







引言:
大家都知道公有云好,连ai都夸赞:
-
成本效益:公有云的按需付费模式让你只为使用的资源付费,无需大规模前期投资。特别适合初创企业和小规模K8s集群,省去了购置硬件和维护的成本。
-
弹性扩展:公有云提供强大的弹性扩展能力,能够根据需求快速增加或减少资源,灵活应对业务波动。你不需要担心硬件资源不够用的问题,随时可以扩展。
-
管理便捷:云服务商通常提供一站式管理平台和丰富的工具,简化了集群的管理和维护工作。你不需要深挖硬件细节,只需专注于应用开发和部署。
-
高可用性和灾备:大多数公有云服务商提供多区域、多可用区的部署选项,可以轻松实现高可用性和灾备,确保业务的连续性。
-
安全性和合规性:顶级公有云服务商通常具备先进的安全措施和合规认证,帮助你轻松应对各种安全威胁和法规要求。
但ai也说,也有点小缺点,ai说了5条,但我认为只有两条是重要的。
-
成本波动:虽然公有云按需付费看似经济,但随着业务增长,费用可能迅速增加。特别是如果没有做好成本管理,可能会面临不可预见的高额账单。
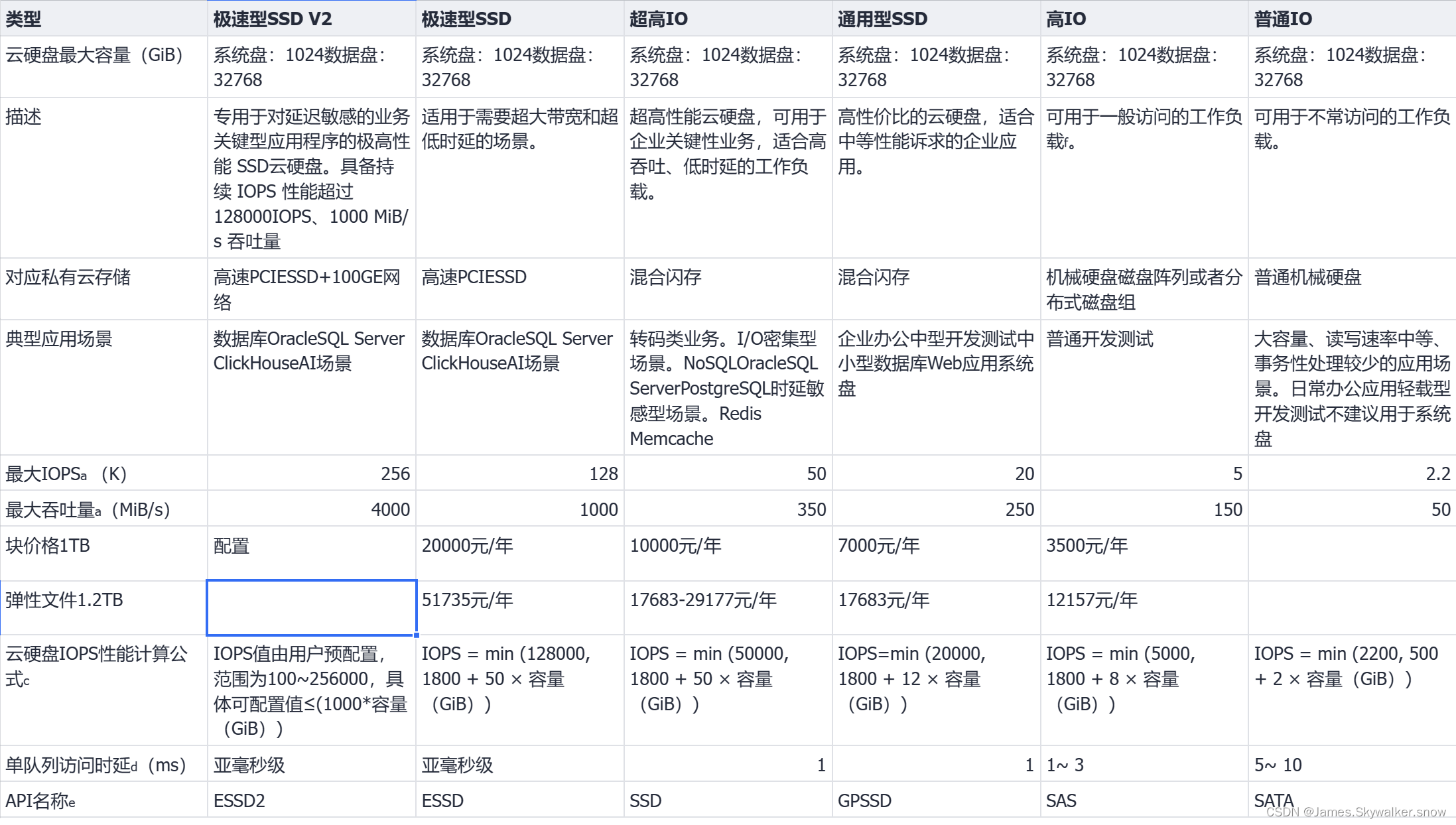
人补充:公有云的计算资源并不昂贵,昂贵的是存储成本,尤其是高性能的存储。以价格中等的爱国云为例,极速SDD也就是大家买到的ssd,块存储要2万/年 TB,文件存储要5万/年 TB,要是能接受这个价格,感觉点击右上角的小x,免得浪费时间。
2.性能限制:公有云的共享资源环境有时会导致性能不稳定,特别是在高峰期或资源争夺激烈的情况下。你无法完全控制底层硬件的性能。
补充:如果不提供计算密集型服务,那么该条不受影响,如果提供,那么公有云提供的弹性云性能无法满足要求,裸金属云可以。
那么回到本次文章的标题,如果想搭建小规模的k8s的集群,想省钱,应该如何做。
一、单节点
先说k8s无法部署在单个机器上(注:在不使用虚拟机的情况下),但是Minikube可以。
Minikube 是一个工具,可以在本地快速运行单节点的 Kubernetes 集群。它主要用于开发、测试和学习 Kubernetes,而不是用于生产环境。Minikube 支持多种操作系统,包括 Linux、macOS 和 Windows。Minikube更容易安装,而且提供了全面的 Kubernetes 功能,minikube 支持大部分 Kubernetes 功能和组件,适合学习和实验不同的 Kubernetes 特性和配置。
