








--->更多内容,请移步“鲁班秘笈”!!<---
最近的Pytorch 2.4 推出AI任务加速,提供对Intel GPU的支持。为了进一步加速 AI任务,PyTorch 2.4现在为Intel数据中心GPU Max系列提供支持,该系列将Intel GPU和SYCL软件堆栈集成到标准PyTorch堆栈中。<下图为各个组件被引入到pytorch的各个版本信息。小编建议快速浏览,第二章节再仔细理解这些组件的内涵!>
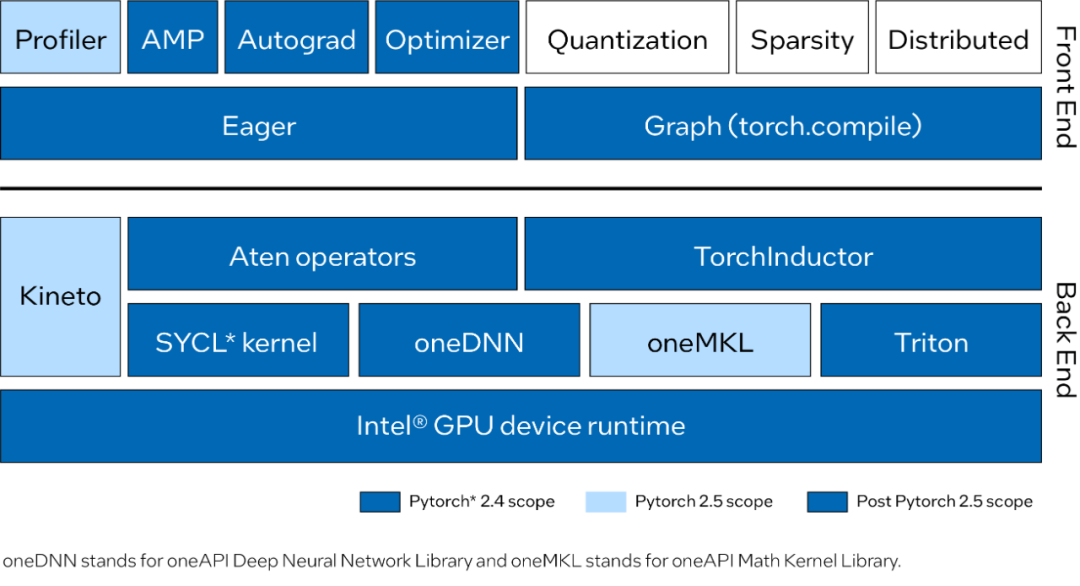
借助Intel GPU支持,读者可以拥有更多GPU选择,并可以使用相同的前后端 GPU编程模型。现在可以在Intel GPU上部署和操作工作负载&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









