







大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在阅读过程中有些知识点存在盲区,可以回到如何优雅的谈论大模型重新阅读。另外斯坦福2024人工智能报告解读为通识性读物。若对于如果构建生成级别的AI架构则可以关注AI架构设计。技术宅麻烦死磕LLM背后的基础模型。
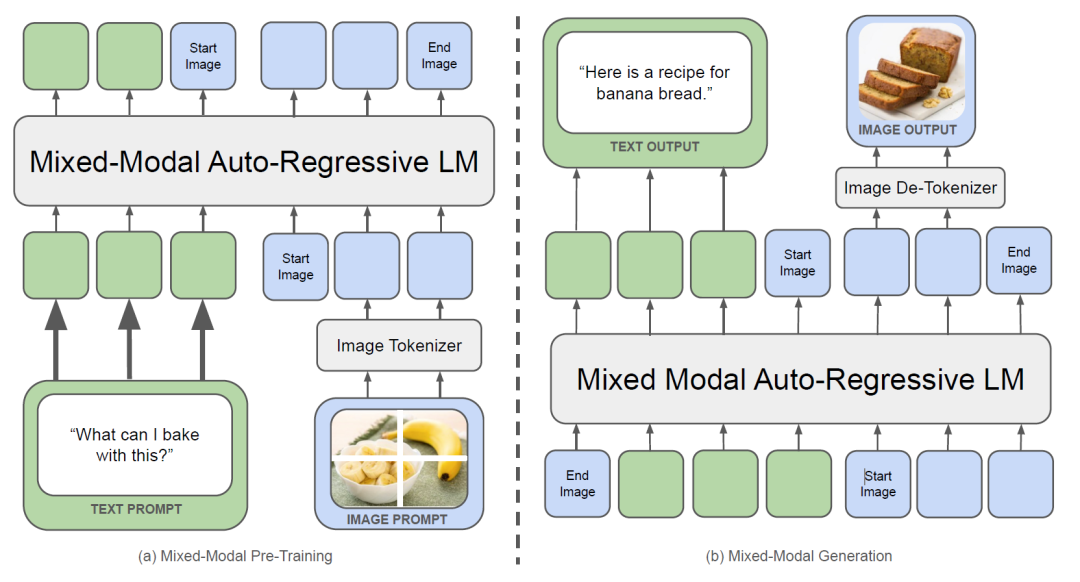
尽管最近的多模态基础模型被广泛使用,但它们倾向于分离各种模态,通常为每种模态采用特定的编码器或解码器。这种方法限制了他们有效融合跨模态信息,也限制了生成包含图像和文本混排的多模态文档的能力。
Meta研究人员提出了Chameleon,这是一种混合模态的基础模型,有助于生成和推理文本和图像交叉的场景,从而实现全面的多模式建模。与传统模型不同Chameleon采用统一的架构,通过将图像标记为类似于文本的方式,平等地对待这两种模式。这种方法被称为早期融合,允许跨模式无缝推理,这种架构需要调整Transformer的架构和FineTuning策略。
整体的效果如下:
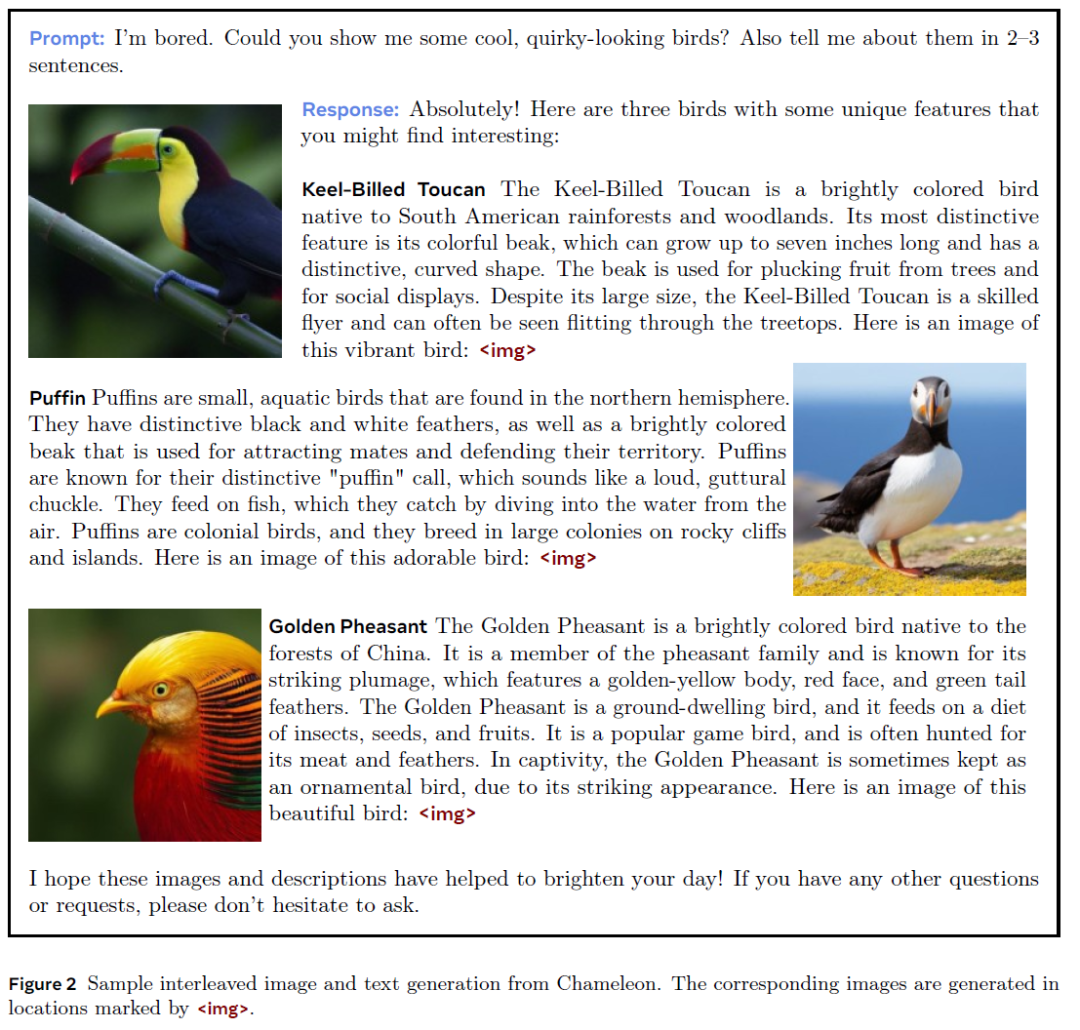

主要看点
Tokenizer:Chameleon的重大突破之一是Token化技术,新Tokenizer(标记器)将图像转换为Token序列,例如512*512格式的图像被分割为1024个离散Token序列。至于文本模态,它采用BPE算法,增加文本和图像的词汇表扩充到65536个。