如果使用单节点部署生产生产环境也不是不可以,但是单节点不建议使用实体机部署,可以部署在公有云,公有云底层提供了稳定性、扩展性,提供了备份、镜像等服务,保证了单节点硬件运行的稳定以及系统层面宕机后的恢复,
二、1+2节点
采用1管理节点(k8s称control-plane,一般称为master node)+2工作节点。
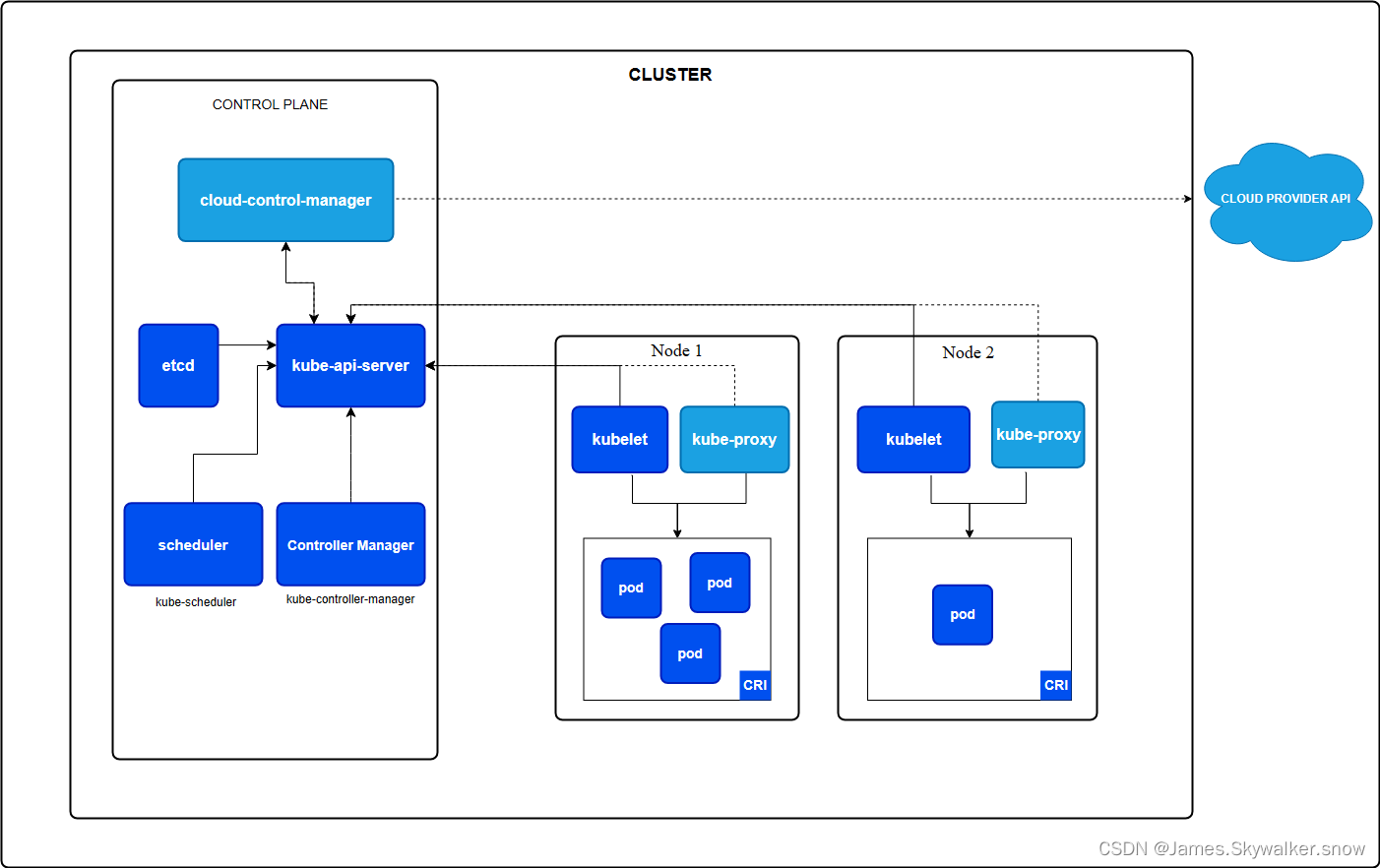
管理节点
k8s的管理节点只负责调度运行,挂掉了,工作节点已经运行pod不受运行,但会丧失自愈、扩展等高级功能。
在k8s的说明上并没有给出其硬件需求的具体指标,包括cpu和磁盘性能。k8s的在不使用外部etcd的情况下,管理节点还需要运行etcd服务。因此我们参考etcd的性能指标。
redhat推荐的 etcd 做法
因为 etcd 将数据写入磁盘并将提案保存在磁盘上,所以它的性能取决于磁盘性能。 虽然 etcd 不是特别密集的 I/O,但它需要一个低延迟的块设备来获得最佳性能和稳定性。因为 etcd 的共识协议依赖于将元数据持续存储到日志 (WAL) 中,所以 etcd 对磁盘写入延迟很敏感。磁盘速度慢和来自其他进程的磁盘活动可能会导致长时间的 fsync 延迟。
这些延迟可能会导致 etcd 错过检测信号,无法按时将新提案提交到磁盘,并最终遇到请求超时和临时 leader 丢失。高写入延迟还会导致 OpenShift API 速度变慢,从而影响集群性能。由于这些原因,请避免将其他工作负载托管在对 I/O 敏感或密集型的控制平面节点上,并共享相同的底层 I/O 基础结构。
在延迟方面,在块设备上运行 etcd,该块设备可以按顺序写入至少 50 IOPS 的 8000 字节长。也就是说,延迟为 10 毫秒,请记住使用 fdatasync 同步 WAL 中的每个写入。对于负载较重的集群,建议连续使用 500 IOPS 的 8000 字节 (2 ms)。要衡量这些数字,您可以使用基准测试工具,例如 fio。
要实现这样的性能,请在由低延迟和高吞吐量的 SSD 或 NVMe 磁盘支持的机器上运行 etcd。考虑单层单元 (SLC) 固态硬盘 (SSD),它为每个存储单元提供 1 位,耐用且可靠,是写入密集型工作负载的理想选择。
