








大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于构建生产级别架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。
卷积神经网络目前在不同的计算机视觉图像识别任务中处于领先地位。而Transformer模型已成为自然语言处理 (NLP) 中的翘楚。GPT-4o,Gemini和Llama3都是基于Transformer架构的大语言模型,主要都是依托于Transformer架构中的注意力机制。
Vision Transformers (ViT) 最近成为卷积神经网络 (CNN) 的有力替代品。在计算效率和准确性方面,ViT模型的表现几乎比目前最先进的CNN高出 4 倍。

Vision Transformer
Vision Transformer (ViT) 是一种突破性的神经网络架构,它重新构想了我们处理和理解图像的方式。Vision Transformer (ViT) 模型于 2021 年在 ICLR 2021 上发表的一篇会议研究论文“An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale”中引入。
受Transformers 在自然语言处理中成功的启发,ViT 通过将图像划分为更小的块并利用自注意力机制,引入了一种分析图像的新方法。这使模型能够捕获图像中的局部和全局关系,从而在各种计算机视觉任务中取得令人印象深刻的性能。
我们表明,这种对 CNN 的依赖是不必要的,直接应用于图像块序列的纯 Transformer可以在图像分类任务中表现得非常好。当对大量数据进行预训练并转移到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB 等)时,Vision Transformer (ViT) 与最先进的卷积网络相比取得了出色的结果,同时训练所需的计算资源却少得多。
虽然 Transformer 架构已成为涉及自然语言处理 (NLP)的任务的标配,但其与计算机视觉 (CV)相关的用例仍然很少。在许多计算机视觉任务中,注意力机制要么与卷积神经网络(CNN) 结合使用,要么用于替代卷积网络的某些方面。流行的图像识别算法包括ResNet、VGG、YOLOv3、YOLOv7或YOLOv8以及Segment Anything (SAM)。
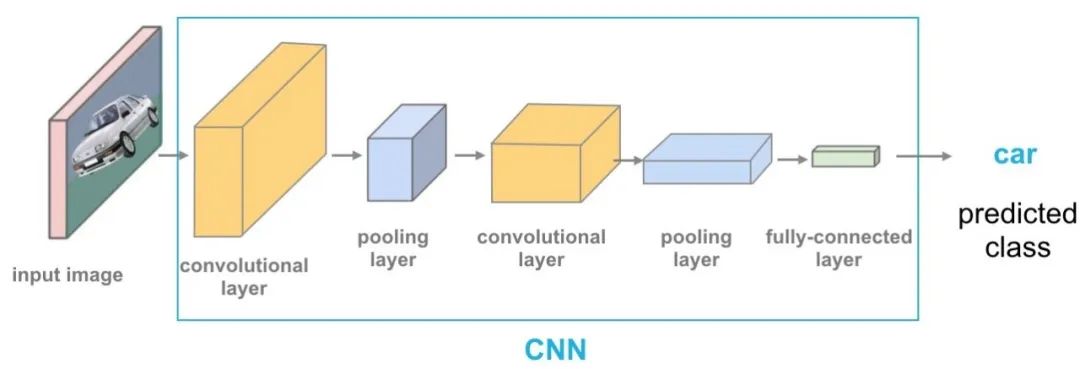
传统的CNN架构
ViT最近在图像分类、对象检测和语义图像分割等多个计算机视觉应用的基准测试中取得了极具竞争力的性能。CSWin Transformer已经超越了 Swin Transformer等先前最先进的方法。
在基准测试任务中,CSWIN 取得了优异的性能,包括在 ImageNet-1K上 85.4%的Top-1准确率、在COCO检测任务上53.9 box AP and 46.4 masks AP,以及在ADE20K语义分割任务上52.2 mIOU。
ViT与卷积神经网络 (CNN) 在的关键不同点在于:
-
输入表示:CNN直接处理原始像素值,但ViT将输入图像分成多个块(patch)并将其转换为Token。
-
处理机制:CNN使用卷积层和池化层的堆叠来捕获不同空间尺度的特征。ViT主要是采用自注意力机制来考虑所有块(patch)之间的关系。
-
全局把控:ViT本质上通过自我注意力来捕捉全局背景,有助于识别远距离Patch之间的关系。CNN依靠池化层来获取粗略的全局信息。
-
数据依赖:CNN通常需要大量标记数据进行训练,而ViT可以从对大数据集进行预训练然后对特定任务进行微调。

DETR
2020年5月的DETR是一种最先进的深度学习框架,利用Transformer网络进行端到端对象检测。DETR背后的关键思想是将目标检测视为预测问题。DETR不单独预测图像中对象的边界框和类标签,而是将对象检测视为二分匹配问题,它同时预测固定数量的物体及其位置。然后使用Hungarian Algorithm将这些预测与地面真实物体进行匹配进行损失计算。

对于一张图像,DETR首先用预训练的CNN网络(例如ResNet50)提取图像的特征,再把由CNN网络得到的多通道特征图转化为Transformer接收的Token序列。输入序列的每个Token都会带上位置编码。

上述得到的Token序列先进入encoder模块,encoder模块主要通过自注意力机制进一步学习图像的特征。Transformer具有强大的特征提取能力,在encoder中每个token可以学习到其和所有token的相关性。

