









前言
最近萝卜快跑成为具有争议的热点,小编认为这个时候各地将无人驾驶提速也是无奈之举,个中原因请自行揣摩。无人驾驶技术现在在很多的闭环场景已经在运用。真正的端对端技术,目前FSD算是一面大旗。毕竟这需要大量真实数据和海量算力。然而资源很贵,毕竟现在连LLM都还没有找到真正赚钱的商业模式。
在开放式的道路中无人驾驶最大的问题还是在安全和效率之间的博弈。因此真的要干扰和破坏萝卜快跑,其实可以在游戏规则下,采用…………(自行脑补N种)的方法让其瘫痪,毕竟人的智慧是无穷无尽。<坏笑!>本系列就带着读者轻松读懂无人驾驶。
经典的模块化自动驾驶系统通常由感知、预测、规划和控制组成,基于这个框架更易于解释,并且可以更快地迭代以修复现场测试问题。直到 2023年,它在下游组件中的影响力日渐衰弱,因为AI视觉感知领域迅速崛起,比如BEV已被部署在量产车辆中。
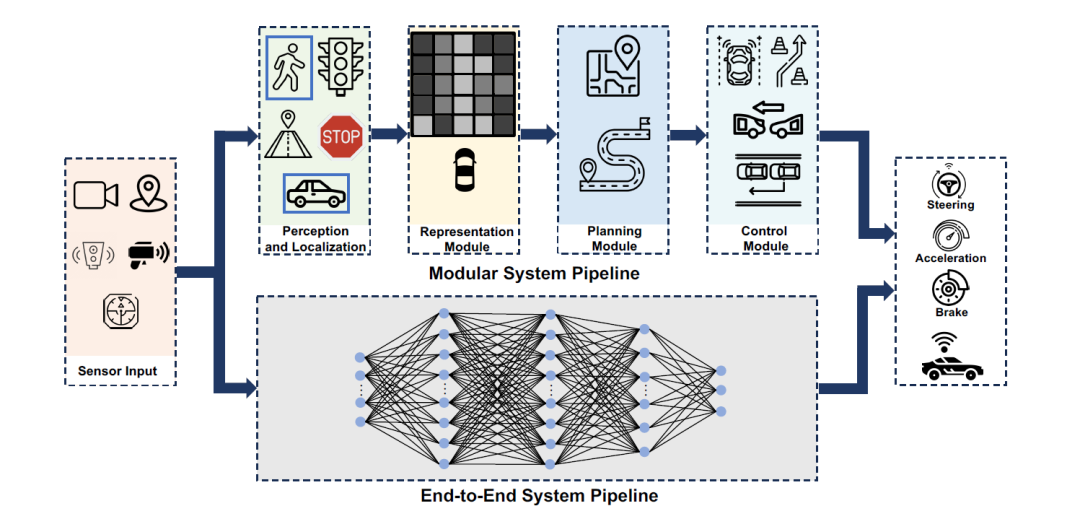
随着时间的推移,下游模块在数据驱动下可以通过不同的接口集成,看(Vision)-说(Language)-动手(Action)的VLA模型在处理复杂的机器人任务(RT-2、TeslaBot和1X)和自动驾驶(GAIA-1、DriveVLM,以及工业界的Wayve AI、特斯拉FSD)方面显示出巨大的潜力。这样实现一刀流,从感知直接通达规划,中间可以节省无数的判断代码。上图的下半部分就展示了利用神经网络的一刀流。