|
etcd 上的负载来自静态因素(例如节点和 Pod 的数量)和动态因素(包括 Pod 自动扩展、Pod 重启、作业执行和其他与工作负载相关的事件导致的端点更改)。要准确调整 etcd 设置的大小,必须分析工作负载的特定要求。考虑节点、Pod 的数量以及影响 etcd 负载的其他相关因素。 |
以下硬盘驱动器实践提供最佳的 etcd 性能:
-
使用专用的 etcd 驱动器。避免使用通过网络通信的驱动器,例如 iSCSI。不要将日志文件或其他繁重的工作负载放在 etcd 驱动器上。
-
首选具有低延迟的驱动器,以支持快速读取和写入操作。
-
首选高带宽写入,以加快压缩和碎片整理速度。
-
首选高带宽读取,以便更快地从故障中恢复。
-
使用固态硬盘作为最小选择。首选适用于生产环境的 NVMe 驱动器。
-
使用服务器级硬件提高可靠性。
|
避免 NAS 或 SAN 设置和旋转驱动器。Ceph Rados 块设备 (RBD) 和其他类型的网络连接存储可能会导致不可预测的网络延迟。要大规模向 etcd 节点提供快速存储,请使用 PCI 直通将 NVM 设备直接传递到节点。 |
始终使用 fio 等实用程序进行基准测试。您可以使用此类实用程序在集群性能增加时持续监控集群性能。
|
避免使用网络文件系统 (NFS) 协议或其他基于网络的文件系统。 |
在已部署的 OpenShift Container Platform 集群上要监控的一些关键指标是 etcd 磁盘的 p99、提前写入日志持续时间和 etcd leader 更改的数量。使用 Prometheus 跟踪这些指标。
|
在正常操作期间,集群中的 etcd 成员数据库大小可能会有所不同。此差异不会影响群集升级,即使 leader 大小与其他成员不同也是如此。 |
来源:推荐的 etcd 实践 - 推荐的性能和可伸缩性实践 |可扩展性和性能 |OpenShift 容器平台 4.13
etcd官方说明
Etcd 通常在有限的资源下运行良好,用于开发或测试目的;在笔记本电脑或廉价的云机器上使用 etcd 进行开发是很常见的。但是,在生产环境中运行 etcd 集群时,一些硬件准则对于正确管理很有用。这些建议不是硬性规定;它们是稳健生产部署的良好起点。与往常一样,在生产环境中运行之前,应使用模拟工作负载测试部署。