可以说经过encoder的每个token注意到了图像的全局信息。上图展现某个token序列的注意力地图,其中黄色代表高权重,蓝色代表低权重。通过观察到,encoder还是学习到了图像中各个实例的大致分割。
DETR输出的内容是固定的,假设为M个槽口。它是Decoder输出再接FFN网络进行固定的集合预测。
每个槽口由两个组件组成:
-
一个边界框拥有的坐标来标识边界框。
-
一个类别(例如大象,但也可以是空的)
|
|
|
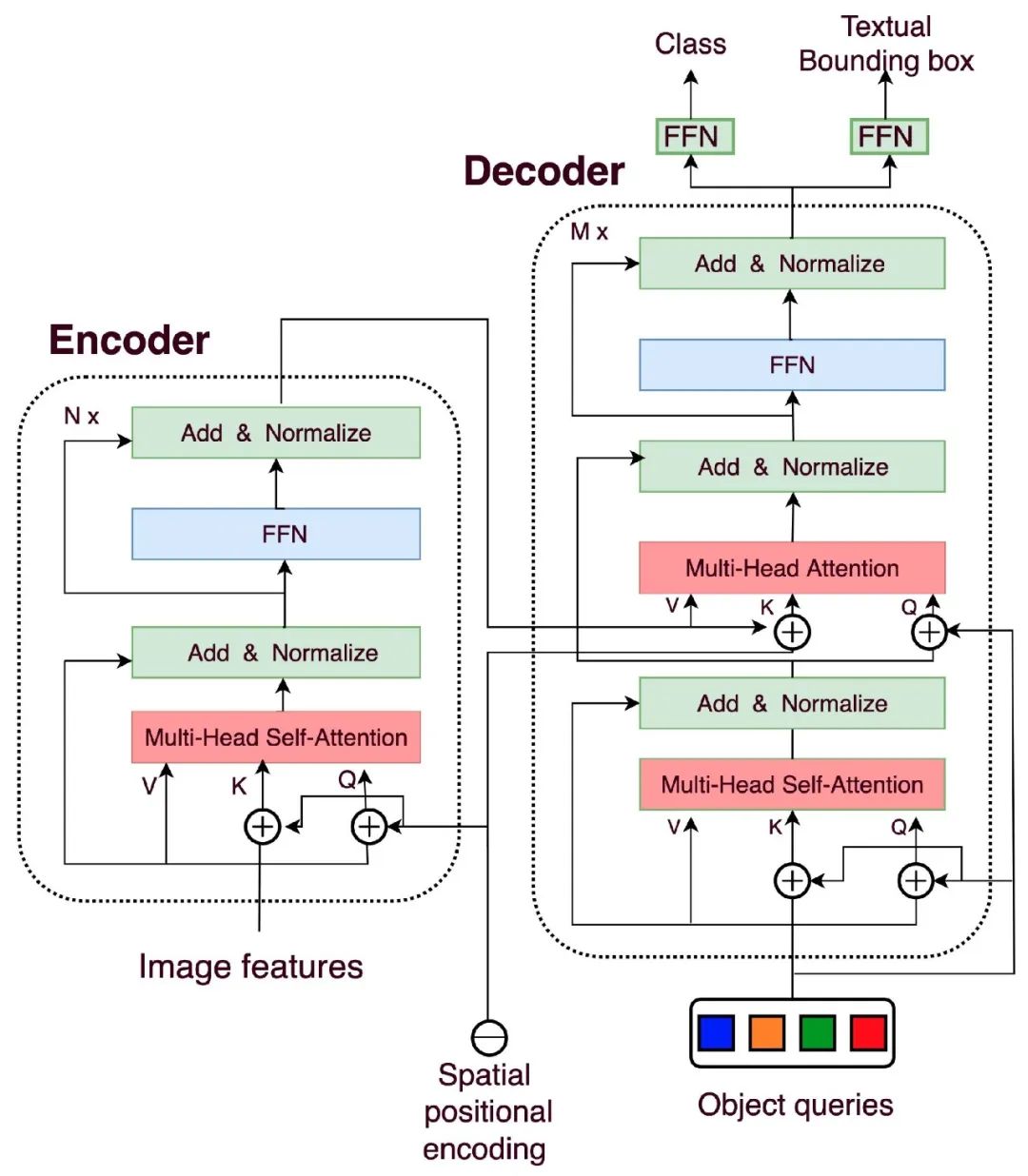

在DETR中,注意到蓝色,橙色,绿色和红色的方块,它们是Object Queries(对象查询)。这些Query是固定数量的在训练过程中学习到的向量。这些向量没有先验的空间信息,即它们最初不包含任何位置信息。相反,它们通过与输入图像特征和位置编码进行交互来学习空间信息和语义信息。这些查询向量在训练过程中通过反向传播逐步学习到关于目标对象的位置和类别的信息。
初始化时,Object Queries是N个固定长度的可学习向量(通常为256维)。N是超参数,预设定的检测框数量。
DETR把目标检测做成了一个集合预测的问题,并利用匈牙利匹配算法来解决decoder输出的对象和真实对象之间的匹配问题,进而计算结果差异以便更新参数。下图展示了两次训练步骤中,不同参数对应的物体会动态变化,因此损失函数的设计就尤为重要。

DETR是首个将Transformer框架用于目标检测任务的模型。其将目标检测视作一个集合预测问题。近年来涌现了许多对于DETR模型的改进工作,如Deformable-DETR、DAB-DETR、DN-DETR等,使得DETR类模型的效率和性能不断提高。2023年4月的论文“DETRS Beat YoLos on Real-time Object Detection”中提出的RT-DETR模型,其性能超过了YoLov8,进一步展现了DETR类模型在目标检测任务上的潜力和优势。















 3217
3217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









