







大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在阅读过程中有些知识点存在盲区,可以回到如何优雅的谈论大模型重新阅读。另外斯坦福2024人工智能报告解读为通识性读物。若对于如果构建生成级别的AI架构则可以关注AI架构设计。技术宅麻烦死磕LLM背后的基础模型。当然最重要的是订阅跟随“鲁班模锤”。
在将大模型部署到生产线的时候,针对大型语言模型 (LLM) 的部署优化成本高昂。并行策略,批处理技术和调度策略等多维度的因子组成了大模型部署的配置。要摸索出不同维度的最优的组合策略,需要多次的进行实验以便确认LLM应用程序工作负载。这个过程其实耗时耗力,在微软的推动下,诞生了一种大规模、高保真、易于扩展的,专门针对LLM推理性能模拟的框架-Vidur。

背景
Vidur使用实验分析和预测建模相结合,对LLM的性能进行建模,并通过估计延迟和吞吐量等多个感兴趣的指标来评估不同工作负载的端到端推理性能。Vidur在多个LLM上验证了保真度,由它所估计的推理延迟在整个范围内的误差小于9%。
这个项目还推出了Vidur-Search,用于辅助优化LLM部署的配置搜索工具。Vidur-Search使用Vidur自动识别满足应用程序性能限制的最具成本效益的部署配置。是不是不可思议,Vidur-Search在普通计算机上可以在一小时之内找到LLaMA2-70B的最佳部署配置,而基于实际环境的探索则需要42,000的GPU小时(价值218,000的美元)