中央处理器CPU
很少有 etcd 部署需要大量的 CPU 容量。典型的集群需要两到四个内核才能平稳运行。 重负载的 etcd 部署,每秒服务数千个客户端或数万个请求,往往会受到 CPU 的限制,因为 etcd 可以处理来自内存的请求。这种繁重的部署通常需要 8 到 16 个专用内核。
内存
etcd 的内存占用相对较小,但其性能仍然取决于是否有足够的内存。etcd 服务器将积极地缓存键值数据,并花费其其余大部分内存跟踪观察者。通常 8GB 就足够了。对于具有数千个观察程序和数百万个密钥的繁重部署,请相应地分配 16GB 到 64GB 内存。
磁盘
快速磁盘是 etcd 部署性能和稳定性的最关键因素。
磁盘速度较慢会增加 etcd 请求延迟,并可能损害集群稳定性。由于 etcd 的共识协议依赖于将元数据持久地存储到日志中,因此大多数 etcd 集群成员必须将每个请求都写入磁盘。此外,etcd 还会以增量方式将其状态检查点到磁盘,以便它可以截断此日志。如果这些写入时间过长,检测信号可能会超时并触发选举,从而破坏集群的稳定性。
etcd 对磁盘写入延迟非常敏感。通常需要 50 个顺序 IOPS(例如,7200 RPM 磁盘)。对于负载较重的集群,建议使用 500 顺序 IOPS(例如,典型的本地 SSD 或高性能虚拟化块设备)。请注意,大多数云提供商发布并发 IOPS,而不是顺序 IOPS;发布的并发 IOPS 可能比顺序 IOPS 高 10 倍。要测量实际的顺序 IOPS,我们建议使用 diskbench 或 fio 等磁盘基准测试工具。
etcd 只需要适度的磁盘带宽,但当发生故障的成员必须赶上集群时,更多的磁盘带宽可以更快地恢复。通常,10MB/s 将在 15 秒内恢复 100MB 数据。对于大型集群,建议使用 100MB/s 或更高,以便在 15 秒内恢复 1GB 数据。
如果可能,请使用 SSD 返回 etcd 的存储。与旋转磁盘相比,SSD 通常提供更低的写入延迟和更小的差异,从而提高了 etcd 的稳定性和可靠性。如果使用旋转磁盘,请尽可能获得最快的磁盘 (15,000 RPM)。使用 RAID 0 也是提高磁盘速度的有效方法,适用于旋转磁盘和 SSD。对于至少三个集群成员,不需要 RAID 的镜像和/或奇偶校验变体;etcd 的一致复制已经获得了高可用性。