运动规划
经典的运动规划大致由全局路线规划、行为规划和局部轨迹规划组成。
-
全局路线规划提供了地图上从起点到终点的道路级路径。
-
行为规划决定了未来几秒内的驾驶动作类型,例如汽车跟随、轻推、侧向超车、让行和超车。
-
局部行为规划模块中确定的行为类型,而局部轨迹规划生成短期轨迹。
行为规划和轨迹生成可以明确地协同工作。行为规划在1-5Hz,轨迹规划在10-20Hz。这是个超参数,不同的场景需要精校。行为规划和轨迹规划可以合并,也可以分模块迭代交互。
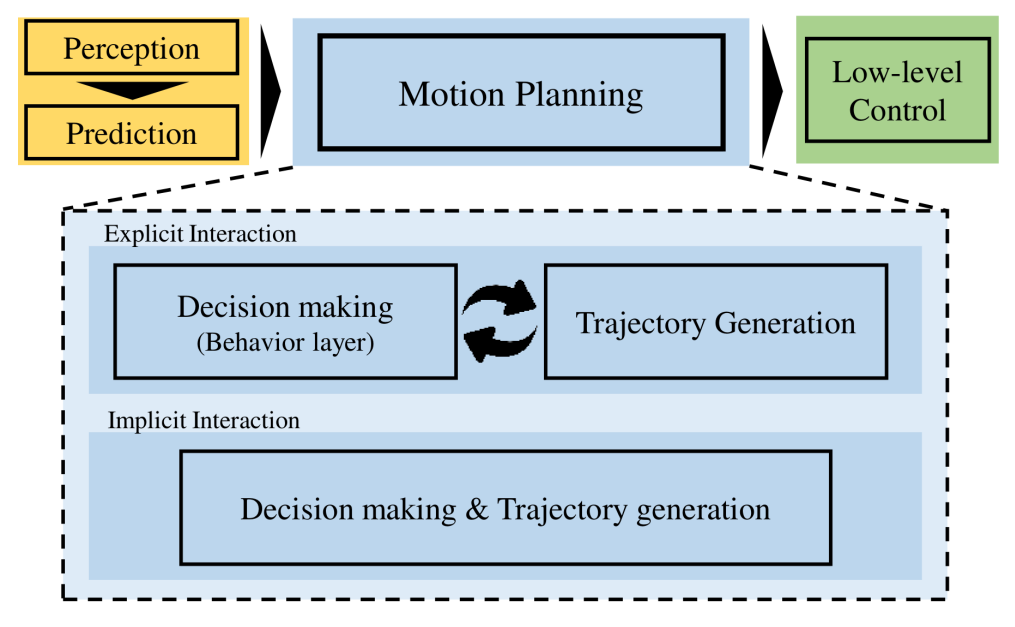
Motion Planning(运动规划):它接受语义动作,并在规划范围的持续时间内生成平滑、可行的轨迹航点,以便控制执行。
Behavior Planning(行为规划):它可产生高级语义动作,例如变道、刹车等,一般生成粗略的轨迹。
Trajectory Planning(轨迹规划):运动规划的另一个术语。
就在上个月2024年6月份一篇利用流体动力学实现自动驾驶汽车通用的运动规划的论文提出了一种全新的办法。