LLM推理结构
LLM 推理请求处理一般由两个不同的阶段组成:预填充和解码。预填充阶段用于处理用户输入并生成第一个输出令牌。在解码阶段,上一步生成的令牌将通过模型传递继续用于下一个令牌的生成直到结束。
解码过程的注意力操作需要访问先前处理过令牌的KV值,以避免重复计算,现在一般LLM推理系统都会缓存这些数值,一般放在KV-Cache。
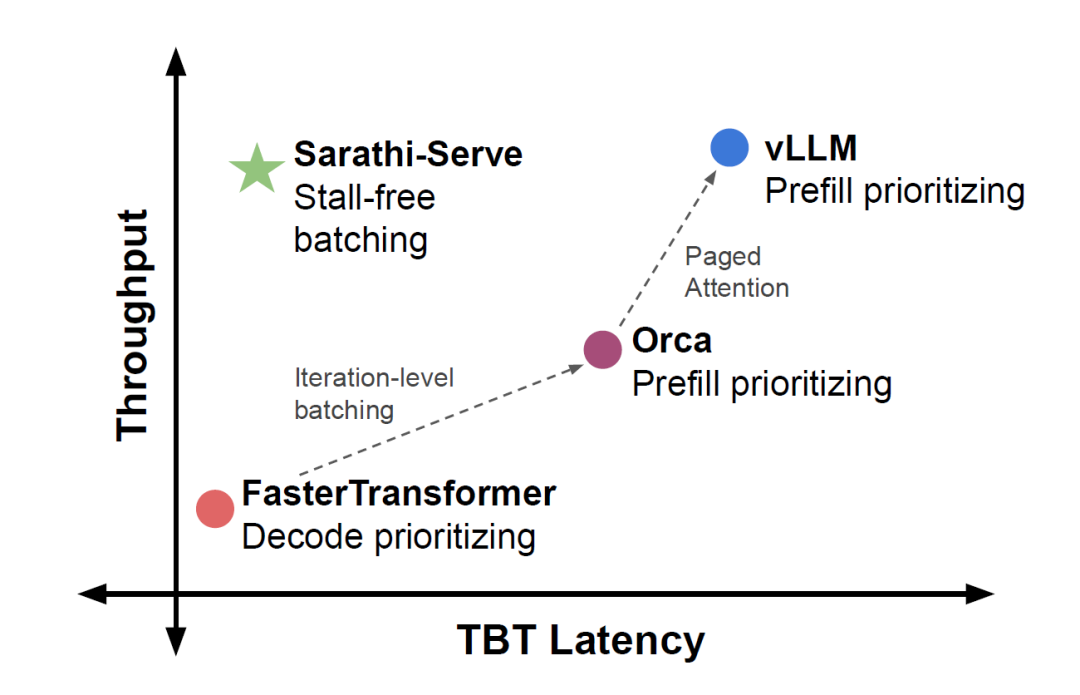
Vidur借鉴了《Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve》这篇论文,按照LLM推理调度器设计中吞吐和延时的权衡,将现有LLM推理调度器分为两类:预填充优先级和解码优先级。前者实现了高吞吐量,高延时,而后者遭受低延时,然而承受着低吞吐量。其实任何的系统优化都是成本和延时之间的博弈,如何使用正确的技术取决于应用程序要求和硬件可用性。
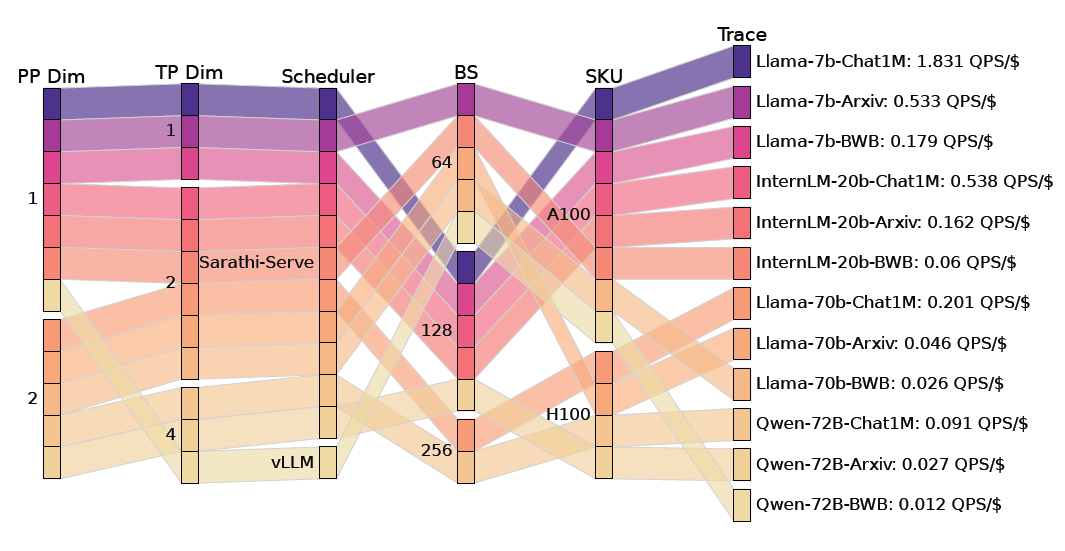
并行策略、调度程序选择、块大小、批量大小、SKU等系统级别的配置策略为LLM部署带来了很大配置组合空间。下图所示为12个模型(12个色块)中每一个的最佳配置(当然采用QPS/美元来衡量)。