旋转磁盘(spinning disks ):就是我们说的机械硬盘。
网络
多成员 etcd 部署受益于快速可靠的网络。为了使 etcd 既一致又容错分区,分区中断的不可靠网络将导致可用性差。低延迟确保 etcd 成员可以快速通信。高带宽可以减少恢复故障 etcd 成员的时间。1GbE 对于常见的 etcd 部署来说已经足够了。对于大型 etcd 集群,10GbE 网络将缩短平均恢复时间。
尽可能在单个数据中心内部署 etcd 成员,以避免延迟开销并减少对事件进行分区的可能性。如果需要另一个数据中心的故障域,请选择离现有数据中心更近的数据中心。另请阅读调优文档,了解有关跨数据中心部署的更多信息。
硬件配置示例
以下是 AWS 和 GCE 环境中的一些硬件设置示例。如前所述,但无论如何都必须强调,管理员应该在将 etcd 部署投入生产之前使用模拟工作负载对其进行测试。
请注意,这些配置假定这些机器完全专用于 etcd。在这些机器上运行其他应用程序和 etcd 可能会导致资源争用并导致集群不稳定。
小型集群
小型集群服务于少于 100 个客户端,每秒少于 200 个请求,存储的数据不超过 100MB。
示例应用程序工作负载:50 节点 Kubernetes 集群
| 供应商 | 类型 | vCPU | 内存 (GB) | 最大并发 IOPS | 磁盘带宽 (MB/s) |
|---|---|---|---|---|---|
| AWS | m4.large | 2 | 8 | 3600 | 56.25 |
| GCE | n1-standard-2 + 50GB PD SSD | 2 | 7.5 | 1500 | 25 |
中型集群
中型集群服务客户端数少于 500 个,每秒请求数少于 1000 个,存储的数据不超过 500MB。
示例应用程序工作负载:250 节点的 Kubernetes 集群
| 供应商 | 类型 | vCPU | 内存 (GB) | 最大并发 IOPS | 磁盘带宽 (MB/s) |
|---|---|---|---|---|---|
| AWS | m4.xlarge | 4 | 16 | 6000 | 93.75 |
| GCE | n1-standard-4 + 150GB PD SSD | 4 | 15 | 4500 | 75 |