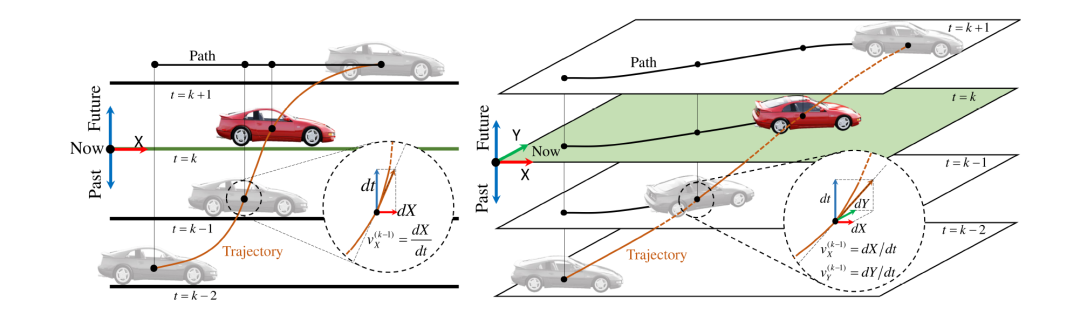
首先上图为汽车在一维直线和二维平面上移动的时空轨迹,垂直轴代表时间。从一维的图谱可以直观地看到,车辆在每个时间步长的速度是由时空轨迹的梯度给出的。
这篇论文是将决策与轨迹生成相结合的方法可以解决运动规划问题,包括罕见的不可预见的情况。例如,数据驱动的方法可以揭示驾驶场景中各种元素之间的复杂关系,例如交通法规、驾驶区域、周围车辆 (SV) 的位置/速度以及电动汽车所需的操纵或速度曲线。只要可用的训练数据足够,数据驱动的方法可以应对各种驾驶情况和ODD。
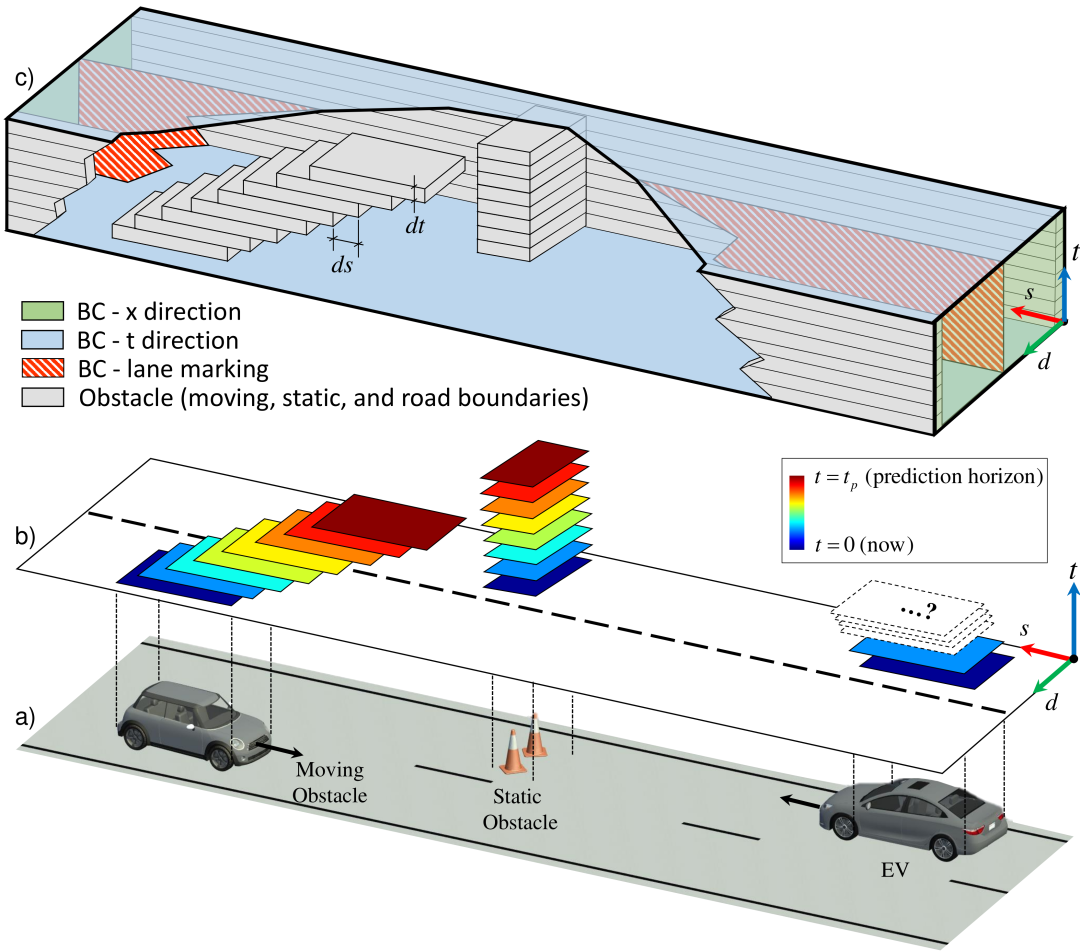
上图为具体场景,此时将汽车预测的运行域看成3D空间,基于受限域流体流动仿真理论。通过构建上下文(包括道路边界等多种语义元素)的通用性,使用格子玻尔兹曼方法(LBM)在低计算需求下通过并行计算模拟流体流动运动的计算效率。
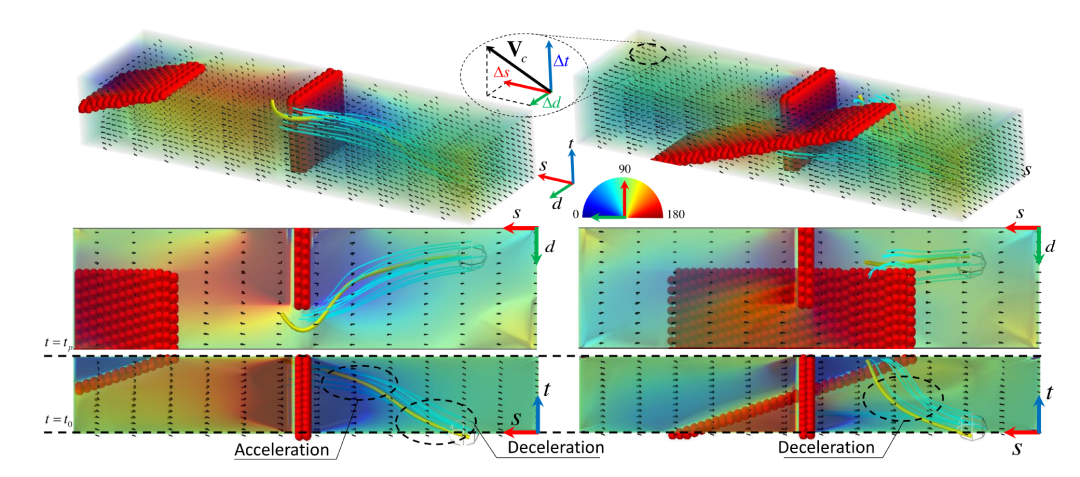
最后选择优化行驶质量、效率和安全性的轨迹来计算即将到来的控制信号,即油门/制动器和转向角。通过在高速公路行驶、匝道合流和交叉路口场景下的仿真,证明该方法的性能优于传统的基于模型预测控制的运动规划方案。

