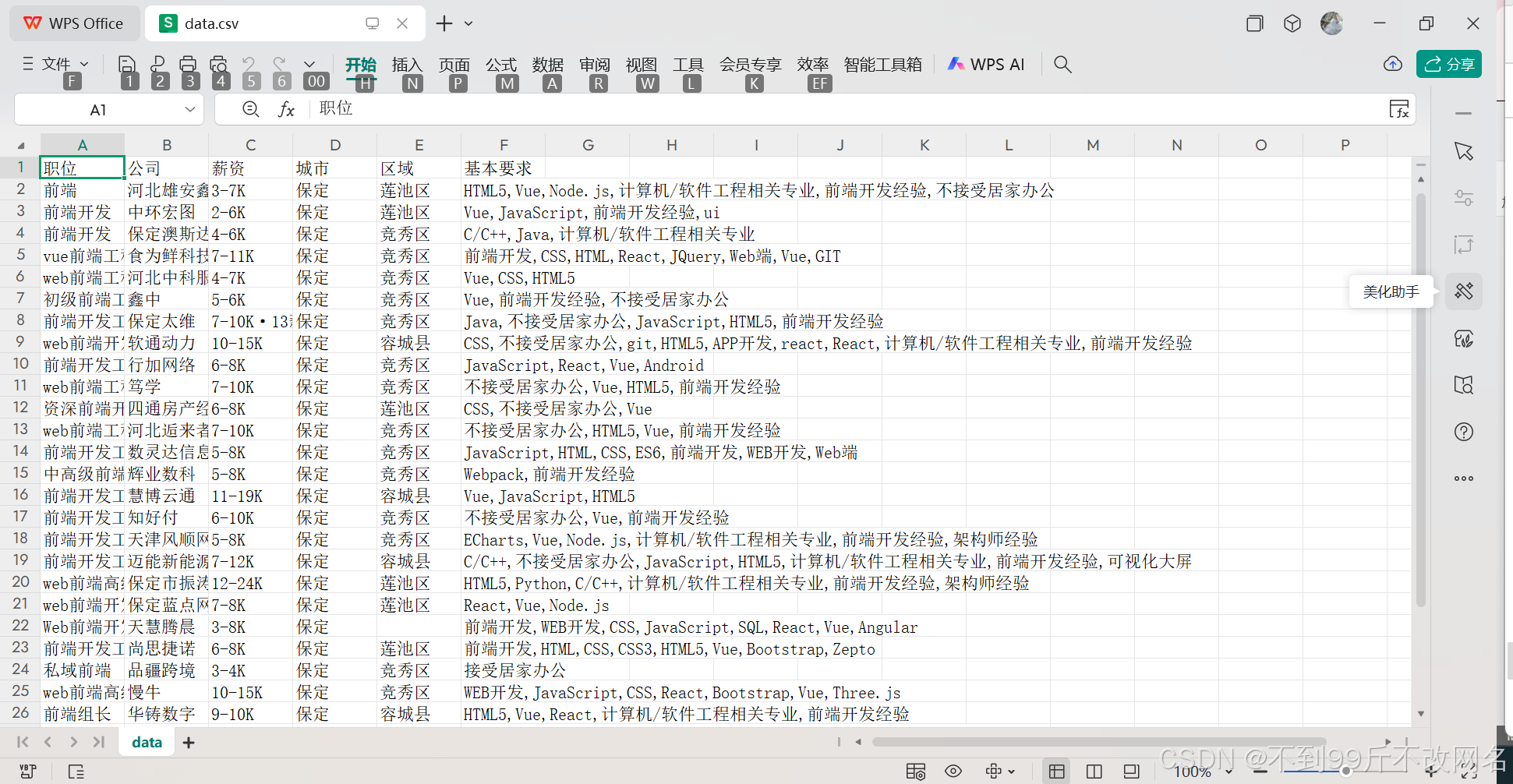
读取到的data.csv文件效果如下:
- 数据可视化操作 read.py
#导入数据处理模块
import pandas as pd
# 导入配置项、图形样式等
from pyecharts import options as opts
# 导入饼图
from pyecharts.charts import Pie
# 导入数据(随机生成数据)
from pyecharts.faker import Faker
# 读取csv文件
df = pd.read_csv('data.csv')
# print(df.head())
# 获取x轴的数据
x_district = df['区域'].value_counts().index.to_list()
y_district = df['区域'].value_counts().to_list()
print(x_district)
print(y_district)
c = (
Pie()
.add("",
[
list(z)
for z in zip(
x_district,