大型集群
大型集群服务的客户端数少于 1,500 个,每秒请求数少于 10,000 个,存储的数据不超过 1GB。
示例应用程序工作负载:1,000 节点的 Kubernetes 集群
| 供应商 | 类型 | vCPU | 内存 (GB) | 最大并发 IOPS | 磁盘带宽 (MB/s) |
|---|---|---|---|---|---|
| AWS | m4.2xlarge | 8 | 32 | 8000 | 125 |
| GCE | n1-standard-8 + 250GB PD SSD | 8 | 30 | 7500 | 125 |
xLarge 集群
一个xLarge集群服务1500多个客户端,每秒超过10000个请求,存储超过1GB的数据。
示例应用程序工作负载:3,000 节点的 Kubernetes 集群
| 供应商 | 类型 | vCPU | 内存 (GB) | 最大并发 IOPS | 磁盘带宽 (MB/s) |
|---|---|---|---|---|---|
| AWS | m4.4xlarge | 16 | 64 | 16,000 | 250 |
| GCE | n1-standard-16 + 500GB PD SSD | 16 | 60 | 15,000 | 250 |
来源:硬件建议 |etcd的
总结:
这么我们知道对于管理节点而言,小型集群我们需要:
- CPU:要求不高,4核心即可。
- 内存:DDR ECC 16GB。长时间开机ECC好一丢丢(实测普通内存也可实现长时间开机,就是5年不关机)。
- 磁盘:任何的企业级SSD 960GB,SAS或者NVME均可。为了单节点的稳定性,我们可将etcd数据、k8s数据和系统放置于一块磁盘的,但是做raid1,现在很多服务器、准系统、服务器主板都支持nvme硬盘做raid1,毕竟硬盘最重要,相对来说损坏是灾难性的。多一块做冗余很有必要。
- 电源:使用冗余电源。电源是整个机器的基础,其稳定性影响整个所有硬件,而且电源插头接头容易松动,电缆容易坏掉,电容容易爆降,是整个硬件表现最差的那个,使用冗余电源是必需的。
关于机械硬盘:对于具有冗余设计的系统而言,机械硬盘除了价格低之外,相比SSD没有任何优点,其稳定性不如企业级SSD(垃圾QLC除外)。
