







--->更多内容,请移步“鲁班秘笈”!!<---
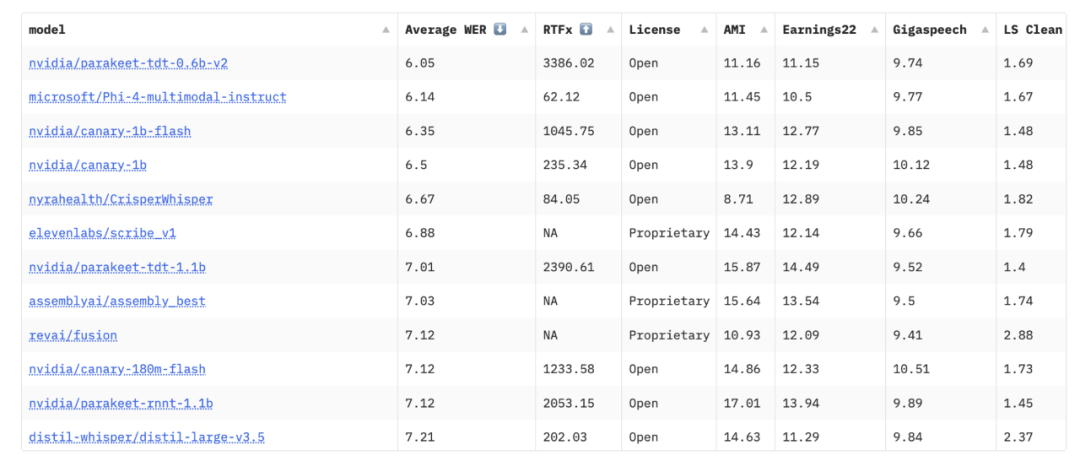
2025年5月,NVIDIA重磅发布其全新一代自动语音识别(ASR)模型 ——Parakeet TDT 0.6B-v2。该模型具备 0.6B参数,采用CC-BY-4.0商用开源许可协议,并以 实时因子(RTF)达3386 的惊人速度刷新行业纪录,标志着语音AI进入一个全新的高性能、低延迟时代。

核心优势
强大模型规模:600M参数的编码-解码结构,结合FastConformer与Transducer Decoder Transformer (TDT) 架构。
-
极速处理能力:在NVIDIA硬件上,能在1秒内转录60分钟音频,速度超过多数ASR模型50倍以上。
-
领先的转录准确率:在Hugging Face的Open ASR排行榜上以6.05%的词错误率(WER) 位居开源模型第一。
-
商用许可友好:采用CC-BY-4.0许可,允许在商业项目中自由使用与修改。
Parakeet 的能力远不止于此。它不仅能精准地还原语音内容,还支持包括标点恢复、大小写格式化、数字规范化等在内的多项语义层面的增强处理,使得输出文本更符合自然语言的表达习惯,便于阅读和进一步的自然语言处理。在众多实际场景中,如法律记录、医疗语音转写、会议纪要等,这些细节功能往往决定了模型的实际可用性。此外,Parakeet 还创新性地支持“歌曲转歌词”的功能,拓展了其在媒体内容处理、音乐平台检索等方面的潜力。

技术特点
Parakeet TDT 0.6B-v2融合了多项前沿优化技术:
-
模型结构:编码器使用FastConformer,解码器为TDT,适合并发处理和大批量推理。
-
推理优化:通过 TensorRT和FP8量化技术实现了极致加速。
-
语音格式增强:内建数字格式化、时间戳标注和标点修复,大幅提升可读性。
-
创新功能:罕见支持“歌曲转歌词”功能,拓展至音乐和媒体应用场景。
-
这一代模型不仅速度快,而且保持高准确性和强泛化能力,在多个公开英语语音识别基准(如 AMI、GigaSpeech、Earnings22、SPGISpeech)中均表现优异,甚至在电话语音、噪声环境下依然保持稳定性能。
Parakeet TDT 0.6B-v2基于Granary的多源语音语料库进行训练,总计约 12万小时的英语音频,其中包括1万小时人工标注数据,11万小时高质量伪标签语音。数据源涵盖LibriSpeech、Common Voice、YouTube-Commons、Librilight等。NVIDIA 计划在2025年Interspeech大会上公开Granary语料库,进一步促进语音AI领域的数据共享与模型复现。
从工程角度看,Parakeet TDT 0.6B-v2对硬件的适配也做得非常出色。虽然在高端GPU上表现最佳,但即使是在低至2GB内存的设备上,也可以加载模型并运行较小规模的任务。这种灵活性使其既适合大型云平台的批量转写需求,也能服务于边缘设备上的实时语音识别。

术语
在理解 Parakeet TDT 0.6B-v2 的技术优势时,可能会遇到一些专业术语。为了方便读者深入了解,简要解释几个核心概念:
FastConformer编码器是一种高效的语音建模架构,它融合了Transformer 的全局注意力机制与卷积网络的局部建模能力,能在保证准确率的同时提升处理长语音的速度和效率。
Transducer Decoder Transformer(TDT)架构则结合了传统Transducer 在流式语音识别中的高效性和Transformer在语言理解中的优势,使模型既能快速响应,又不失上下文的理解能力。
最后,RTF(Real-Time Factor)实时因子 是衡量语音识别速度的一个指标。RTF = 1表示模型刚好可以实时识别音频,而 Parakeet实现的 RTF = 3386,意味着它能以 3386 倍于音频实际长度的速度完成识别,代表了当前开源模型中的极致速度。

















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