Training:在包含文本和图像数据的广泛数据集上进行两个阶段的训练。第一阶段涉及大规模数据集的训练,第二阶段包含更高质量的数据集进行微调。
围绕稳定性调整架构:Chameleon的扩展性到来了稳定性的挑战,特别是当模型扩展到超过80 亿个参数和1万亿个训练Token的时候。它针对架构做了一些调整,在注意力机制层运用了Query-Key Normalization确保Norm的稳定性。同时受到Swin Transformer的启发,通过调整Layer Norm的放置位置。这样的重排稳定Transformer块中Norm增长。
优化策略:为了进一步增强稳定性,Chameleon采用了多种优化技术,AdamW优化器,β1 =0.9、β2 =0.95, ϵ = 10−5。同时采用z-loss的正则表达式,通过正则化分区函数,减轻最终softmax的logit漂移。

预训练回放
研究人员基于《Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors》 的模型训练了一个新的图像标记器(Image Tokenization。它将512 × 512图像从大小为8192的codebook(等同于自然语言的词汇表)编码为1024长度的离散Token序列。
训练这个Tokenizer采用的是许可图像,考虑到生成人脸的重要性,在预训练期间将人脸图像的百分比增加了1倍。分词器的一个核心弱点是这些图像有大量的文本,在训练的时候涉及到繁重的OCR任务,因此也约束了模型的表现。
预训练阶段划分为两个单独的阶段。第一阶段占训练的前80%,第二阶段占训练的后20%。对于所有文本到图像的训练对,训练中50%的概率将图像放在文字之前。
第一阶段预训练使用由以下超大规模完全无监督数据集组成的混合数据。
-
使用各种文本数据集,包括用于训练LLaMa-2和CodeLLaMa的预训练数据的组合,总计2.9万亿纯文本Token。
-
文本-图像数据是公开数据源和许可数据的组合,然后调整图像大小并居中裁剪为512 × 512图像以进行标记化。总共包含14亿个文本-图像对,对应1.5万亿个文本-图像token。
-
文本/图像交错:从公开的网络来源获取数据,不包括来自 Meta 产品或服务的数据,总共4000亿个文本和图像数据交错的Token。
第二阶段预训练将第一阶段数据的权重降低了 50%,并混合更高质量的数据集,同时保持图像文本Token的相似比例。

模型架构
架构很大程度上遵循LLaMa-2。归一化采用了RMSNorm,同时采用了SwiGLU激活函数和旋转位置嵌入 (RoPE)。