工作节点
既然自己搭建k8s集群,那么必然对性能有所要求,工作节点建议配置拉满。2个节点避免了单节点宕机带来的灾难。
CPU:推荐EPYC7003、EPYC9004 还有intel还没有正式推出的新一代XEON,单路or 双路。
内存:满通道配置的DDR ECC(EPYC7003是8通道,9004是12个通道)
电源:冗余电源,根据cpu性能
系统盘:Raid1-SSD
数据盘:等到ceph细说
三、3+2节点
在1+2节点的基础,扩展管理节点,为管理节点提供冗余,使用3个管理节点,etcd部署在管理节点中。管理节点虽然采用主从架构,同时只有1个节点在工作,但建议采用一模一样的配置。
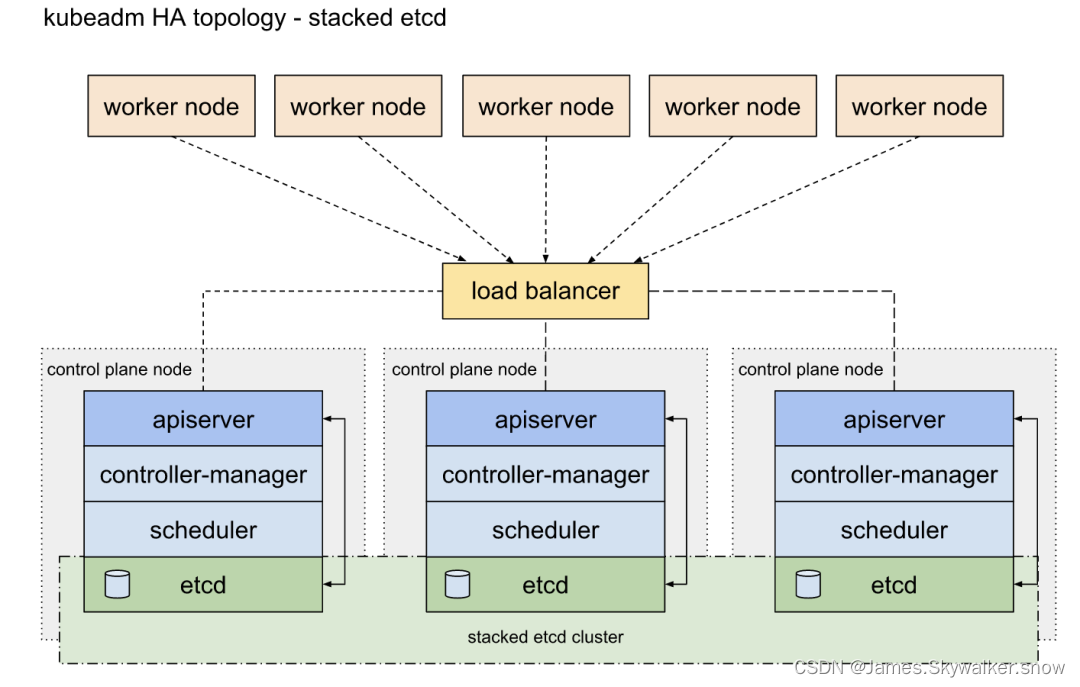
部署高可用,参考详解 K8S 高可用部署_kubernetes sandbox-CSDN博客
四、3+3+2节点
将etcd节点与管理节点分离,采用3+3+2架构。这样即时管理节点全部关掉,只要etcd节点还健在,就很容易恢复集群状态。
Etcd 是一个分布式键值存储系统,主要用于存储和管理分布式系统中的配置信息。它由 CoreOS 开发,具有高可用性、强一致性和简洁的 API,因此在分布式系统中得到了广泛应用。在 Kubernetes 中,Etcd 被用来存储所有集群的配置数据和状态信息,是 Kubernetes 集群的关键组件之一。
Etcd 节点的作用
集群状态存储:Etcd 存储 Kubernetes 集群的所有数据,包括节点信息、Pod 信息、ConfigMap、Secret 等。每当集群中的状态发生变化(如 Pod 创建或删除),这些变化都会被记录在 Etcd 中。
一致性和高可用性:Etcd 通过 Raft 共识算法来保证数据的强一致性和高可用性。即使在部分节点故障的情况下,Etcd 依然能够保持数据的一致性和可用性。
配置管理:Kubernetes 的所有配置数据都存储在 Etcd 中。当管理员或控制器更改配置时,这些更改会立即反映在 Etcd 中,并且会自动同步到集群中的所有节点。
服务发现:Kubernetes 通过 Etcd 实现服务发现机制。当新的服务注册到 Kubernetes 集群时,服务信息会存储在 Etcd 中,其他组件可以通过查询 Etcd 获取最新的服务信息。