Frenet vs 笛卡尔
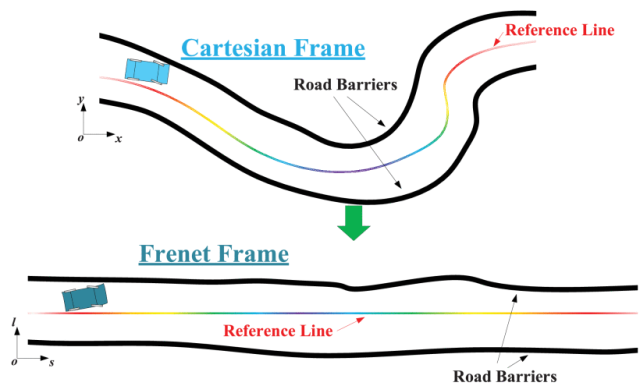
Frenet框架,也称为曲线框架,已被广泛用于对道路轨迹规划任务进行建模。在现实世界的笛卡尔坐标系中,形状不规则的道路在弗雷特坐标系中被转换为笔直的道路。使用 Frenet 框架的一个明显好处是,任何道路都可以标准化为具有左右边界的直线隧道。通过这种方式,将轨迹规划问题中的非线性碰撞避免约束转化为线性隧道内约束。除此之外,原始耦合的运动学约束在纵向和横向维度上被解耦为独立的多项式。基于Frenet的方法能够快速求解轨迹规划方案(二次元规划 QP) 。
Frenet 坐标系需要一个干净、结构化的道路图和低曲率车道。在实践中,它更适合曲率较小的结构化道路,例如高速公路或城市高速公路。然而,随着参考线曲率的增加,Frenet 坐标系的问题会被放大,因此在具有高曲率的结构化道路上应谨慎使用它。对于无结构道路,例如港口、矿区、停车场或没有准则的十字路口,建议使用更灵活的笛卡尔坐标系。笛卡尔系统更适合这些环境,可以更有效地处理更高的曲率和结构较少场景。















 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