设计思路
大多数LLM都拥有基本相似的架构,只不过在激活函数、归一化层、残差连接等的选择上略有差异。正因为这样的相似性Vidur只需要对所有模型中共有的少量计算运算符进行建模。
批处理运算的场景下,每个输入请求会导致与不同数量的KV-Cache和查询令牌相关,因此分析每个可能的组合来预测建模运行时间是不可取的。而分析注意力内核运行需要对每个请求进行历史重建,有考虑到其解码期间的操作很大程度上都是和内存相关。因此作者认为对KV-Cache的访问总量进行建模即可。
每个模型并行配置都有不同的内存、计算和网络通信特性,Vidur结合有关 LLM并行策略的领域知识,可以在单个GPU上执行最少的分析来模拟各种并行化方案。在分析阶段,Vidur会根据模型的标准化声明自动识别每个算子的张量分片配置。

架构概览
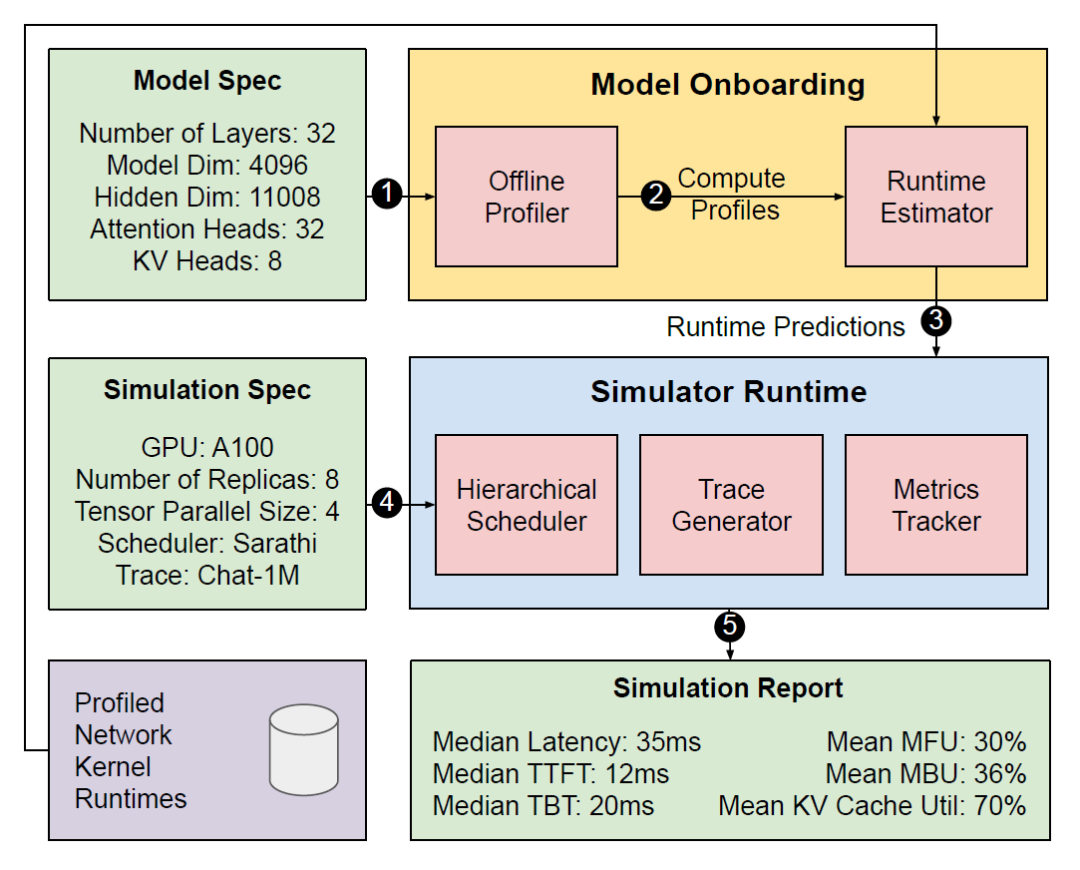
整个架构分为两个阶段:Model onboarding phase和Simulator runtime。
Model onboarding phase:首先输入模型申明,此时分析器将收集已识别运算符的特征并将其提供给运行时评估器。分析的运算符有如下种类:
-
Token-level Operators:令牌级运算符有两大类:矩阵乘法和简单的逐点应用或归约运算,例如加法、标准化和激活函数。根据等待模拟的模型规范,Vidur根据模型规范,列举所有不同的张量并行分片配置并逐一分析每个组合。这种方法允许在单个GPU上获取不同并行配置进行分析,这个过程采用标准 PyTorch内核来分析这些操作,并使用CUPTI (cup) 测量它们的性能
-
Sequence-level Operators:批处理中的序列级运算符,例如注意力机制内核对上下文长度很敏感。这里主要利用针对KV-Cache的访问分析来模拟
-
Communication Operators:通讯操作一般有三种LLM推理的通讯操作,即 all-reduce、all-gather(用于张量并行)和 send-recv(用于管道并行)。这些操作不依赖于特定于模型的特征,因此以与模型无关的方式针对不同的拓扑提前独立地分析这些内核。
为了最大限度地减少添加新模型的成本,在分析阶段的指导原则是收集最少的数据。然后通过仿真训练小规模的机器模型,针对后续仿真过程中会涉及计算操作符的参数进行预测。通过这些数据会被依靠计算操作符为维度建表进行后续的模拟查找。
Simulator runtime:一旦模型上线,用户就可以使用各种调度策略和并行策略在Vidur-Bench支持的各种工作负载中执行模拟。Vidur-Bench是用于LLM推理系统性能评估的基准套件,包括对各种工作负载模式、调度、批处理和路由策略以及服务框架的即插即用支持。

Vidur目前支持五种批处理策略模拟FasterTransformers (fas), Orca (Yu et al., 2022), Sarathi-Serve (Agrawal et al., 2024), vLLM (Kwon et al., 2023)和LightLLM (lig, 2023).
最后一起来看看起飞的命令:

















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