当将Chameleon模型扩展到8B参数和1T令牌以上时,保持稳定的训练是一项挑战,不稳定通常只在训练的后期才会出现。 所以研究人员调整了架构和优化方法来实现稳定性。由于训练中后期Norm增长缓慢,标准LLaMa架构表现出分散度。主要的原因还是在于跨模态共享模型的所有权重,所以每种模态都会通过稍微增加Norm来尝试与其他模态“竞争”。一旦超出bf16的有效表示范围,它就会表现出分散。
为了通过控制Norm的增长而稳定Chameleon-7B,除了引入QK-Norm 之外,还需要在注意力层和前馈层之后引入dropout能力。
|
| 左图为LLAMA2的Transformer块,它先是进行RMSNorm之后才是Attention,同样的也是先进行RMSNorm才进行MLP。 |
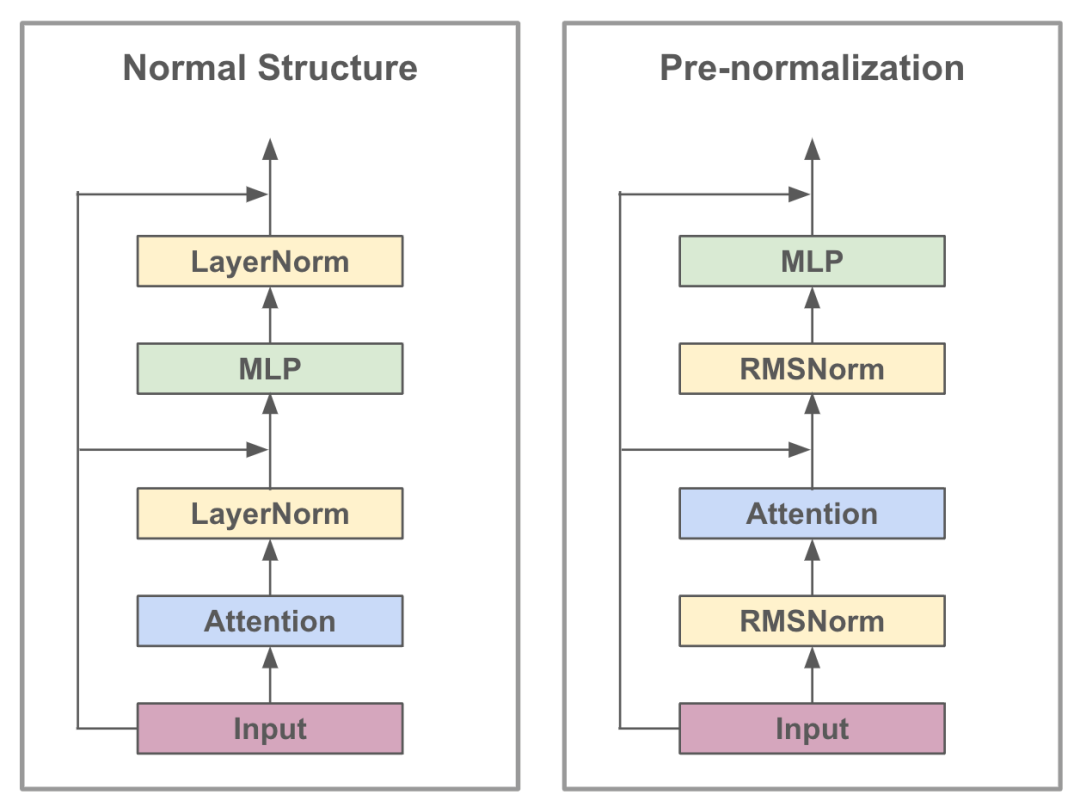
按照上图,原来的架构中(h为中间的输出):
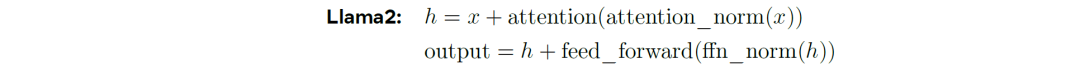
然后为了稳定Chameleon-34B,需要对LLAMA2的Norm进行额外的重排序。通过分析发现,x先是attention,然后在norm。在ffn层也是先FFN在norm,<感觉又回到了传统的Tranformer??!!>。
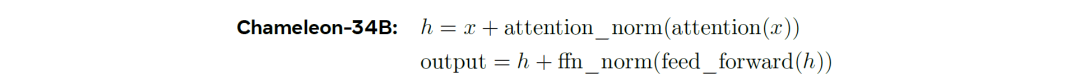
同时也引入了Swin transformer的归一策略,这个策略的好处是它限制了前馈模块的Norm增长,而因为SwiGLU激活函数的多元性质,是一个潜在的问题。