y_district
)
]
)
.set_global_opts(
title_opts=opts.TitleOpts(title="区域分布情况"),
legend_opts=opts.LegendOpts(type_="scroll",pos_left="80%",orient="vertical")
)
.set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
.set_global_opts(title_opts=opts.TitleOpts(title="Pie-设置颜色"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# 导出可视化html文件
.render("pie_set_color.html")
)
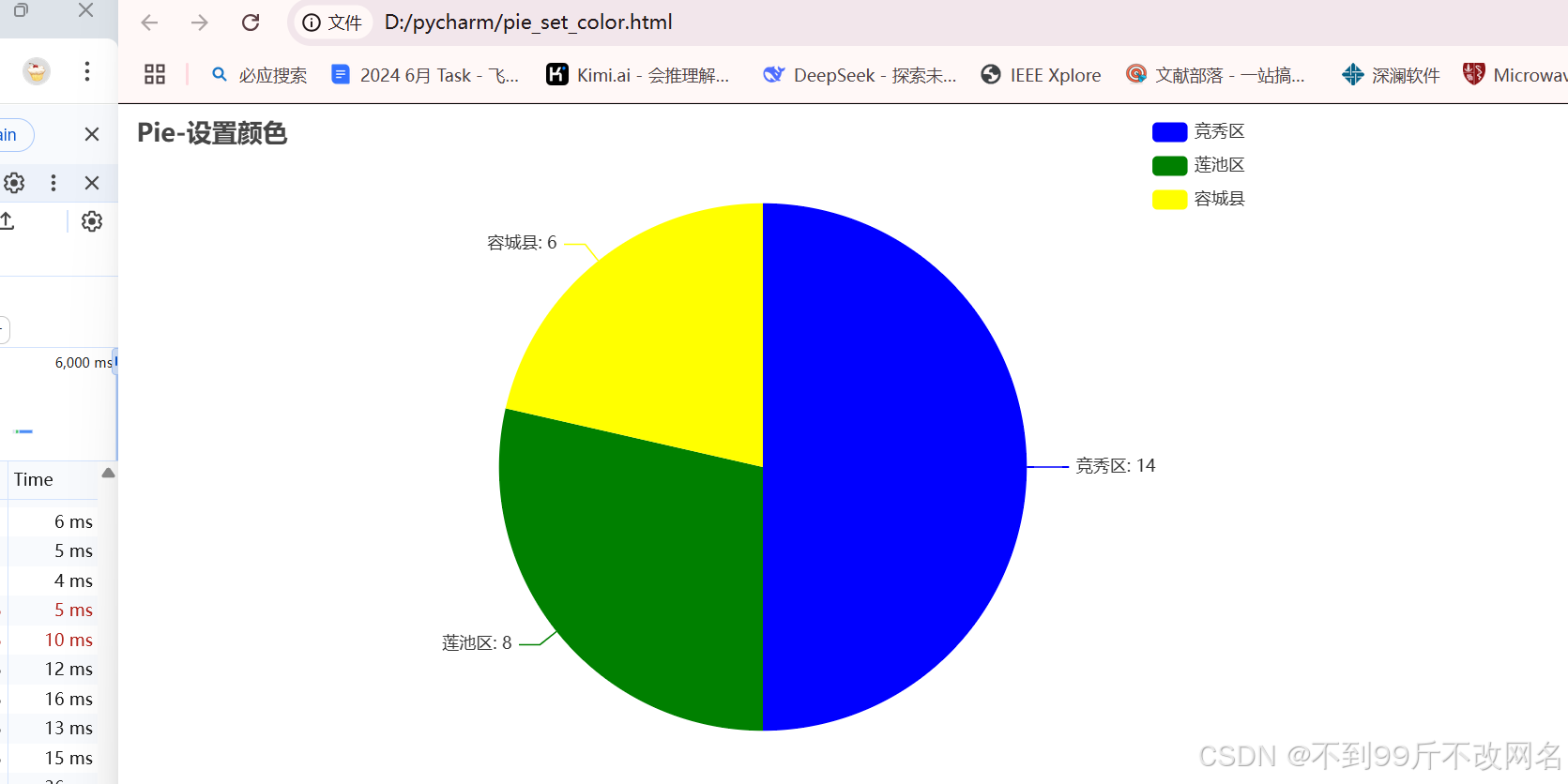
可视化操作效果如下:

















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