Etcd 重要性的原因
数据一致性:Etcd 保证了 Kubernetes 集群数据的一致性和可靠性。无论在哪个节点进行数据读写操作,最终都能确保数据的一致性,这是 Kubernetes 正常运行的基础。
高可用性:为了确保 Kubernetes 集群在节点故障时仍然能够正常运行,Etcd 通常以集群方式部署(通常是 3 个或更多节点),以提供高可用性和容错能力。即使某个 Etcd 节点故障,其他节点仍能继续提供服务。
性能和效率:Etcd 的高效存储和快速响应能力确保了 Kubernetes 的控制平面能够快速响应配置更改和状态更新,提高了集群的性能和效率。
故障恢复:Etcd 通过快照和日志机制,可以在系统故障后快速恢复数据,确保 Kubernetes 集群的持续可用性。
部署 Etcd 节点的最佳实践
奇数个节点:为了确保高可用性和一致性,Etcd 集群通常部署奇数个节点(如 3、5、7 个节点)。这样在发生网络分区或节点故障时,仍然能够保证数据一致性。
独立部署:虽然 Etcd 可以与 Kubernetes 控制平面节点部署在一起,但为了提高安全性和性能,建议将 Etcd 节点独立部署,以减少干扰。
备份和恢复:定期备份 Etcd 数据,并制定详细的恢复计划。在发生故障时,能够快速恢复 Etcd 数据,确保集群的正常运行。
监控和报警:对 Etcd 集群进行实时监控,设置合理的报警机制,及时发现和处理潜在问题,确保 Etcd 集群的稳定性和高可用性。
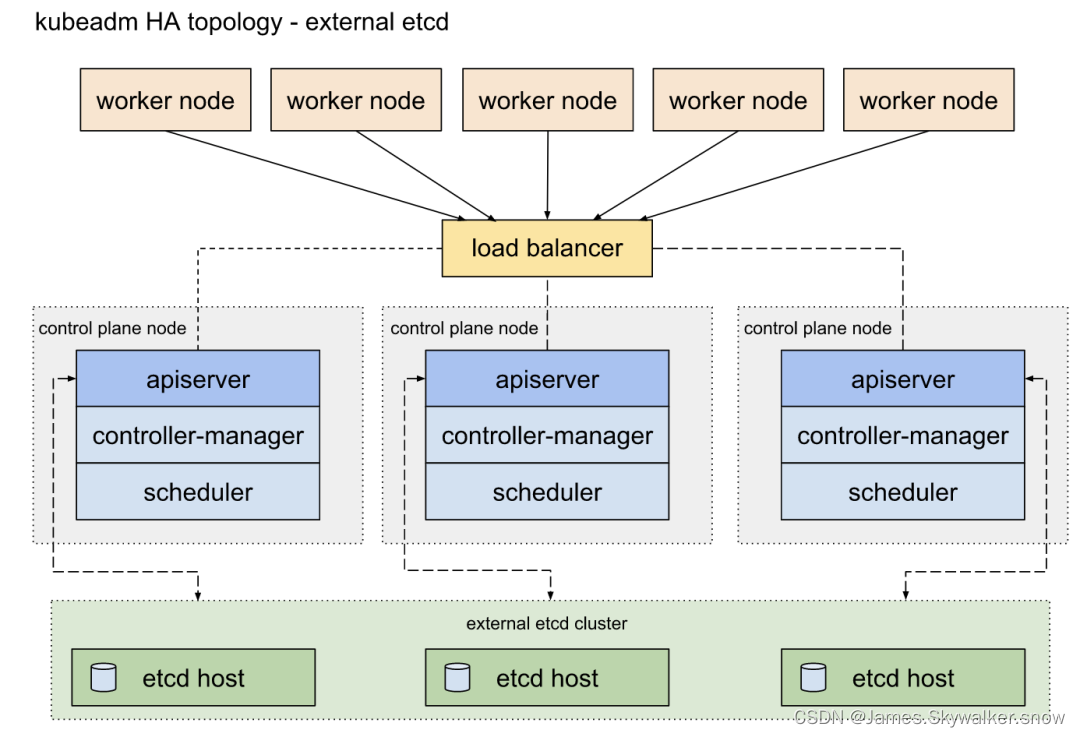
部署高可用,参考详解 K8S 高可用部署_kubernetes sandbox-CSDN博客
五、3+3+n节点
在3etcd+3control的基础上,可以无限扩展工作节点。
六、网络需求
交换机
在分布式系统,系统瓶颈一般不在于服务器,而在于网络,服务器之间要进行通讯,分布式存储需要提供数据,都要通过网络进行。
因此建立至少采用10Gb网络,采用光模块。
如果部署分布式存储如ceph,则采用100Gb网络。
路由器
具有防火墙的,并具有包高转发率的企业级路由是最好的选择。















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