模型评估
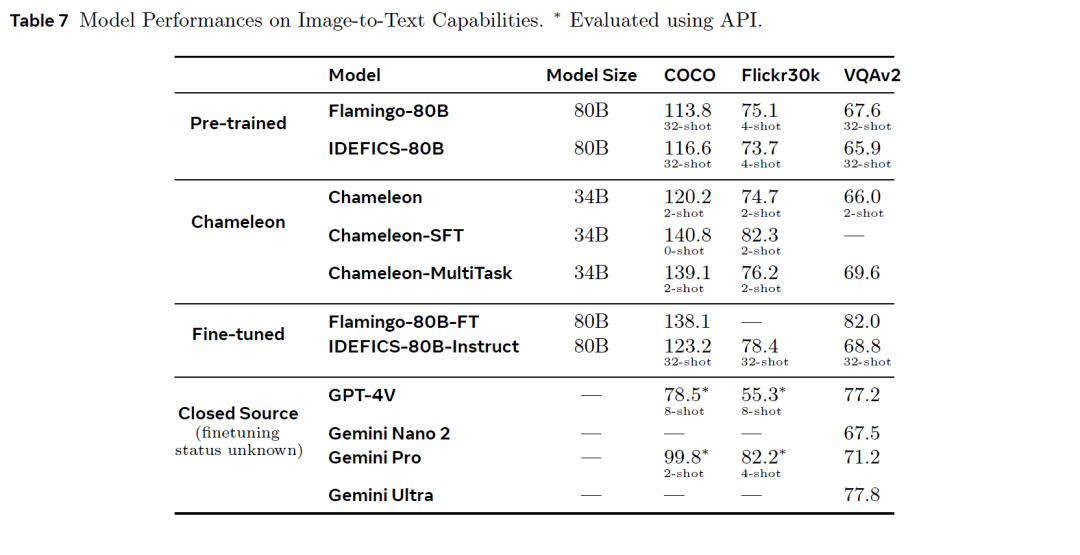
Chameleon 在一系列任务中展示了令人印象深刻的能力。该模型在COCO 和Flickr 30k数据集上的图像字幕以及VQAv2基准的视觉问答方面表现出强大的性能。在COCO上优于 Flamingo-80B和IDEFICS-80B。在VQAv2上与Flamingo-80B-FT和IDEFICS-80B-Instruct等其他微调模型相比很有竞争力。
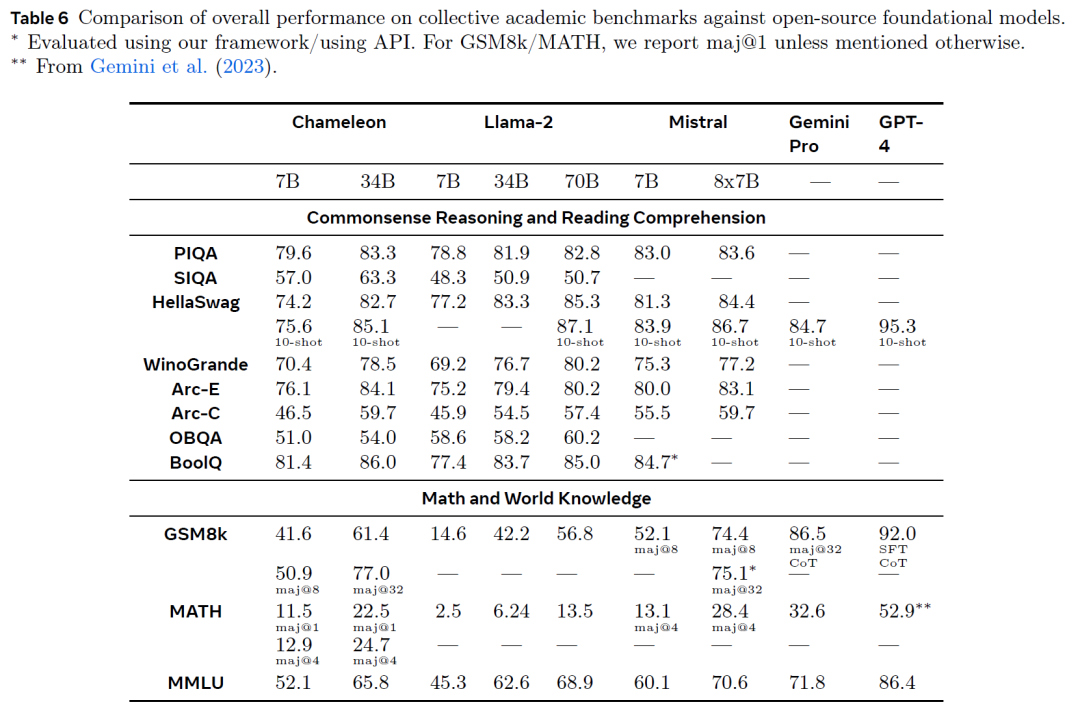
至于在纯文本任务上,Chameleon在PIQA、SIQA 和HellaSwag等常识推理和阅读理解基准测试中表现出色。对于世界知识和数学问题,它也显示出强劲的结果,尤其是在GSM8k和MATH基准测试上,可与LLaMa-2 和 Mixtral 8x7B 等模型相媲美。
Chameleon架构和训练策略提供了坚实的基础,在其他的领域还需要进一步的探索:例如在微调层面,更有针对性的任务微调可以提高特定下游任务的性能。同时它可以扩展到其他模态,合并其他数据类型(例如音频或视频)可以使模型更加通用。

















 72
72

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









