






今天在爬一个网页的时候,爬完打开txt文件看到内容是一片乱码:

上网查了之后发现是中文编码格式的问题。
首先查看网页编码:
res = requests.get(url,timeout=30)
print(res.encoding)
输出是ISO-8859-1。
参考python中把ISO-8859-1编码转化为UTF-8修改代码,最初因为格式问题总是报错。
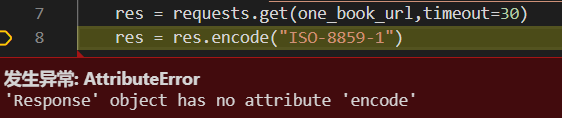
这时候的res返回的是一个包含服务器资源的Response对象,包含从服务器返回的所有的相关资源,而encode是针对字符串使用的。
上面链接中也是以字符串为实例,所以不能直接加在res后面。
res = requests.get(one_book_url,timeout=30)
res = res.text.encode("ISO-8859-1")
res = res.decode("utf-8")
这时候的res是字符串,所以在BeautifulSoup中应该是:
soup = BeautifulSoup(res,"html.parser")
对比一下修改前后的代码。
修改前:
res = requests.get(one_book_url,timeout=30)
soup = BeautifulSoup(res.text,"html.parser")
修改后:
res = requests.get(one_book_url,timeout=30)
res = res.text.encode("ISO-8859-1")
res = res.decode("utf-8")
soup = BeautifulSoup(res,"html.parser")
在想通老是报错的原因之前感觉自己一直像个傻子一样乱转,根本原因是自己对这些方法都不熟悉,其实这些都是很基础的知识,想通了之后突然就觉得真的挺简单的…















 636
636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









